

Contents:
Businesses, from market giants like Amazon and Netflix to a small retail store somewhere in the heart of Ohio, strive to grow and improve their efficiency. Incorporating AI and Machine Learning into operational activity is one of the ways to achieve this. But due to the diversity of ML, it’s hard to choose the right method and clearly understand what benefits it can bring. So, in this article we’re going to overview basic Machine Learning algorithms, explain their business application, and highlight a step-by-step guide to choosing an appropriate algorithm that will meet your business needs.
1. Regression
Regression is a rudimental ML algorithm for finding the relationship between at least two variables. These variables can be dependent (target) and independent (predictor). An understanding of how variables affect each other allows for building forecasts, while also identifying times series, cause and effect relationships, and serving as a predictor of strength.
The goal of regression techniques is typically to explain or predict a specific numerical value while using historical data. And the variety of the regression model depends on the type and number of input data (variables). In total, there are more than 10 such models. Simple linear and multiple linear regression are the most popular of them.
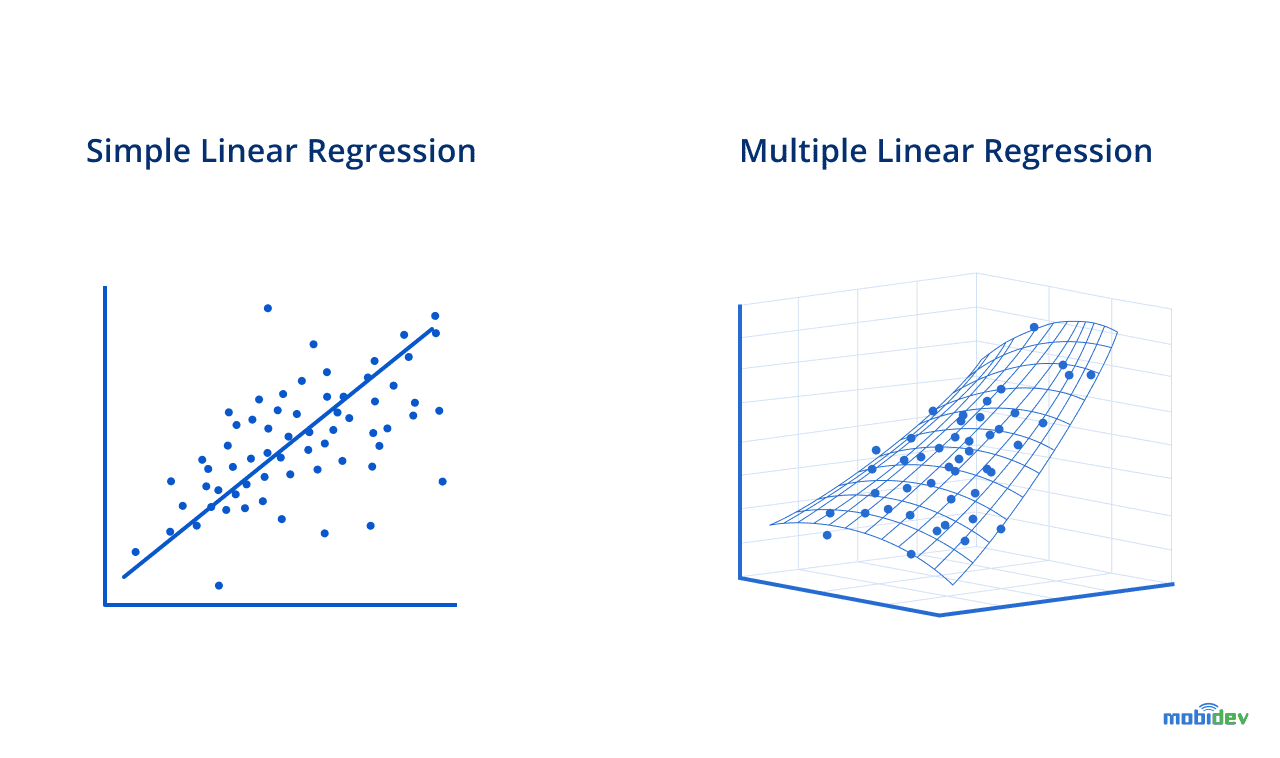
Simple linear regression consists of only one independent and one dependent variable. Multiple linear regression is much more common in practice. It foresees numerous explanatory (independent) variables that influence one dependent variable. Here, a specific example can better illustrate the differences between simple and multiple linear regression.
