
Contents:
Summary:
We wondered whether it was possible to apply a generative model for a problem of content synthesis in order to automate the work of graphic designers. So we focused on logotype synthesis and checked this hypothesis. Our aim was to find out the possibilities and limitations of the technology, as well as the prospects of its application for the generation of images.
To create unique icons and explore how the image generation actually works with generative models, MobiDev’s AI team used one of the most powerful generative architectures — StyleGan2. The task of generating elements of graphical interfaces and other components that normally requires a human designer, with the help of AI has huge potential and is still in its early stages.
Read our article to determine how it all turned out and which obstacles we faced while solving this problem.
To learn about GANs usage in business, read the first article of this series: “GANs Technology: Use Cases for Business Application“.
We used two data sources for the research — 122,920 high-res (64 – 400px) images from LLD-logo dataset and 51,744 images from BoostedLLD. Unfortunately, BoostedLLD contained only 15,000 truly new images while the rest was taken from LLD-logo. Before being fed to StyleGAN2 to receive GAN generated images in the future, the data was pre-processed, and its total size was reduced to 48,652 images.
Pre-processing Ops for GAN Image Generation — Text-based Images Removal, Clustering, Nearest Image Search
Even with recent improvements in the architecture of GANs, training generative models can be a difficult task to accomplish. The reasons for this are the inherent instability of such models and the absence of a supervised metric to evaluate the outputs.
Therefore, it would be reasonable to somehow preprocess the existing image dataset before feeding it to the model to improve the quality of the generated output.
In our case, the first thing that comes to mind is removing text-based images from the dataset. GANs are able to generate images but to properly add text elements, an additional neural network layer has to be trained.
It is obvious that while a typical GAN can learn different shapes and patterns, the language semantics is something it cannot easily get knowledge of just from the images. This makes the outputs look more like an imitation of text than an actual text.
To generate textual logotypes at least three models are needed.
The first one would be a language model, BERT or GPT-2, that is fine-tuned on the task of logo title generation.
The second model would generate a set of characters with a unique font to visualize the generated content. This model could be based on GAN architecture, with some constraints to ensure all the characters belonging to one font would have a consistent style. This is what was done in the GlyphGAN model.
The last model would generate the rest of the logotype visuals and combine them with already generated text. The resulting pipeline is quite complex and clearly would require long development before yielding good results. Due to this, we decided to focus our attention purely on the non-text-based logotypes.
To find and remove text-containing logotypes, we used a recently published CRAFT character-level text detection model. The model in itself is quite interesting because, as illustrated in Fig. 24, it is able to detect text even in blurred images and distorted/unusually oriented characters or words.

