
Contents:
If you are here, you probably know about the transformative power of AI for businesses. With the emergence of foundation models like CHAT GPT, Google’s Bert language models, Nvidia neural networks, DALL-E and others, requirements for entering the AI market grow exponentially.
Meanwhile, data remains a by-product of any active business and ignoring its existence nowadays costs more than making use of it. So in this article, MobiDev experts share their opinions on different aspects of handling AI app development.
Why Are AI Projects So Unpredictable?
The AI project itself is much more difficult to estimate since we’ll often deal with a technology that is not being used widely. Although, this is only partially true since there is a gradation of complexity for AI projects that determines their predictability.
AI project development can be visualized as a three layer pyramid, where the upper layer contains wide-studied solutions, coming down to the lower layer which comprises scientific research projects. The complexity of every project depends on the details and customizations you want to implement. This can be elaborated either on the first stages of the project, or as a part of an AI consulting service.
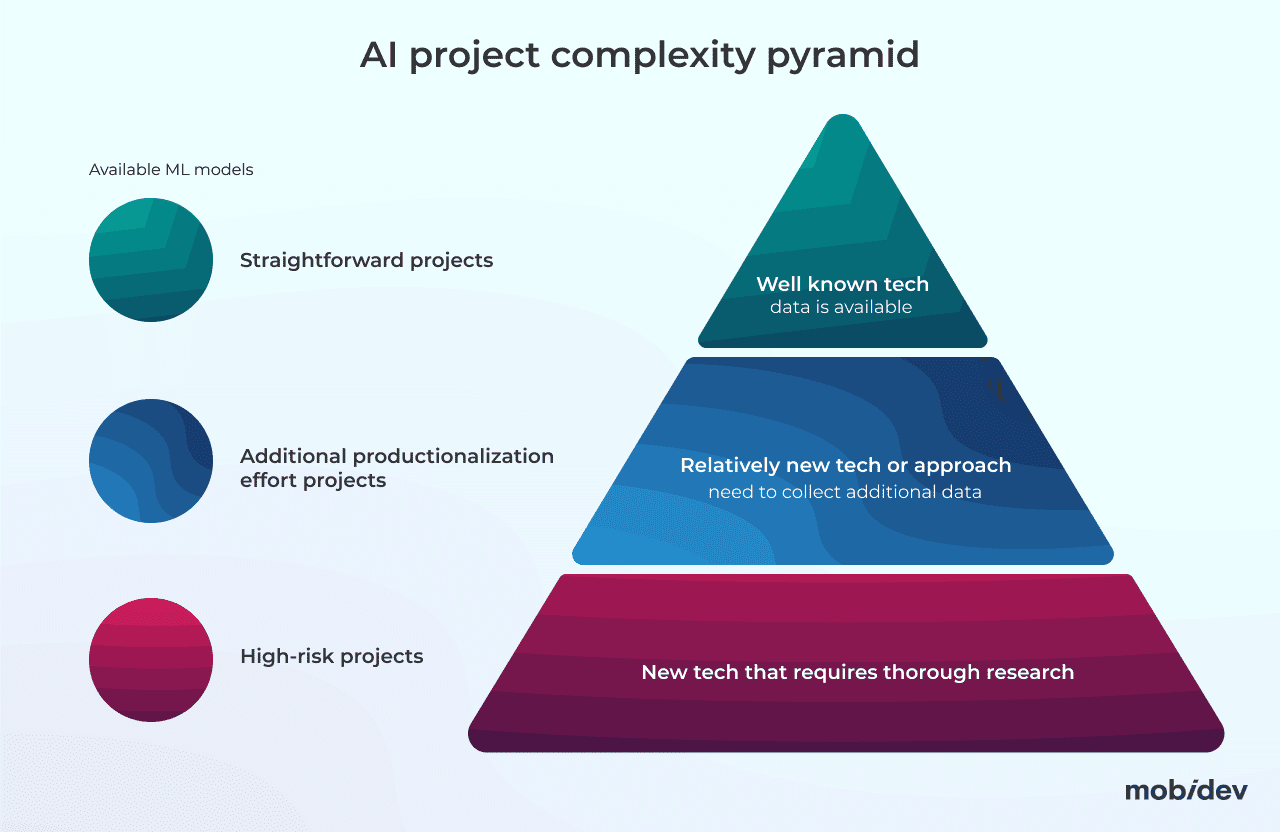
AI project complexity explained
Our approach to estimating AI projects is to focus on ensuring the essential AI functionality is viable and we can adopt a fail-safe approach. This is done through developing the most complex and uncertain scope and adjusting the project based on the outcomes. This way we can figure out estimates for each phase and calculate the budget allocation without any harm to the entire project’s delivery.