Assume that we’re dealing with an ice cream business. With a simple linear regression, we can find dependency between the number of sales (dependent variable) and the storage temperature of an ice cream (independent variable). Multiple linear regression covers clarifying deeper patterns. For instance, we can check how independent variables – the storage temperature, pricing, and number of flavors and staff – affect the sales (dependent variable).
Linear regression is easy to comprehend, yet it is rarely used in practice because not all of the features (variables) in the world are perfectly generalized with a linear trend. Usually, non-linear interconnections are more frequent since they depict a curvy trend in the data change occurring in real-life projects.
Time series information in such projects allows us to work with regression tasks by not only finding key factors affecting the target variable but predicting future values based on historically gathered data, including timestamps. This is one of the reasons why regression has found a wide application in areas such as retail software development, business processes optimization, product recommendation systems, and etc.
Business Use Case for Regression Algorithm
Let’s walk through an example of applying a regression model in a restaurant business. Were you a restaurateur, you’d probably think about cost optimization. You can satisfy this need by minimizing the number of spoiled products and by leveraging precise planning of goods purchases. We can develop a regression model that will be able to predict when and how many products to buy, considering the expiration date of different products. To make a workable model, we’d need to feed it with the following historical data:
- The number of restaurant dishes that were sold during the past periods (grouped by days, weeks, etc.)
- Holiday info (these days have other specifics)
- Marketing campaign info
The benefits are obtained through the regression model adoption that explains or predicts a numerical value while using historical data from a previous data set. After you implement the described solution, you can plan purchases more accurately.
2. Classification
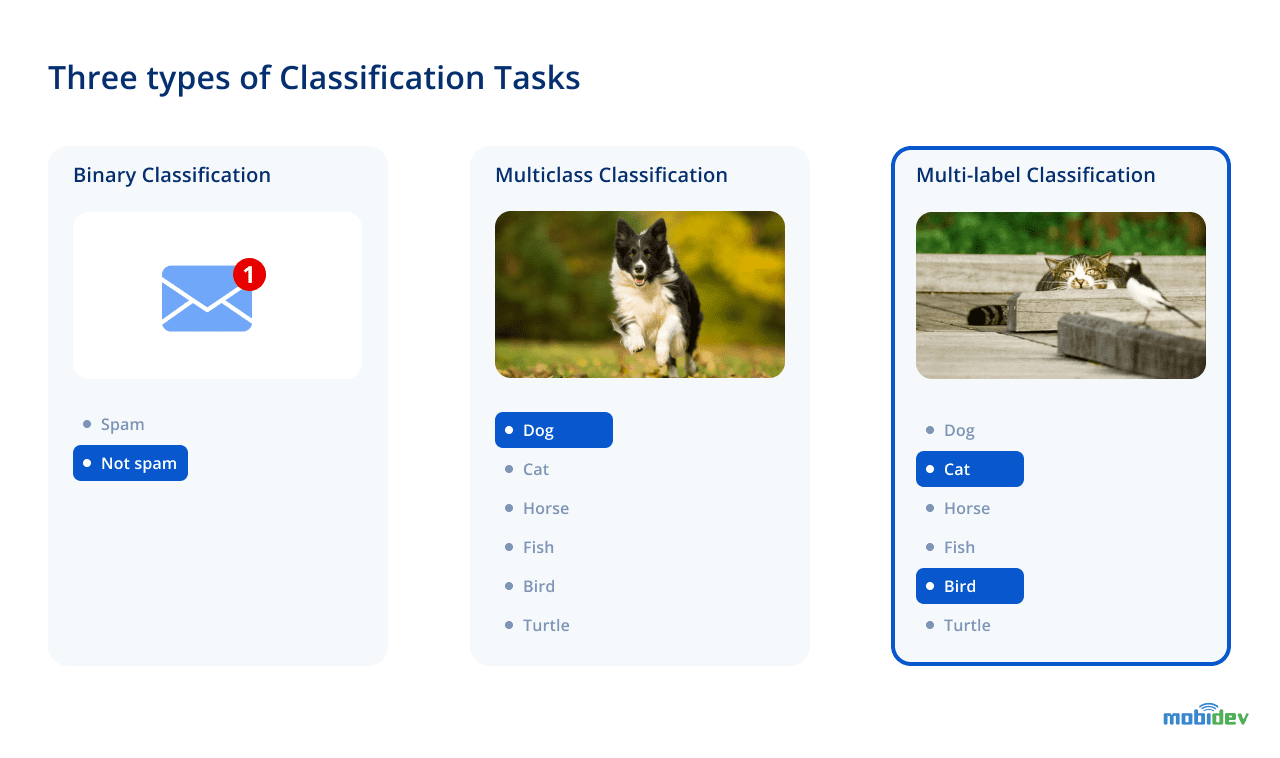
Classification is an ML algorithm of categorizing unstructured or structured data. Its application remains effective in such areas as spam filtering, document classification, auto-tagging, and defect detection. Classes here may be perceived as labels or targets. By analyzing the input, the model learns how to classify new information, mapping labels or targets to the data. At the same time, binary, multiclass, and multilabel are the main types of classification algorithms.
