
Contents:
Technologies applied to turning the sequence of pixels depicted on the image into words with Artificial Intelligence aren’t as raw as five or more years ago. Better performance, accuracy, and reliability make smooth and efficient image captioning possible in different areas – from social media to e-commerce. The automatic creation of tags corresponds with a downloaded photo. This technology could help blind people to discover the world around them.
This article covers use cases of image captioning technology, its basic structure, advantages, and disadvantages. Also, we deploy a model capable of creating a meaningful description of what is displayed on the input image.
As a vision-language objective, image captioning could be solved with the help of computer vision and NLP. The AI part onboards CNNs (convolutional neural networks) and RNNs (recurrent neural networks) or any other applicable model to reach the target.
Before moving forward to the technical details, let’s find out where image captioning stands.
AI-driven image tagging and description use cases
“Image captioning is one of the core computer vision capabilities that can enable a broad range of services,” said Xuedong Huang, a Microsoft technical fellow and the CTO of Azure AI Cognitive Services in Redmond, Washington.
He definitely has a point as there is already the vast scope of areas for image captioning technology, namely:
Image tagging for eCommerce, photo-sharing services and online catalogs
In this case, the automatic creation of tags by photo is being carried out. For instance, it can simplify users’ life when they upload an image to an online catalog. In this case, AI recognizes the image and generates attributes – these can be signatures, categories, or descriptions. The technology could also determine the type of item, material, color, pattern, and fit of clothing for online stores.
At the same time, image captioning can be implemented by a photo-sharing service or any online catalog to create an automatic meaningful description of the picture for SEO or categorizing purposes. Moreover, captions allow checking whether the image suits the platform’s rules where it is going to be published. Here it serves as an alternative to CNN categorization and helps to increase traffic and revenue.
Note: Creating descriptions for videos is a much more complicated task. Still, the current state of technology already makes it possible.
Automatic image annotations for blind people
To develop such a solution, we need to convert the picture to text and then to voice. These are two well-known applications of Deep Learning technology.
An app called Seeing AI developed by Microsoft allows people with eye problems to see the world around them using smartphones. The program can read text when the camera is pointed at it and gives sound prompts. It can recognize both printed and handwritten text, as well as identify objects and people.
Google also introduced a tool that can create a text description for the image, allowing blind people or those who have eyesight problems to understand the context of the image or graphic. This machine learning tool consists of several layers. The first model recognizes text and hand-written digits in the image. Then another model recognizes simple objects of the surrounding world–like cars, trees, animals, etc. And a third layer is an advanced model capable of finding out the main idea in the full-fledged textual description.
AI image captioning for Social Media
Image caption generated with the help of an AI-based tool is already available for Facebook and Instagram. In addition, the model becomes smarter all the time, learning to recognize new objects, actions, and patterns.
Facebook created a system capable of creating Alt text descriptions nearly five years ago. Nowadays, it has become more accurate. Previously, it described an image using general words, but now this system can generate a detailed description.
Logo identification with help of AI
Image captioning technology is being used in AI app development with other AI technologies as well. For instance, DeepLogo is a neural network based on TensorFlow Object Detection API. And it can recognize logotypes. The name of the identified logotype appears as a caption on the image. Our research on the GAN-based logotype synthesis model could bring light to how GANs work.
Researching Deep Learning models for Image Captioning
Keeping in mind possible use cases, we applied a model that creates a meaningful text description for pictures. For example, the caption can describe an action and objects that are the main objects on each image. For training, we used Microsoft COCO 2014 dataset.
COCO dataset is large-scale object detection, segmentation, and captioning dataset. It contains about 1.5 million different objects divided into 80 categories. Each image is annotated with five human-generated captions.
We applied Andrej Karpathy’s training, validation, and test splits for dividing datasets to train, validate, and test parts. Also, we needed Metrics like BLEU, ROUGE, METEOR, CIDEr, SPICE, to evaluate results.
Comparing Machine Learning models for Image captioning
Typically, baseline architecture for image captioning encodes the input into a fixed form and decodes it, word by word, into a sequence.
The Encoder encodes the input image with three color channels into a smaller image with “learned” channels. This smaller encoded image is a summary representation of all that’s useful in the original image. For encoding, any CNN architecture can be applied. Also, we can use transfer learning for the encoder part.
The Decoder looks at the encoded image and generates a caption word by word. Then, each predicted word is used to generate the next word.
Before moving forward, take a look at what we have received as a result of the model creation and testing with the Meshed-Memory transformer model.