Differences Between AI Projects and Traditional Software Projects
Any AI feature will turn around data and a specific task you want to achieve by processing this data. This can be historical information used for training and retraining models, or real-time data fed directly to some sort of the analytical system. In either case, data presents both possibilities and challenges, because we need to cover various considerations like:
- Data storing and availability, both on infrastructure level and personal level.
- Machine learning pipeline, which is a separate ecosystem for model training, data transmission, transformation, servers for model deployment, etc.
- A more pressing issue of privacy, ethics and intellectual property imposed by existing laws that differ from country to country, or even state to state.
- Violation of intellectual property rights in case we’re talking about generative AI.
Privacy concerns are not a part of any AI project. This consideration usually relates to the software within computer vision, or biometric systems. There are almost always pitfalls you want to oversee during the stage of creating a tech vision and initial roadmaps. This is because artificial intelligence design must prioritize data security and while obeying the existing laws and regulations.
From the management standpoint, there are also differences to keep in mind.
As a project manager with over seven years of experience, I can confidently say that my first AI feature deliveries a few years ago were filled with uncertainty and stress. While I used to be able to manage complex and complicated software solutions with ease and joy, AI projects presented new challenges and unknown risks.
- A top-down approach doesn’t work for most AI projects. Instead, use a bottom-up approach for scoping. This is mostly due to the complexity of implementation and the possibility that some AI hypotheses may not work and will dictate the need for new features necessary for full implementation.
- While budget, time, scope, and quality are familiar constraints that project managers manage for traditional projects, AI project management requires paying attention to data management (including data privacy and security), infrastructure requirements, and regulatory compliance throughout the project lifecycle.
- AI projects have no definitive endpoint. I’ve encountered situations where AI engineers have suggested delivery timelines ranging from one month to one year, or even suggested that the project may never be fully completed. This is due to the fact that once a model is implemented, ongoing analysis of outcomes can reveal new points for improvement.
- Software development lifecycle for AI projects differs from traditional software development. On each step of the classic SDLC, there are additional steps that should not be missed. As a final step, we also have to deal with AI degradation as an extra part of work.
Nowadays, it’s more crucial than ever to effectively manage project budgets and timelines since budgets are tighter and business stakeholders are more demanding. In my opinion, the key factor for success is the ability to establish a project workflow that enables the attainment of both project and business objectives in a clear and predictable manner.

This leads to discussing the workflow of AI projects and their variations based on our experience.
How to Start AI Development
1. Business Analysis Stage
The business analysis stage starts with the general overview of the client’s input and vision that is further transformed into a set of documents that state the project’s aims and objectives.
Our main task on this stage is to understand whether we can address a specific business problem by using available data. Multiple people will be involved here to provide their vision for the idea, and give feedback concerning the implementation processes and possible outcomes. This is where the AI concept starts to form, including the names of specific approaches or even existing models.
For example, in the case of a restaurant or grocery chain, business owners are interested in reducing food waste and achieving a balance through the analysis of purchases and sales. For AI engineers, this task turns into time series prediction or a relational analysis task whose solution enables us to predict specific numbers. We have solved this problem through a thorough business analysis on one of our projects for the HORECA industry, so you can learn from our case study here.
2. Machine Learning Problem Determination Stage
The next stage is determination of the ML (Machine Learning) problem that should be discussed and solved. This must take into account the technological capabilities of Artificial Intelligence subfields, such as Computer Vision, Natural Language Processing, Speech recognition, Forecasting, Generative AI, and others.
