

Contents:
With the growing interest in OCR and Machine Learning, more and more business owners are looking for ways to apply this killing combination to optimize their business processes, and if you are one of them, this article is for you. Having created software solutions since 2009, MobiDev has extensive experience in OCR and ML projects solving a broad range of various business challenges.
In this article, I’ll tell you more about what OCR is, how OCR powered with machine learning is different from the original technology, and how it can be used in your business to solve your needs.
What is OCR and How Does It Work?
Optical character recognition (OCR), also known as text recognition technology, converts any kind of image containing written text into machine-readable text data. OCR allows you to quickly and automatically digitize a document without the need for manual data entry. That’s why OCR is commonly used for intelligent document processing. The output of OCR is further used for electronic document editing, and compact data storage and also forms the basis for cognitive computing, machine translation and text-to-speech technologies.
There are different types of OCR depending on the tasks they solve:
- Intelligent Word Recognition (IWR) is used for the recognition of unconstrained handwritten words instead of recognition of individual characters.
- Intelligent Character Recognition (ICR) is a more advanced form of OCR based on updating algorithms to gather more data about variations in hand-printed characters.
- Optical Word Recognition (OWR) scans typewritten text word by word.
- Optical Mark Recognition (OMR) is used to identify the information that people mark on surveys, tests, etc.
Let’s find out how OCR works. The functioning of the traditional optical character recognition system consists of three stages: image pre-processing, character recognition, post-processing.
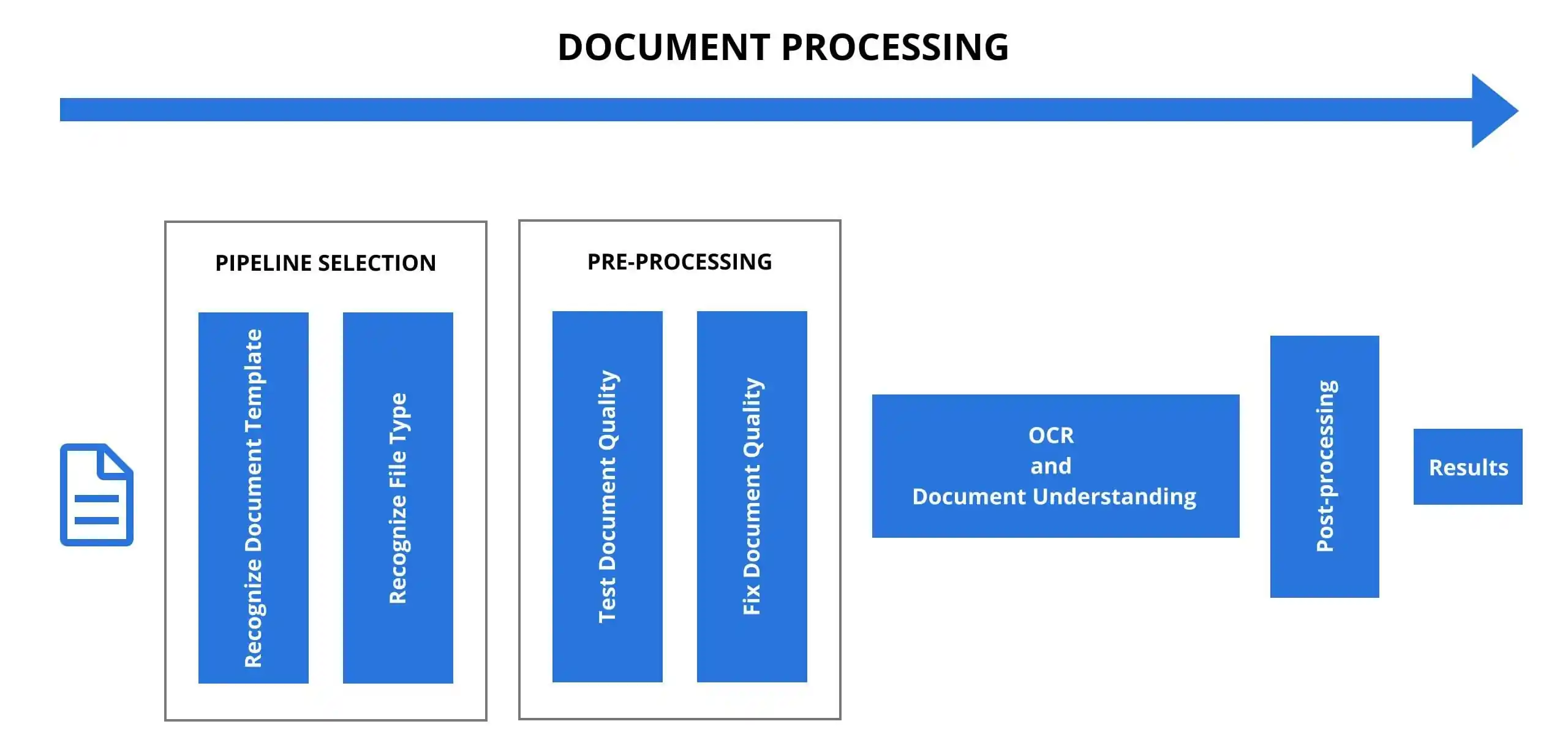
Step 1. Checking the document type & Image pre-processing
The main challenge of text recognition is that each document template has its own set of entities, values, and location of entities in the document. For OCR software to work accurately, it must be able to identify different types of documents and run the correct predefined pipeline based on that. For example, PDF documents may or may not contain a text layer. If the PDF does not contain a text layer, we must process it differently than if it did.
After choosing the right pipeline the image comes to the pre-processing step. This is a preparation step that affects the outcomes. Image pre-processing helps to remove image noise and increase the contrast between the background and text, which will help improve text recognition. At this step, the OCR program converts the document to a black and white version and then analyzes it for the presence of light and dark areas. Light areas are identified as the background, while dark areas are identified as characters to be processed.