Binary classification
We train the model to classify new data into 2 categories (spam or non-spam emails, has or doesn’t have a lung disease, buy or don’t buy a product, alpaca or llama image, which depicts a bit more complicated case of a few-shot learning classification).
The binary model training requires a dataset, which is labeled with 0 and 1. After the model analyzes the sorted dataset, it is capable of predicting labels for new data. At the core of learning lies the ability to recognize patterns.
Multiclass classification
We train a model to classify into more than two categories. For instance, a classifier can learn how to identify cats, dogs, lizards, and other animals. To achieve the reliable accuracy of recognition, the model should determine and grasp the features that enable classification into categories. However, in multiclass as well as binary classification, only one category can be assigned to the data sample.
Multilabel classification
In multilabel classification, zero or more labels can be assigned to different objects. A classifier here may recognize cats, dogs, and other animals that are depicted in one picture. A prominent example of multilabel classification is auto-tagging: blog articles can be marked with relevant tags like “AI”, “ML techniques”, “Healthcare”, and so on.
While completing classification tasks, the model makes the prediction with the probability from 0 to 1, describing the confidence with which it has delivered this or that verdict regarding the category. The number 0 means total uncertainty, and 1 represents 100% confidence in the performed classification. Therefore, depending on the specifics of the business and the client’s tasks, this threshold can be customized (not necessarily more than 0.5 – means “yes”, less than 0.5 – means “no”; you can adjust these numbers to the business needs).

Read also:
Deep Learning Image CaptioningBusiness Use Case for Classification
Helpdesk assigns tags to each of the conversations with the customers. This is done for quick and easy navigation between previous customers’ requests and for grouping conversations by topics. This process should be automated to reduce manual work.
The business solution in this case is based on previously tagged client’s data. We can develop a multi-label classification model that will be able to automate the process of assigning several tags to the new conversations with the customers. So, call center specialists will not spend time on this activity, focusing on the other priority tasks instead.
3. Clustering
Clustering is an ML method that allows us to identify and group data points in organized structures. These structures represent large datasets, which can be seamlessly grasped and manipulated, and new insights can be achieved from the grouped data after clustering modeling. Unlike classification, clustering doesn’t require labeled data. After all, it tries to find patterns by identifying shared or similar properties, and then applies these patterns to create separate groups (clusters).