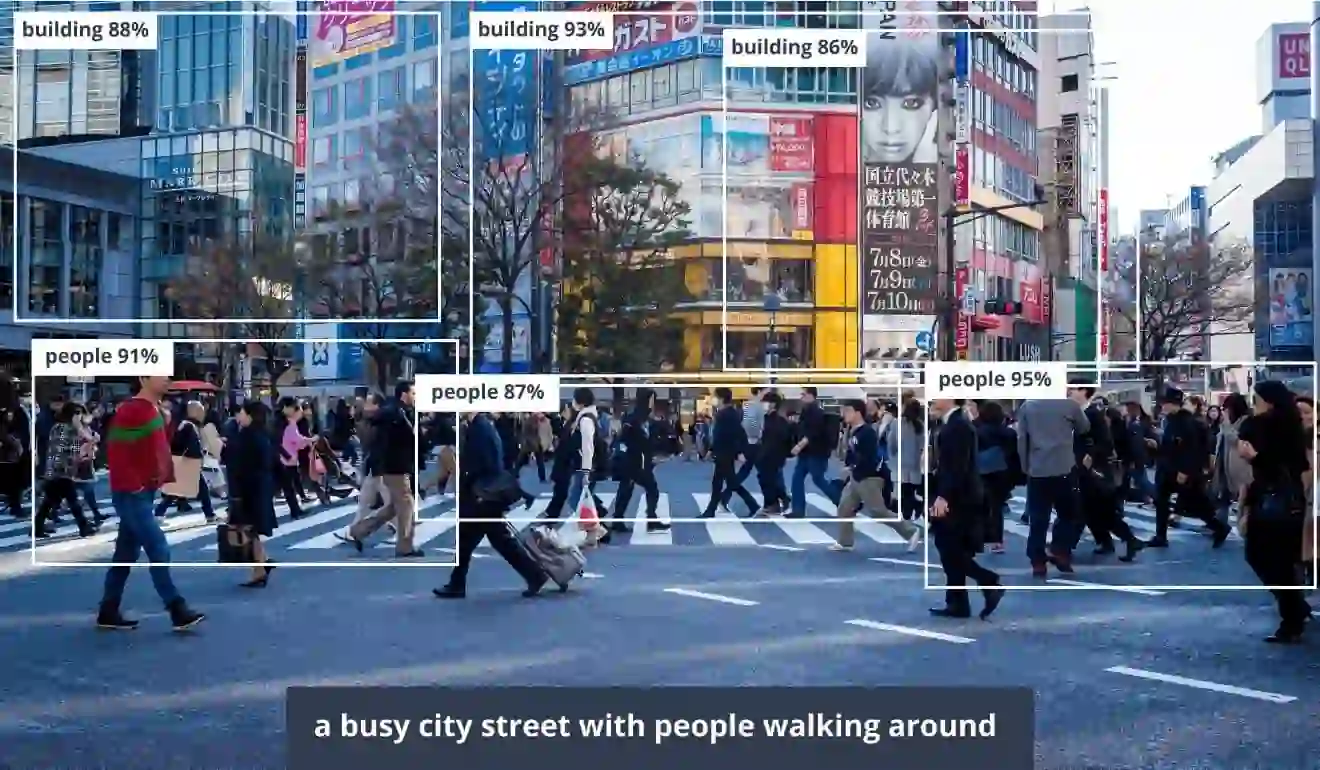


AI-based image captioning is now always accurate
We also studied examples that led to errors. There are several reasons why errors appear. The most common errors are related to poor image quality, and the absence of certain elements in the initial dataset. The model was trained on a dataset with general pictures, so it makes mistakes in cases when it does not know the content, or is unable to identify it correctly. This is the same way the human brain works.


Here is another case to illustrate how Neural Networks operate. There were no tigers in the dataset used for training the model, so it is unable to identify tigers. Instead, AI picked the closest object it knows – it is quite the same, as our brain deals with the unknown.

Up-Down attention model for image captioning
This is the first model to compare. The Up-Down mechanism combines Bottom-Up and the Top-Down attention mechanism.
Faster R-CNN is used to establish the connection between object detection and image captioning tasks. The Region proposal model is pre-trained on object detection datasets due to leveraging cross-domain knowledge. Moreover, unlike some other attention mechanisms, both models use one-pass attention with the Up-Down mechanism.