Step 2. Character recognition
With the use of feature detection and pattern recognition algorithms a single character is detected. Then, a set of the characters are assembled into words and sentences. Characters are identified using pattern recognition or feature detection algorithms.
- Pattern recognition is a method based on finding matches between the image text and text samples embedded in the system in various fonts and formats. This method works best with typescript and it doesn’t work well when new fonts are encountered that are not included in the system.
- The feature detection algorithm makes it possible to recognize new characters by applying rules regarding character’s individual features. Such features may include the number of slanted lines, intersecting lines, or curves in the comparison symbol.
Most often, OCR programs with feature detection use classifiers based on machine learning or neural networks to process characters. Classifiers are used to compare image features with stored examples in the system and select the closest match. The feature detection algorithm is good for unusual fonts or low-quality images where the font is distorted.
Step 3. Post-processing
Once a symbol is identified, it is converted into a code that can be used by computer systems for further processing. We should mention that the output of any OCR and OCR-related technology/algorithm has a lot of noise and false positives. It makes it difficult to use OCR’s output directly, so we have to:
- Filter out noisy outputs and false positives
- Combine recognized entities with their extracted meaning
- Check for possible mistakes and prevent output to the user if any
Based on statistical data, the system can detect some typical OCR errors, for example, those related to the similarity of characters and words. Thus, at this stage, the system corrects flaws in order to improve the quality of the OCR output.
OCR is a Machine Learning and Computer Vision Task
Optical character recognition is one of the main computer vision tasks. Сomputer vision allows systems to see and interpret real-world objects and recognize texts separating them from complex backgrounds. Early versions of OCR had to be trained with images of each character and could only work with one font at a time. Modern machine learning algorithms make the text recognition process more advanced and provide a higher level of recognition accuracy for most fonts, regardless of input data formats.
Advances in machine learning (ML) have given a new impetus to the development of OCR, significantly increasing the number of its applications. With enough training data, the OCR machine learning algorithm now can be applied to any real-world scenario that requires identification and text transformation. For example, receipts scanning, scanning of printed text with the further conversion of it into synthetic speech, traffic sign recognition, license plate recognition, etc.