Here, different approaches can be used. Generally speaking there are three main components to look for when discussing the actual machine learning solution:
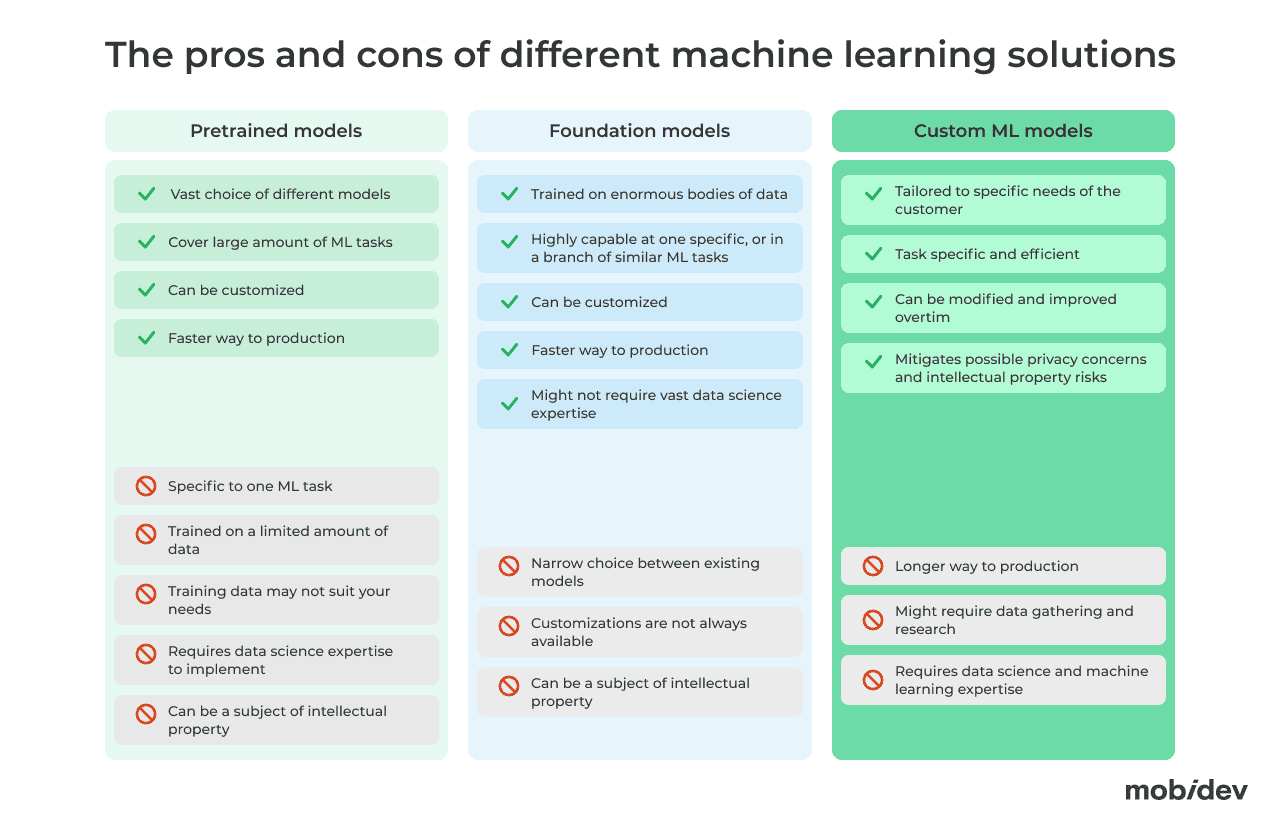
The pros and cons of machine learning model types
1. Pretrained models
These are the models that were previously trained to solve specific business problems on a set of collected data. Pretrained models can be trained on custom data and can be fine tuned to the desired output, which is a job for a data science team. MobiDev has broad experience with different types of speech processing, face recognition, demand forecasting, recommendation engines and other algorithms that were implemented into client’s products.
2. Foundation models
These emerged just a few years ago and they represent a model trained on enormous amounts of data. CHAT GPT is just an example of a language model that can be adapted to a wide range of downstream tasks. There are similar generative models that work with audio, video, still images, etc.
Foundation models are usually accessible through API, which provides customers with an already powerful machine learning module. Although, for domain-specific tasks, additional training is typically required. What’s beneficial about these models is that the integration process requires less involvement from the data science team if customizations are not required.
3. Custom machine learning models
Custom training offers the most flexibility among other options, since we can implement any functional variation and optimize the model to the customer’s tasks. The only serious challenge for custom development is the availability of data, which can be a roadblock for small businesses or start ups that don’t have a long operational history.
3. Data Sourcing
Data sources can be split into specific and general sources. If a company that plans to build an AI application has its own set of data specific to the machine learning task, this is the easiest scenario. However, more likely, the available data is not enough and we always have to think of a way to source additional data and enrich our training data sets. So let’s run through a couple of scenarios here.