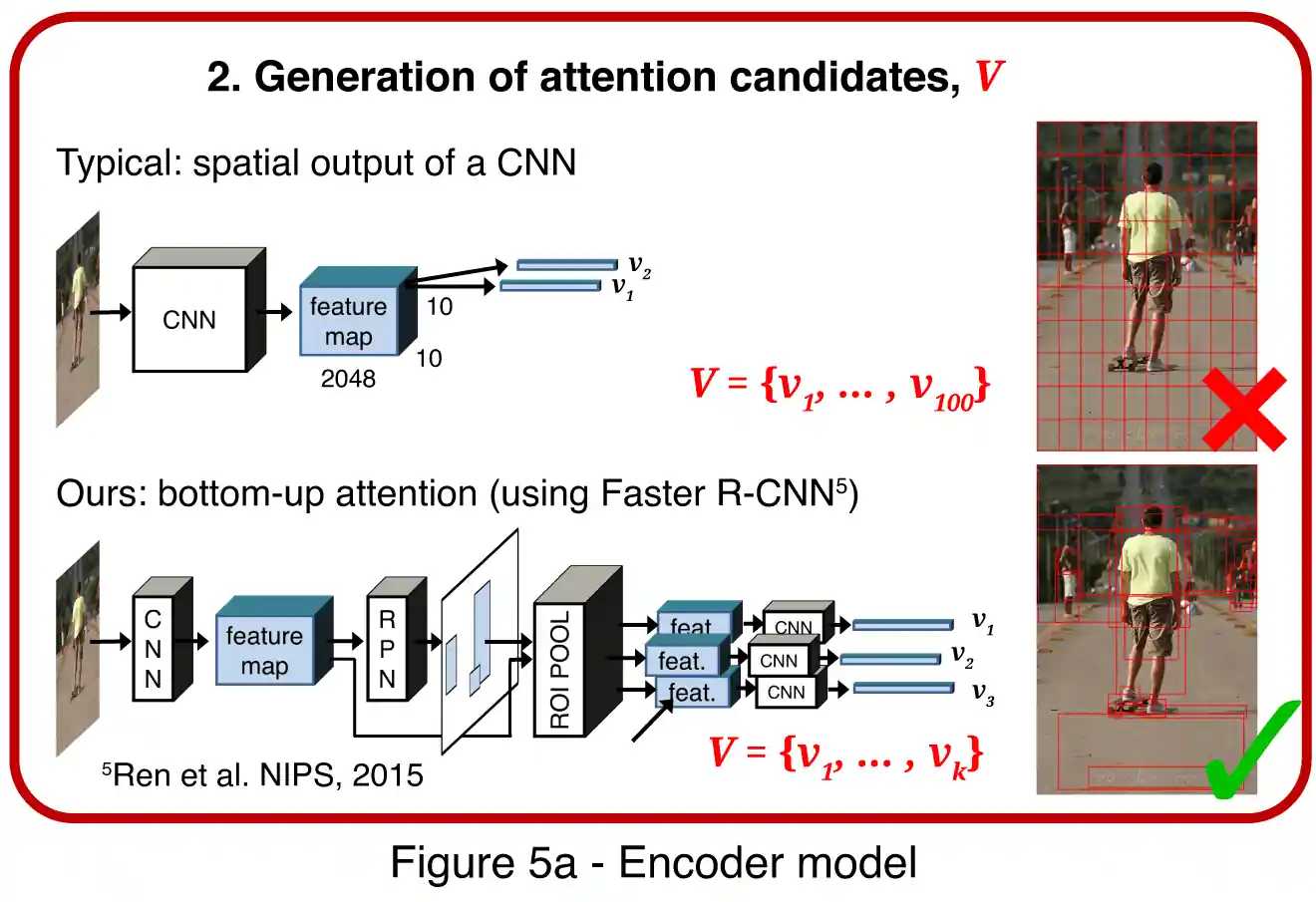
Faster R-CNN (fig 5a) is used for image feature extraction. Faster R-CNN is an object detection model designed to identify objects belonging to certain classes and localize them with bounding boxes. Faster R-CNN detects objects in two stages.
The first stage, described as a Region Proposal Network (RPN), predicts object proposals. Using greedy non-maximum suppression with an intersection-over-union (IoU) threshold, the top box proposals are selected as input to the second stage.
At the second stage, region of interest (RoI) pooling is used to extract a small feature map (e.g. 14×14) for each box proposal. These feature maps are then batched together as input to the final layers of the CNN. Thus, the final model output consists of a softmax distribution over class labels and class-specific bounding box refinements for each box proposal. The scheme is taken from the official poster.