The use of modern machine learning algorithms can significantly improve the technology and expand its use cases to more complicated ones. For example, OCR with deep learning allows not only image classification, but image analysis and extraction of more complex data from different objects including hundreds of handwritten fonts or languages.
OCR Business Cases
OCR application in business has numerous scenarios. Since text recognition using machine learning provides greater accuracy than the earlier versions of optical character recognition, this allows business owners to create OCR solutions to address a wider range of business challenges. Modern OCR systems are used in security, banking, insurance, medicine, communications, retail companies, and other industries.
Use cases for OCR technology include checking test answers, real-time translations, recognizing street signs (Google Street View), searching through photos (Dropbox), preparing documents for AI data analytics, and more. Optical character recognition is also widely used by security teams. This technology helps to analyze and process documents such as a driver’s license or ID for verifying a person’s identity. For each case a completely different OCR solution is used. If you want to know which OCR solution is better for your business case, our tech experts are ready to help.
OCR in Financial Services
Financial transactions involve a huge amount of data entry. Manual processing of this data takes a lot of time and effort while digitization of financial documents and extracting the necessary information from them using OCR makes business processes smooth and optimized. As a result, the OCR technology improves customer onboarding and enhances the overall customer experience.
Optical character recognition uses in the banking and financial sector include the following:
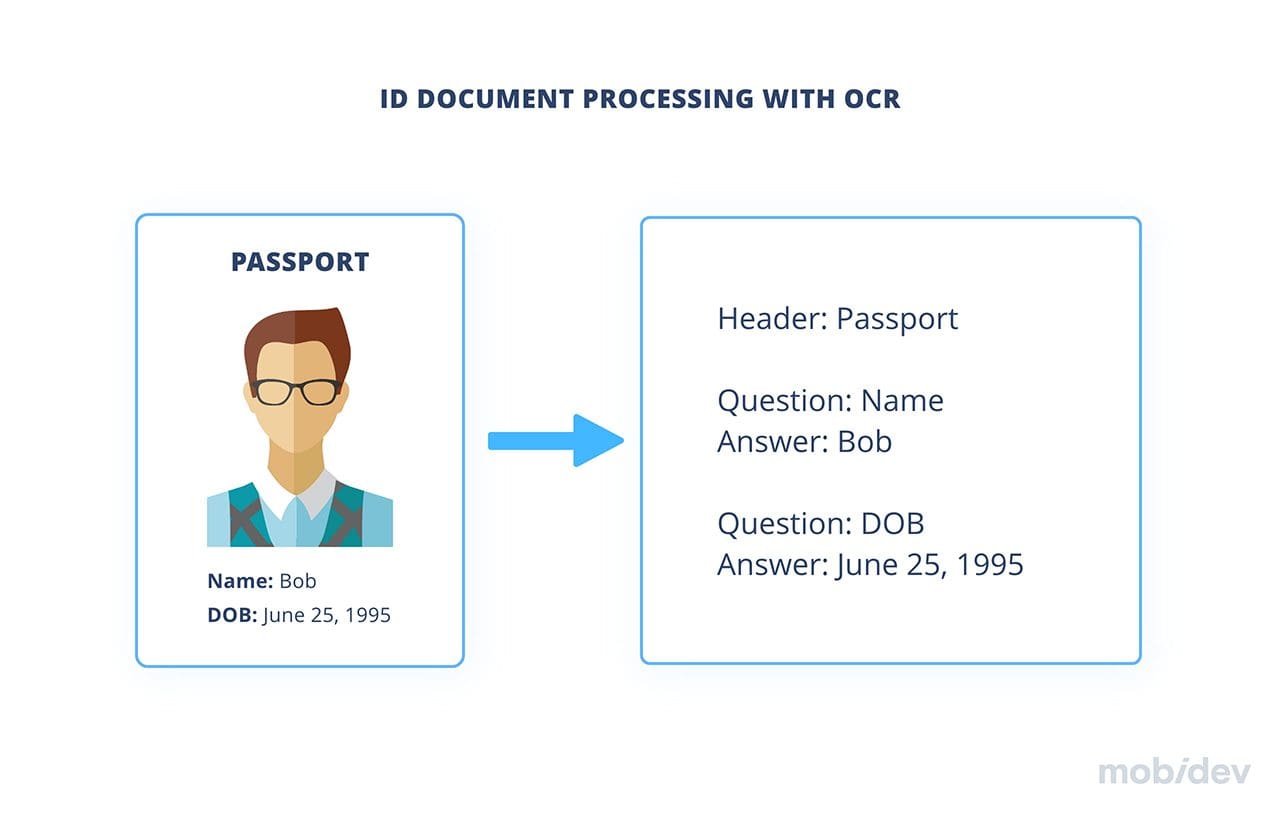
- Client onboarding. Whatever financial transactions you want to perform, whether it be opening an account, withdrawing cash or transferring money, you first need to authenticate to prove your identity. OCR technology provides a fully automated onboarding process consisting of scanning an identity document (e.g. ID, passport or driver’s license), extracting the necessary data using OCR (e.g. name, dates of birth, gender, photo, signature, etc.) and checking it. For example, the OCR engine can inspect in real-time whether the provided signature matches the signature on the identity document.