Figure 24. Text detection in logotypes using CRAFT model
Character removal was applied to both LLD-logo and BoostedLLD, resulting in the dataset size being reduced to ~50k images from the original 130k.
To explore more on image clustering with the unsupervised model — download a full version of the article in PDF.
GAN IMAGE GENERATION WITH STYLEGAN2
'> Download PDFVisual Similarity for Nearest Neighbor Search
Image clustering is not the only thing we can achieve using deep embeddings from MoCo (or any other model that is able to construct compressed representations of input data). We can search the embedding space for nearest neighbors, thus finding images most similar to the query image. This technique is widely used to enable image search engines to help find most similar items in the databases, often containing millions of images (Fig. 29).
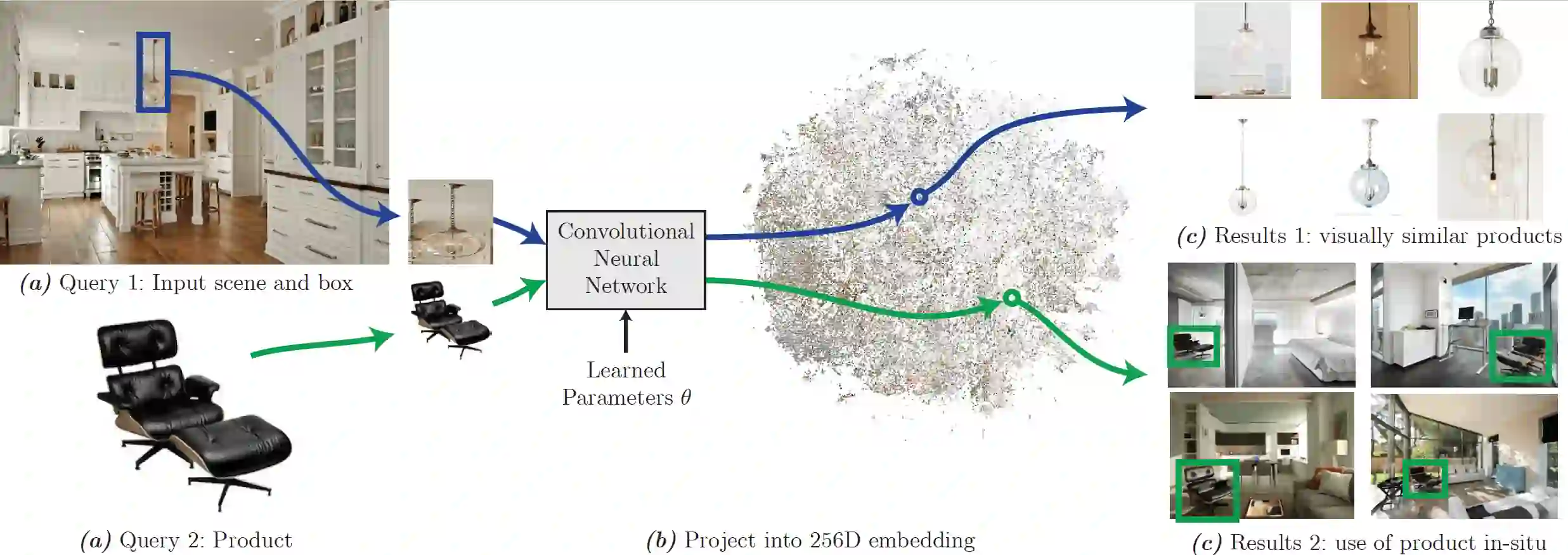
Figure 29. Visual similarity search for household items (source)
We found that with embeddings from MoCo, simple euclidean distance search for k nearest neighbors produced useful results as the neighbors were similar to the query in terms of color scheme and the actual content. In addition, we saw that this technique can be used to find image duplicates in the image database (Fig. 30). The only problem was that sometimes low-res copies of the original were not getting high enough scores and ended up as 2-nd or 3-rd most similar neighbors. This can be fixed by specifically training the model on normal/low res image pairs or applying noise reduction methods before feeding the images into the model (e.g. gaussian blur).



Figure 30. Most similar neighbors search using euclidean distances between image embeddings. Showing 5 most similar neighbors of the original image.

GAN Image Generation of Logotypes with StyleGan2
To recap the pre-processing stage, we have prepared a dataset consisting of 50k logotype images by merging two separate datasets, removing the text-based logotypes, and finding 10 clusters in the data where images had similar visual features.
Now, let’s imagine that we are going to build a tool to help designers come up with new logotype ideas. Here’s where a generative model could help!
The next step is to train an actual generative model on this dataset to produce novel logotype samples. Cluster information could be used as a condition to help the model learn to generate images from different logotype groups. We start our experiments with non-conditional GAN image generation using the full dataset and StyleGan2 model.
In the experiments, we utilized StyleGan2 coupled with a novel Adaptive Discriminator Augmentation ADA (Fig. 31) — image augmentation technique that, unlike the typical data augmentation during the training, kicks in depending on the degree of the model’s overfit to the data.
StyleGan2 features two sub-networks: Discriminator and Generator. During the GAN training, the Generator is tasked with producing synthetic images while the Discriminator is trained to differentiate between the fakes from Generator and the real images. Overfit happens when Discriminator memorizes the training samples too well and does not provide useful feedback to the Generator anymore.
In addition, the augmentations are designed to be non-leaking. Leaking augmentations cause the generator to produce augmented images instead of getting better at producing normal ones. The improvements introduced by ADA allow for more effective training on datasets of limited size. In our case, after splitting the data into clusters, the amount of data per cluster becomes rather small.