This is LSTM with an added up-down attention mechanism. Given a set of image features V, the proposed captioning model uses a ‘soft’ top-down attention mechanism to weigh each feature during caption generation. At a high level, the captioning model is composed of two LSTM layers.
Meshed-Memory transformer model for image captioning
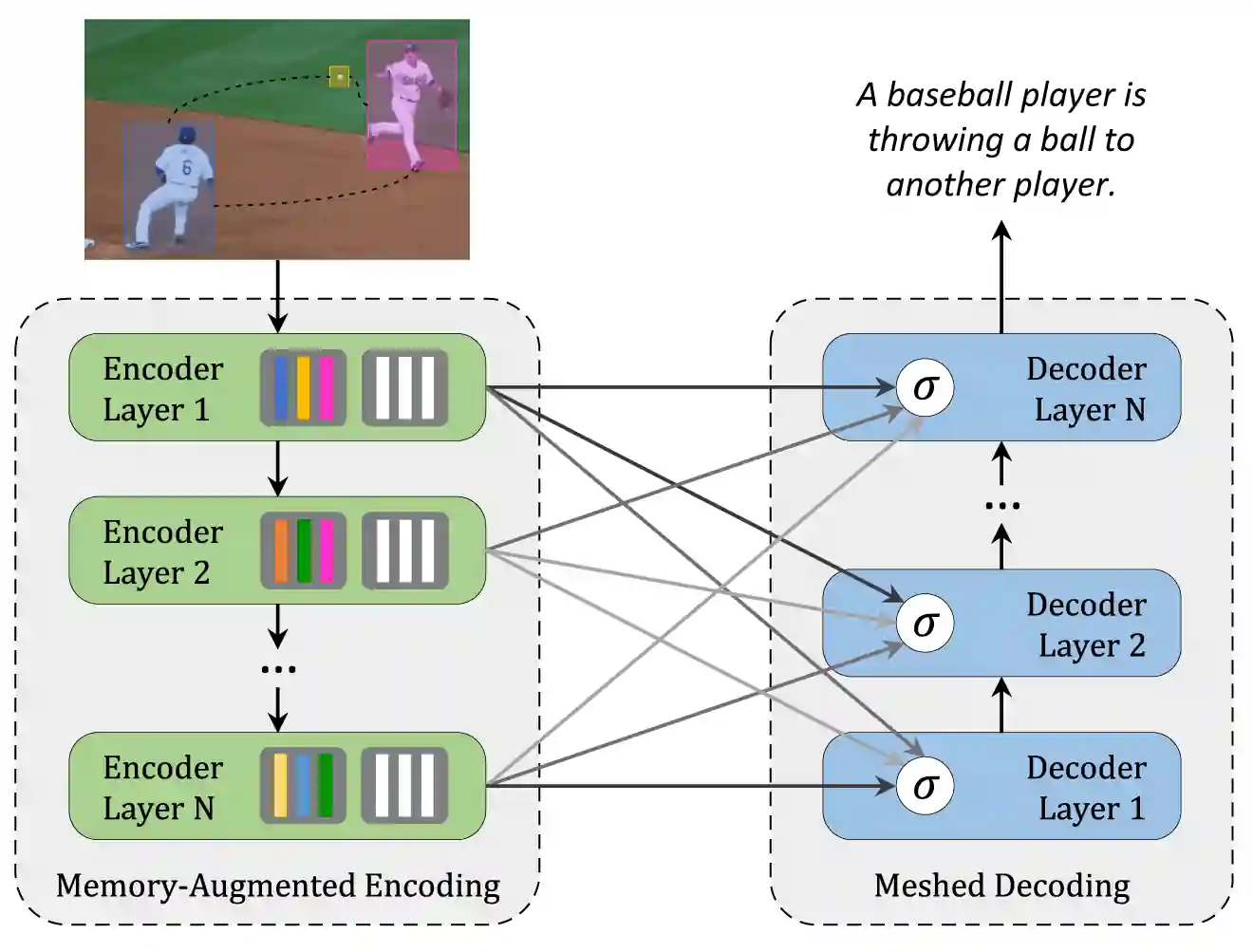
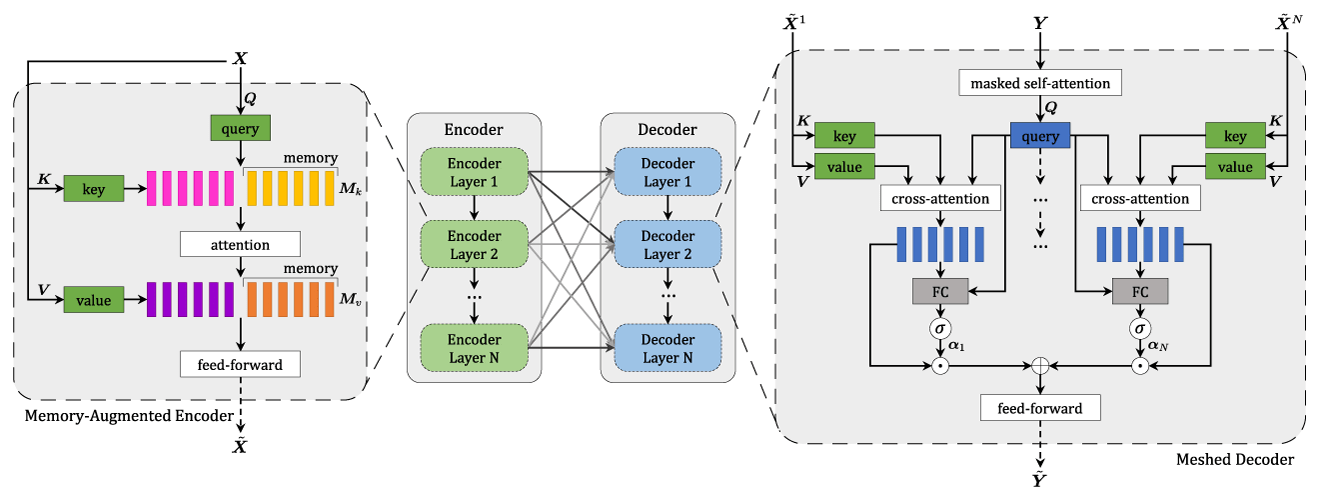
Another model that we took to solve the image captioning task is Meshed-Memory Transformer. It consists of encoder and decoder parts. Both of them are made of stacks of attentive layers. The encoder also includes feed-forward layers, and the decoder has a learnable mechanism with weighting.
Regions of the image are encoded in a multi-level fashion. The model takes into account both low-level and high-level relations. Learned knowledge is encoded as memory vectors. Layers of encoder and decoder parts are connected in a mesh-like structure. The decoder reads from the output of each encoding layer and performs self-attention on words and cross attention over all encoding layers after that results being modulated and summed.
So, the model can use not only the visual content of the image but also a prior knowledge of the encoder. The schemes are taken from the official paper.
Comparison of Two Models for image captioning
Based on our research, we’re able to compare the Up-down model and the M2transform model, as they were trained on the same data. The table below provides a summary of both models.
Table – Evaluation metrics
| BLEU1 | BLEU2 | CIDEr | ROUGE | METEOR | |
| UpDown model | 0.8 | 0.358 | 1.16 | 0.573 | 0.275 |
| M2Transformer | 0.8078 | 0.3834 | 1.278 | 0.58 | 0.2876 |
Table – Inference time and memory
| Time | Memory | |||
| CPU | GPU | CPU | GPU | |
| Updown model | 104.47s | 17s | 1479mb | 1181mb |
| M2Transformer | 23 m 32 s | 3m 16s | 1423mb | 1310mb |