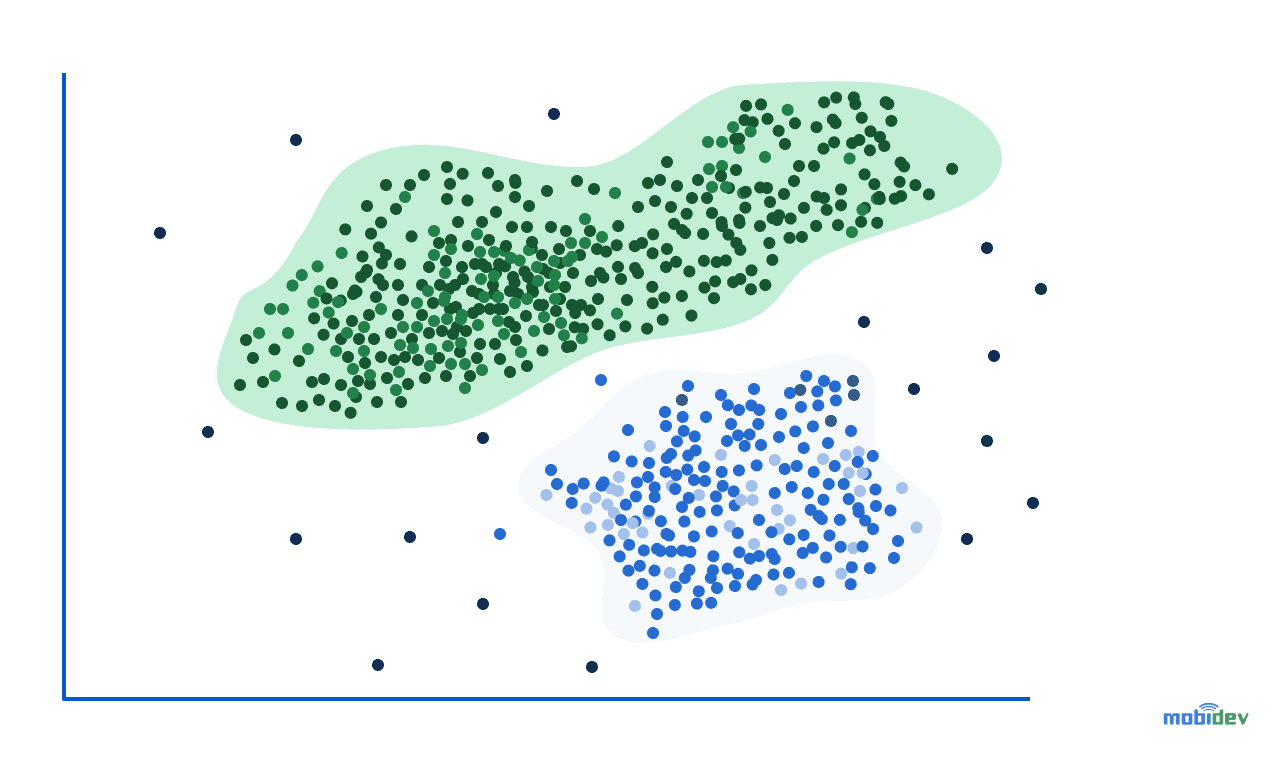
Grouping or clustering techniques are particularly useful in business applications, where there is a need to segment or categorize large volumes of data. Typical cases include segmenting customers by different characteristics to better target marketing campaigns and recommending news articles that certain readers will enjoy. Clustering is also effective in discovering patterns in complex datasets that may not be obvious to the human eye, which makes it one of the most used AI techniques in marketing.
Clustering Machine Learning models differ depending on the approach. Sometimes we start with randomly initialized center points like in K-Means and other centroid-based algorithms, other times we apply hierarchical, density, or distribution-based methods. All these algorithms open up opportunities for business usage in anomaly detection, image segmentation, social network analysis, improving marketing campaigns, and fraud detection.
Business Use Case for Clustering
Retail business can serve as an example here. Imagine that the business owner intends to analyze employees’ performance and identify who is not working very hard. Every day a lot of employees work in different supermarket chains with money, so the owner wants to get a full picture of employees’ performance, being able to evaluate the efficiency of operational costs.
In order to help with the solution, we can develop a clustering model for anomaly detection. In our case, the anomaly activity is fixed if employees’ behavior is uncommon (differs from all of the rest). By applying the clustering algorithm, we identify groups of employees whose behavior differs significantly from the majority of the staff. Clustering is the first step towards tackling performance issues and productivity optimization, though a business has enough room for the adoption of other ML algorithms.