Figure 31. StyleGan2 architecture with adaptive discriminator augmentation (left) and examples of augmentation (right) (source)
To achieve the presented results, we used a server with 2 Nvidia V100 GPUs and batch size 200. A typical training run to prepare a model for 128×128 images took 80,000 – 120,000 iterations and 48-72 hrs of time.
Unconditional GAN Images — Good, Medium, and Poor Quality Images
After the GAN image generator has been trained, we have collected a number of logotypes varying in terms of visual quality. Let’s look at the examples of high-quality logos (Fig. 32). As you can see, the network managed to learn not only to reproduce the simple shapes common for logotypes (e.g. circles), but also to generate more complex objects (e.g. rabbit, bird, face, heart, etc.), and, more importantly, to incorporate these shapes into the design of a logotype. Also, the trained network is able to produce appealing-looking textures and color schemes to diversify the final look of the logos.

Figure 32. Good quality logotypes from StyleGan2
Moving on, let’s take a look at the medium-quality images (Fig. 33). Here we begin to see that some shapes look less like a finished image and more like a transition from one shape to another. Moreover, sometimes the model can produce something very simple, not a bad quality result but not something interesting either. One common problem we saw at this stage is due to the abundance of circular shapes in the training data. Similar shapes would frequently appear in the generated result. That’s why creating a curated and diverse training dataset is essential for getting high-fidelity results — the model learns directly from the data and can be only as good as the data is.

Figure 33. Medium-quality logotypes from StyleGan2
Finally, we arrive at poor-quality results (Fig 34). A significant portion of these images are an attempt by the model to generate the shapes it has not yet learnt properly or the shapes that did not have sufficient number of training examples. For example, GAN often tried to produce sketch-like images (Fig. x A-C) but could not output anything worthwhile. As discussed previously, many sketch images were found in cluster 4 (Tab. 1). A small number of examples and the complexity of the sketches make the training task too difficult to figure out. We assume this can be fixed by providing the model with a greater number of sketch images.

Figure 34. Low-quality logotypes from StyleGan2
Other failed attempts were also related to the model trying to represent sophisticated objects and falling short (Fig. D, E). As the data exploration stage showed us, there was a cluster of images displaying some 3d-effects, and the model probably tried to replicate those just like in the case of sketches.
Lastly, there were failed generation attempts (Fig. E, G) that cannot be attributed to any particular reason, which is quite normal with generative models. There will always be some unsuccessfully synthesized images, but their percentage may vary. However, we can always produce more examples, and as long as the bad quality images are not too abundant, they are not going to be a serious source of issues.
Unconditional GAN Images — Interpolation
Simply generating images with GAN is not the only available option to get interesting results. In fact, two latent space embeddings (W) of any two images can be mixed together in different proportions to obtain an intermediate combination of the depicted content (Fig. 35). In machine learning for picture generation, this feature could be exploited to further enhance the diversity of the logotypes or to give a designer the ability to “nudge” the visual style of one logotype in the direction of another logo.

Figure 35. Latent space interpolation between different generated logotypes
Unconditional GAN — Style Mixing
Another interesting option for controlling the look of the generated logotype is partially mixing styles from two logotypes. In the example below, each row uses the same coarse style source (controls the shape of the logotype) while the columns have different fine styles (control minor details and colors), as shown in Fig. 36. As a result, we can imagine that a designer would be able to modify a logotype of a preferred content with a color scheme from another logotype.