- Scan to pay feature. Manual entry of payment details does not exclude errors and takes more time than expected. The scan to pay feature uses optical character recognition to instantly capture invoice data and automatically process it. The user only needs a smartphone camera to do this (for example, you may need to take a photo of your credit card).OCR can also act as an extra security feature when making payments. Usually, users store cardholder data in the application desiring not to enter the card number and other details every time. With OCR, all you need is to enable the OCR feature which extracts data in seconds for each new payment and then removes it.
- Receipt recognition. OCR allows automating data extraction from receipts for further accounting, archiving or document analytics. You can find this feature implemented in financial assistant apps with money tracking elements for automated data entry of expenses and expense categories. Expensify is an example of such an application.
The high variability and often low quality of receipts are the main challenges for accurate receipt recognition with OCR. In such a case, the rule-based approach cannot be effective and this is where optical character recognition with deep learning comes in. The deep learning approach to OCR allows the system to learn from the received data and improve. This technology lets training a model to identify regions of interest (RoI) in an image that are highly likely to contain text, ignoring redundant data such as the background. - Loan processing. OCR and machine learning text recognition tools can speed up the processing of loan and mortgage applications by up to 70 percent. Automation of data entry makes the process of reviewing applications and approving or rejecting them much faster and more cost-effective for the company. AI algorithms can parse the required data from the application to determine if it should be approved or rejected based on the financial institution’s rules.
Use cases of OCR in finance are not limited to the above. The technology can be used for processing other financial documents like invoices, contracts, bills, financial reports, etc.
OCR in Healthcare
OСR cases in the healthcare industry are closely related to data management. According to the World Economic Forum, hospitals produce an average of 50 petabytes of data per year. This data includes medical reports, prescription forms, claims, laboratory test results, and medical records. The digitalization of medical documents and the efficient extraction of data from them is a critical aspect of the functioning of a healthcare institution.
By applying optical character recognition technology hospitals can translate papers into a digital format much faster and store them as PDF documents that can be easily searched using keywords. Electronic medical records solve one of the main problems of hospitals, the loss of medical information about patients. Also, OCR allows data to be pulled from certificates or test results and sent to hospital information management systems (HIMS) for integration into patient records thus forming a complete medical history of patients.
Pharmaceutical systems can take advantage of OCR as well. Powered with an OCR module such systems allow you to scan medical prescriptions and import them into software to check the presence of the medicine in pharmacy databases or even use it to control picking robots.
OCR technology is also used to help people with visual impairments. By scanning the text on the image, the OCR system provides the base for using text-to-speech technology. All you have to do is scan the text to get synthetic speech output. For example, the Voice Speech Scanner app uses the smartphone’s camera to capture a photo with text and then reads all of the text back. This is a new level of assistance to people with visual impairments after the technology of deep learning image captioning which provides automatic generation of textual description of an image.