4. Deep Learning
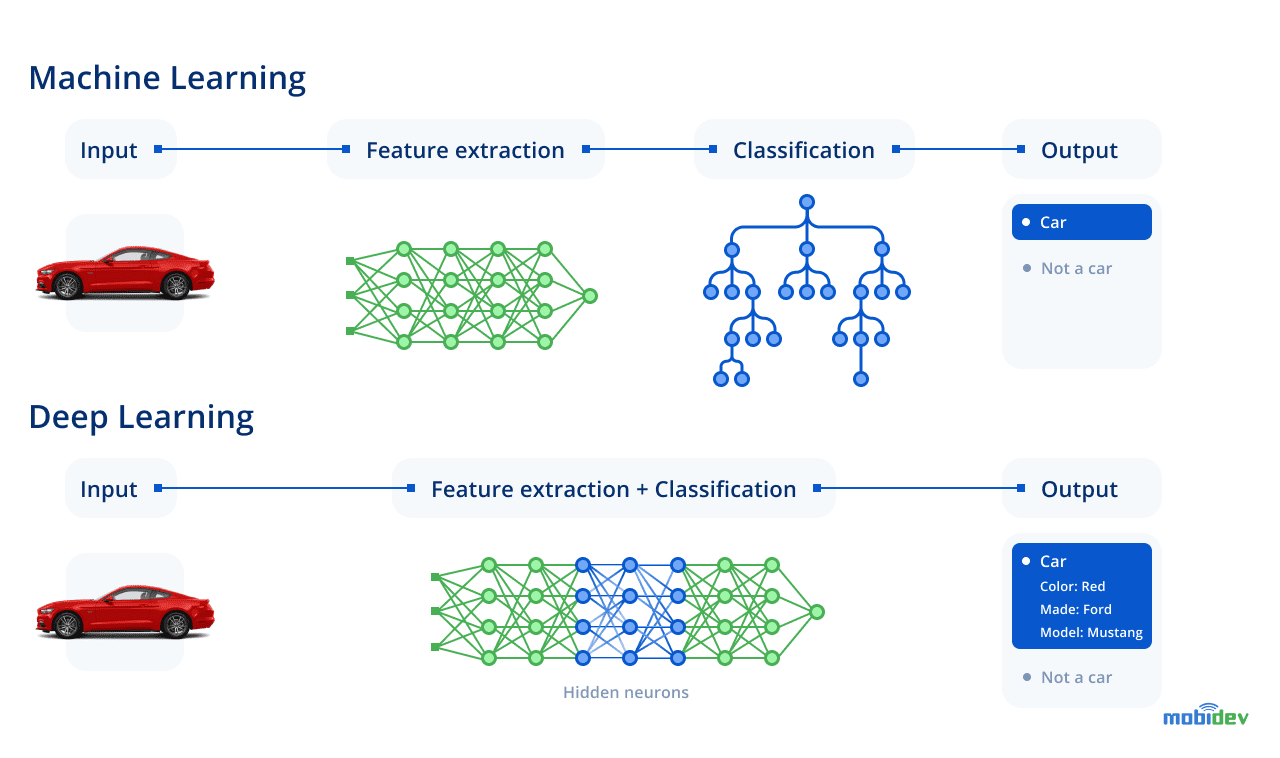
Deep learning (DL) is a field of AI that partially emulates the approaches taken by human beings while learning. DL algorithms substitute a neural network with at least three layers that breaks problems into levels of data and then solves them. These algorithms resemble the functioning of our brains when we start to comprehend the world, learn words, and recognize new objects.
In this way, being a branch of ML, deep learning substitutes algorithms that lie on multi-layer neural networks, but differ from traditional AI/ML techniques (see the picture below). The key difference is that deep learning models do not require data with a set of relevant features – it’s enough just to provide them with raw data, giving the algorithm a chance to define relevant features on its own. DL models are amplifying along with the increasing amount of data applied for the training. So, the development of deep learning looks as follows: layers of a neural network consist of neurons that transmit information to the neurons of the subsequent layer, and the model arrives at a decision when data gets to the output layer.
Deep learning models are used for a wide variety of business applications. In healthcare, they help detect cancer, speed up diagnostic procedures, and search for drugs. In the telecommunications and media industry, neural networks can be used for machine translation, fraud detection, and virtual assistant services. The financial industry uses them for anomaly fraud detection, portfolio management, and risk analysis.
Summing up, we can state that DL is capable of text summarization, new image generation, speech-to-text conversion, emotion detection, movement recognition.
Business Use Case for Deep Learning
Imagine a shoe business with a team providing customer support services via chats and phone. A business owner wants to be able to briefly analyze the quality of services granted by employees and check the level of customer satisfaction.
The business solution may be built on top of the text summarization that allows us to extract the most relevant information from the chat support text. In order to be able to process audio conversations as well, we can apply speech-to-text models for extracting text information from the audio. Also, aiming generally to analyze the level of customers’ satisfaction, we can work on sentiment analysis models that identify the tone of the conversations (positive or negative dialogues).
5. Dimensionality Reduction
Dimensionality reduction techniques involve reducing the number of input features, variables, or attributes, while maintaining as informative a dataset as possible. Why do we need it, if usually we are aiming to have the maximum amount of data for training the perfect model?
It quite frequently happens that the performance of machine learning algorithms can degrade with too many input variables. A greater number of features increases the chance to overfit the model, which is fraught with poor quality results.
Thanks to the dimensionality reduction, we are able to shorten the duration of the training, shun overfitting, and apply the algorithm for data preparation performed prior to modeling.