Figure 36. Mixing coarse (rows, control the content of the logo) and fine styles (columns, control colors, and fine details)
Conditional GAN — Data Examples from Clusters
Below you can see the results we obtained after training the model on clusters of images as conditions (Fig. 37). The quality and the content of synthetic images varied greatly between the clusters.
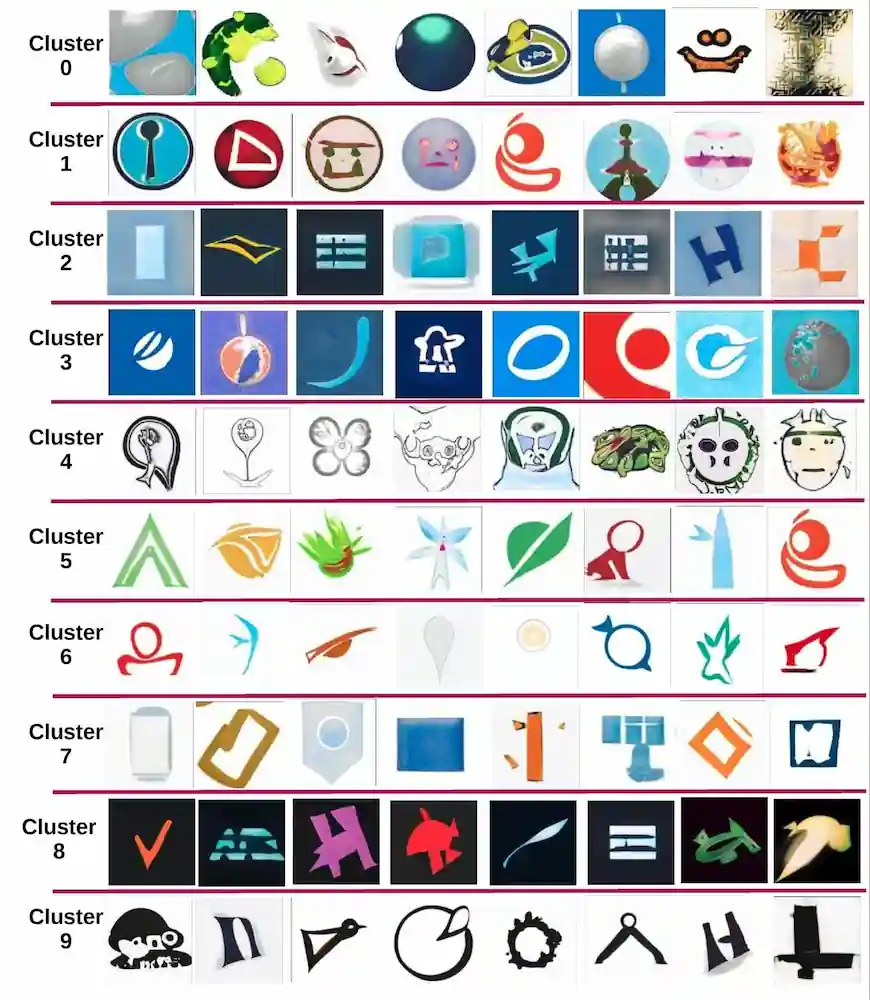
Figure 37. Conditional image generation on 10 image clusters
The most interesting results were seen in clusters 0 and 4, as they originally contained the most complex images illustrating all sorts of objects. As a downside, these clusters also had the highest number of failed generation attempts which is reasonable as the number of training examples here was relatively small (~18 % from 50k logos). Other clusters were more stable (e.g. 2, 3, 7, 8) but produced more predictable, less varied geometric shapes. Finally, clusters 1, 5, 6, and 9 offered a combination of more or less unique visual styles and a higher rate of successful generation outcomes.
Conclusion and Future Work with GAN Image Generation
This article explored GAN image generation. It showed in practice how to use a StyleGAN model for logotype synthesis, what the generative model is capable of, and how the content generation in such models can be manipulated.
From the obtained results, we saw that while the quality of the generated images can be rather high, the main problem at the current stage is the ability to control the outputs of the model. This can be accomplished using interpolation between images, style mixing, conditional image generation, and image inversion (converting any image to logotype using GAN). However, the problem is still not fully resolved.
Looking into the future, we believe that a natural evolutionary path of generative models for content synthesis is text-enabled image generation, as it alleviates most of the issues encountered in usual generative models. A great example of this approach is the DALL-E model presented in 2021 by OpenAI. DALL-E is based on another model from the same team, language model GPT-3, that has been upgraded to work not just with word tokens, but image tokens as well (256×256 images are encoded to 32×32=1024 tokes using 8×8 image patches that are fed into a Variational Autoencoder).

Figure 38. Converting text input “a stained glass window with an image of a blue strawberry” into images using DALL-E (source)
After the training on reconstructing images by their text descriptions, the resulting model can interpret complex pieces of text inputs and produce surprisingly varied and high-quality images (Fig. 38).
There are two notable downsides to this method. The presented model has a size that is prohibitive for most applications (1.2B parameters). Training such a model requires text caption-image pairs that the authors mined from the internet. While the first problem can be addressed by creating a smaller, domain-specific model, the second problem may be somewhat difficult to tackle (gathering thousands of textual logotype descriptions is not an easy task). However, the advantages proposed by the text-image generation are too significant to ignore.
For now, the best option is to use the approach we showed in this article (conditional image generation with GANs). The future does hold a lot of promise for this new image generation method, and we expect more progress to be made in this direction in the following years.
Feel free to contact us for machine learning consulting services.