OCR in Retail
Retailers produce many different documents such as packing lists, invoices, purchase orders, receipts, product descriptions, and others. These are huge amounts of information, which, however, are not used properly due to the complex and time-consuming processing.
Using OCR with machine learning, retailers can experience the rapid development of internal business processes and improve the customer experience by making the most of the existing data. For example, merchants can extract valuable insights from purchase order analytics to create more effective marketing campaigns, promotions, and manage pricing better. By converting invoices and receipts into digital format and incorporating them into accounting systems, retail companies get a chance to automate their accounting processes.
Implementing OCR is a great way to handle the large workloads of retail workers. With automatic data entry and data extraction, employees are left with only manual verification to achieve optimal results.
Cases of using OCR in retail are not limited to the above. The text recognition feature can address some specific challenges of retail companies. For example, the technology can be helpful for wine merchants who offer a wide range of products. With OCR-based wine label recognition, users can take a photo of a wine label and get product information such as reviews, description, etc. to help them make the right choice.
OCR in Security and Law Enforcement
Almost any industry can take advantage of OCR as part of its security strategy. Using OCR powered by machine learning, companies have a chance to build advanced user authentication and verification systems. Usually, manual comparison documents with provided personal info and a selfie are used to verify the authenticity of the identifier presented by the user. The OCR model eliminates these manual efforts by scanning ID cards, passports or driver’s licenses and checking their authenticity, comparing them with the info in the database.
In this case, the OCR engine must first recognize the document type. For example, if a user chooses to authenticate with a driver’s license, the document they upload to the system must conform to that document format. Then the system should analyze and process uploaded user documents to get relevant data.
Since documents of the same type may have a different format depending on the country or state, the system must be able to find and extract the necessary data from all variations. Using deep learning algorithms helps the OCR system understand the relative positional relationship among different text blocks and combine pairs of semantically connected blocks of text to find relevant data such as name, date of birth, etc.
It is also worth mentioning that secure authentication OCR software should have features to prevent spoofing attempts when parsing documents. Anti-spoofing techniques will help the system detect fake ID scans and other fraudulent attempts.
Optical character recognition technology is also widely used for automatic number plate recognition (ANPR). This technology is very helpful for cameras that enforce traffic laws. ANPR is also used for electronic toll collection on toll roads, car park management, bus lane enforcement, and traffic management. In general, systems based on OCR assistance ensure road safety in most countries of the world.
For example, in the USA, all police departments use some form of ANPR. According to the California State Auditor’s 2020 report, the Los Angeles Police Department (LAPD) alone has amassed over 320 million license plate scans. In the UK, automatic number-plate recognition is used to record the movement of vehicles from nearly 8,000 cameras that capture millions of records daily. This data helps deter and stop crime, including organized crime groups and terrorists.
Hardware for OCR
A high-quality text recognition system is a well-coordinated work of software and hardware. The hardware required for OCR is a special scanner or just a camera on your phone. The hardware is used for taking an image of a text on a paper sheet, and the software does the rest of the work by recognizing/extracting a text out of an image. Hardware plays the role of the eyes (receptors) of software. And software plays the role of the brain that processes the eye’s information and extracts meaning from the perceived data.
Modern OCR solutions can turn a smartphone or PC camera into a full-fledged document scanner. Most current OCR applications upload images to a server for recognition and then return the recognition output to the client. Many iOS and Android app creators develop their own intelligent camera interfaces that detect document borders, correct perspective, and optimize image quality. The output of mobile OCR depends primarily on the mobile device’s camera and shooting conditions.
Out-of-the-box Solutions vs Custom OCR Development
When a business owner needs software for optical character recognition, the question arises of which solution is better to use: ready-made or customized solution. There are many options for OCR systems on the market, but it is important to understand that they are mostly focused on processing standard business processes and may not meet your specific needs. That’s why it’s so important to determine the goals and requirements of your project and then explore the options.
Commercial VS open-source OCR solutions
There are commercial and open-source OCR solutions. Commercial ones are usually provided as a service. GoogleOCR is an example of such software. If you need to quickly implement OCR functionality in your application, then GoogleOCR is a great choice. But it is worth remembering that this solution is paid and requires an Internet connection.