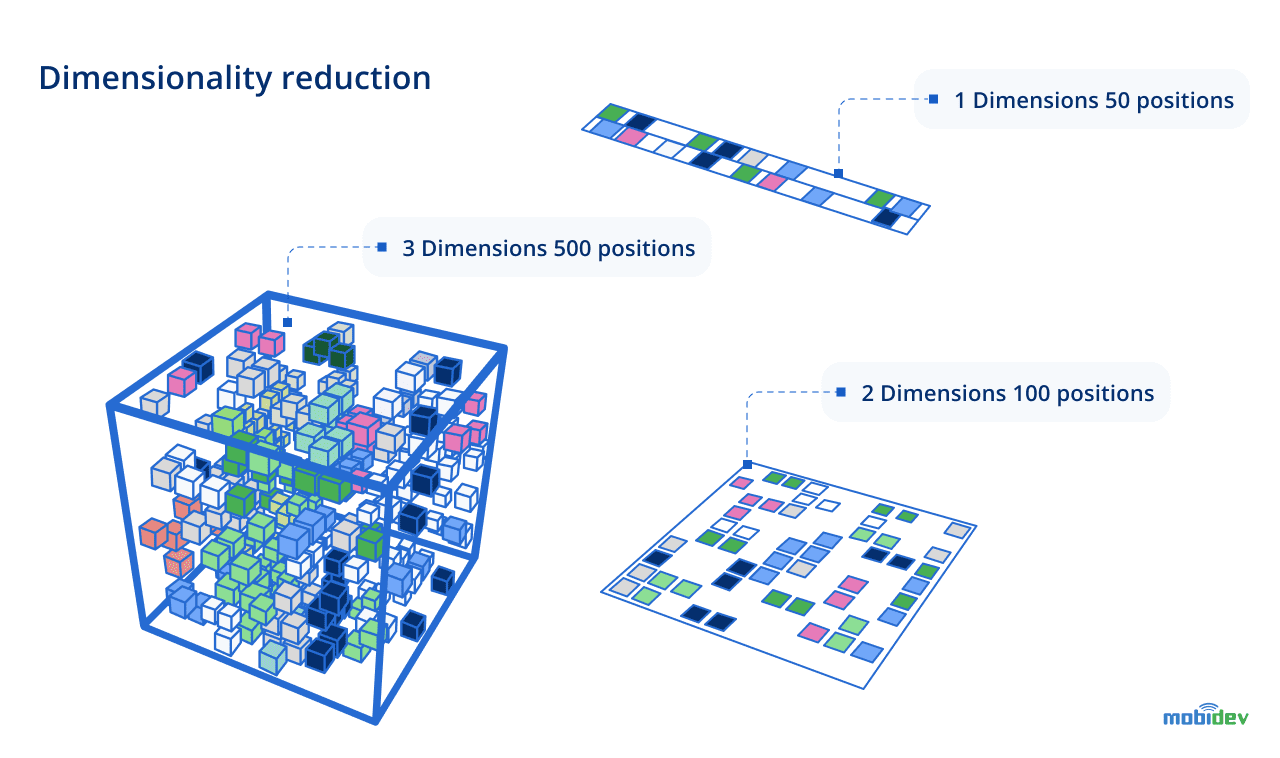
Business usage of dimensionality reduction isn’t limited to data preparation before modeling and includes the following areas: visualization of high-dimensional data, image compression, models runtime optimization, and reducing models complexity.
Business Use Case for Dimensionality Reduction
To better understand this algorithm, we will look at a case study. The company produces and monitors a lot of different sensors and has plenty of data that needs to be analyzed. A prediction model based on existing data may serve them well. It should analyze historical data from a bunch of sensors and predict some information, taking into account original data.
Sensor data is sparse, so applying ordinary machine learning algorithms without preprocessing steps will result in low-quality model performance. So, one of the best options is to use dimensionality reduction methods before modeling, thus being able to reduce the number of features and leave only the most relevant ones for obtaining reliable model quality. Then, after retrieving important data, we can apply regression or classification models for performing predictive modeling based on the target feature we need to predict.
From dimensionality reduction to regression, choosing among Machine Learning techniques may be tough. Get acquainted with our recommendations to solve this issue.