Image Captioning–Results Analysis and Future Prospects
Both used models showed fairly good results. With their help, we can generate meaningful captions for most of the images from our dataset. Moreover, thanks to the feature pre-extracting with Faster-RCNN, pre-trained on the huge Visual Genome dataset, the model is able to recognize many objects and actions from people’s everyday life, and therefore describe them correctly.
So what is the difference?
The Updown model is faster and more lightweight than the M2Transformer. The reason is that the M2Transformer uses more techniques, like additional (“meshed”) connections between encoder and decoder, and memory vectors for remembering the past experience. Also, these models use different mechanisms of attention.
Updown attention can be performed in a single pass, while multi-headed attention that is used in M2Transformer should be running in parallel several times. However, according to the obtained metrics, M2Transormer achieved better results. With its help, we can generate more correct and varied captions. M2Transformer predictions contain fewer inaccuracies in description both for pictures from the dataset and for some other related images. Therefore, it performs the main task better.
We compared two models, but there are also other approaches to the task of image captioning. It’s possible to change decoder and encoder, use various word vectors, combine datasets, and apply transfer learning.
The model could be improved to achieve better results suitable for the particular business, either as an application for people with vision problems or as additional tools embedded in e-commerce platforms. To achieve this goal, the model should be trained on relevant datasets. For example, for a system to correctly describe cloth, it is better to run training on datasets with clothes.