Open-source OCR can be integrated as separate client application cloud services. Such solutions don’t require a direct payment for the service, but involve the cost of maintaining the infrastructure for the functioning of OCR (for example, a microservice). Having a microservice also requires an Internet connection for OCR to work. However, there are also standalone optical character recognition systems that can function without the Internet. In this case, the user device must provide enough computing resources to solve the OCR task. Also, open-source OCR may have slightly lower output quality compared to commercial solutions in some specific tasks.
Customization options are another key factor in choosing OCR. Commercial solutions most often cannot be customized to the specific needs of the client, even if the datasets necessary for this are available. Open-source OCR can be tailored to specific user requirements, for example, such as handwriting recognition in a rare language.
An experienced software development team can help you choose the right OCR software. Since the OCR engine is just a part of the product, the choice of a specific solution depends on the features and requirements of each individual project. At MobiDev, our team conducts a thorough study of the business case and project requirements in order to select the most optimal optical character recognition engine, test it and integrate into an app. Customization allows you to extend the capabilities of existing OCR and cope with their limitations.

Read also:
AI App Development Guide For Business OwnersLimitations of OCR Technology and How to Overcome Them
Although optical character recognition is a widely used technology, it has limitations, especially if we talk about classical text recognition systems. Combining OCR with computer vision and deep learning improves the accuracy of OCR in many cases, but it is important to understand that it is impossible to achieve 100% results and you will need additional software solutions to improve the outcomes.
The list of key limitations of optical character recognition technology includes the following:
The lower the quality of an image the lower the quality of the OCR output
The OCR result is very dependent on the quality of the original image, which is why the image pre-processing stage is so important. Common OCR errors include misreading letters, missing unreadable letters, or mixing text from adjacent columns. The most commonly used methods for normalizing an image include aligning and rotating the document, removing blur and applying filters, and deleting elements that are not characters (like tables, separator lines, etc.).
Complex image background
Elements such as small dots or sharp edges that make up the background can often be read as characters and distort the results of the text recognition process. That’s why the pre-processing stage for OCR should include noise removal and text field isolation. To overcome the issue of the noise presence like dots, lines, stains, etc. in the background, nowadays OCR approaches use computer vision-based algorithms trained on augmented data sets. Augmented data sets are just regular data sets with artificially added noises to teach an OCR model to tackle the noise properly.
OCR works better with printed text than with handwritten text
Handwritten fonts have hundreds of variations, which complicates the text recognition process. Plus, many options include cases of connecting letters, which are difficult for the system to separate and which lead to a distorted output. For handwriting recognition, the development team needs to train the OCR model using deep learning algorithms and advanced computer vision engines.
It’s worth noting that the more quality the dataset that is used to train the model, the faster it will improve and bring better results. In this case, it’s better to use less data, but the most relevant. Using huge datasets which do not accurately represent your particular project’s real data will not yield successful results.
Other limitations of optical character recognition technology include
- Small text (font size of less than 12 points).
- Form processing because it requires systems where OCR is only a small part of the mechanism.
- Blurry copies. Sometimes inaccuracies can be restored from context, but when it comes to names or numbers, the context may not be enough to restore them.
- Document formatting may be lost during text scanning. For example, bold, italic & underline texts are not always recognized and require subsequent formatting of the document, which is a separate task. The result of OCR always requires spell checking and reformatting for the desired layout.
Build An OCR Solution for Your Business with MobiDev
Optical Character Recognition (OCR) based on AI and machine learning is a widely used technology for text recognition and digitalization of documents. Even though OCR is not yet 100% accurate, its use cases are growing with the development of deep learning and computer vision. Today, one or another type of OCR is used in retail, communications, finance, healthcare, security, tourism, and other industries.
The definition of business goals greatly influences the approaches, architecture, and tools that will be used to develop OCR software. The data should correspond to the objectives of your project and be as real as possible. Creating an effective OCR solution with machine learning is not an easy task so you should enlist the support of experienced AI consultants to get it right.