How to Choose ML Algorithm for Your Business App
According to ML classification, there are supervised, unsupervised, and reinforcement learning options to be utilized for this business need. In supervised learning, we encounter an idea of training based on labeled input and output data. (Regression and classification are algorithms of this group.) As for unsupervised learning models, they require data with input features, but without labeled output and are capable of finding structures within the given data. (Segmentation and clustering belong to this category.) In the case of Reinforcement learning, ML models solve a task by improvising and through further analysis of the feedback regarding taken actions and solutions.
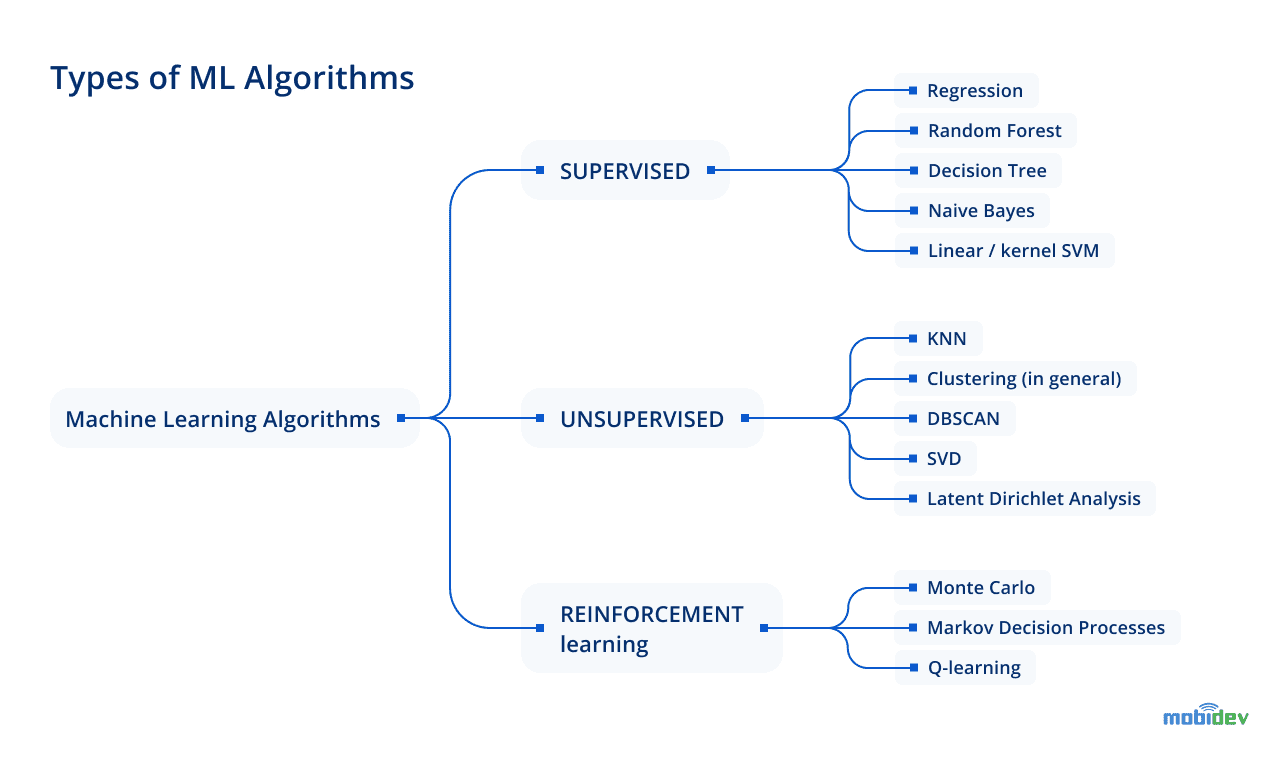
Once you’ve learned about the types of ML algorithms, you can take a look at a step-by-step guide to choosing an appropriate algorithm for business application:
- Define the business problem and algorithms that are the most suitable for tackling it
- Check available data (amount, characteristics, type, and behavior)
- Think about optimal evaluation metric and speed
- Decide on a suitable number of features and parameters
- Stick to a baseline model or more sophisticated solution (if simple linear algorithms work well, there is no need to complicate the work)
With all the diversity of top Machine Learning algorithms, you might get confused about what method to choose. Try to adhere to a data-related or problem-related approach. Remember that better data is of greater significance than an algorithm, which can be easily enhanced by extending the training time. However, if you need to apply technology and drive significant business change, our experienced AI engineers are ready to help with choosing and implementing ML algorithms into your business.