Case 1. Existing business with corporate data
If you are a large company or a company with a long history, such as Coca-Cola, Walmart, Exxon Mobil, banks and insurance companies, then the data is actually a “by-product” of your production. This data is accumulated in the form of financial statements, employment statistics, information on deliveries, demand for your products, information on the operation of production lines, warehouse operation, and logistics.
This information can be used directly to make important decisions for your business. But your data can be even more valuable if used in conjunction with modern ML and AI algorithms. Such algorithms, for example, allow you to:
- Explore the market
- Explore your users and customers
- Assess loyalty
- Utilize churn prediction
- Predict market behavior
- Generate demand forecasting
- Help find marriage in products
- Utilize anomaly detection
- Provide visual inspection and defect detection
- Identify possible fraud
- Access anomaly detection
- Help users shop
- Provide recommendation systems
- Assess the risks of certain solutions
- Analyze credit risk
Case 2. Startups within an enterprise
In the case that you are a young business, and want to build your startup around an AI idea, then most likely you do not have data and you may not even know if you need it. In our long list of AI projects, startups within established companies are a large category of AI-enabled businesses that either made use of existing corporate data, or set up gathering mechanisms as soon as the idea for the product came in.
Case 3. Emerging startup
Where can you get data if you are a young startup and want to build your business around AI technologies? The answers to this question are known, and the list of possible options is not very extensive. In any case, collecting data will require both time and resources. Possible data sources are:
- Synthetic data. Lately, synthetic data is increasingly being used for training computer vision algorithms. Well-known game engines such as Unity and Unreal Engine are used to generate the data. AI solutions built on such synthetic data demonstrate results comparable to AI solutions trained on real data. Moreover, we have successful experience in creating and applying synthetic datasets to solve our clients’ tasks.
- Data purchase. As one of the possible options, you can consider purchasing data from companies that specialize in data collection.
- Ordering the creation of datasets. This is a fairly common method of collecting datasets. As an example, Amazon Mechanical Turk should be mentioned, which allows you to crowdsource the collection of your dataset.
- Self-collection. Using available resources, data can be collected by yourself even within your corporate resources.
- Web scraping. Yes, the well-known web scraping is mentioned here. It may seem boring, but just look at what modern computer vision or NLP models can do – like DALL·E 2 and GPT-3. And they were all trained on datasets collected from the entire internet.
- Data generation. This is the simplest but often the most unattainable option for a startup. Because in order for an AI solution to start working, data is needed. And to start collecting data, the AI solution needs to work. The circle is closed.
Data can be costly in and of itself, as it becomes a valuable resource. Depending on your domain, a dataset for sale can cost up to hundreds of thousands dollars, and its quality does not always correlate to the price tag. But on the other hand, the quality of data is also important, and there are several techniques to improve it.
4. Improving the data quality
Using just some data will never bring quality output. You can own data in large quantities, but make no use of it because of its poor quality and irrelevance, or an inability to process it. That’s why, once we find our data sources, we need to improve the quality of data before we can actually use it.
Poor quality data can be denoted by the absence or incorrectness of some parameters. For example, if you’re a credit organization, you probably gather the information of your customer’s marital status, age, education level, and many other parameters. Some part of data will have ZIP codes entered with errors, or education level fields left blank. On the scale of a dataset, if 50% of all data looks like this, it can be considered as poor quality and not suitable for machine learning tasks.
Irrelevant data, on the other hand, may be complete and correct in terms of data formatting. But it means nothing for your specific task. From the perspective of a credit organization, this can be the data about when the loan was granted, its amount, how it was spent, customer income level, etc. Such data is useful to determine whether your customer is going to repay the loan, but may be practically useless for assessing if they repay it in a given time period.
Partially, the issue with poor and irrelevant data can be addressed through corporate culture and by making data integral across the enterprise. Incomplete or inconsistent data can be generated just because of the silos set by technical problems.
To form a working data set, quality improvement procedures are required to form the most relevant input before the development stages. This can be considered as a part of preparation activities to check if we have the required resources available before we can move to development activities.

5. PoC development stage
The proof-of-Concept or PoC stage is basically the first step towards the working AI product. Because of the high level of uncertainty, we generally want to be sure our idea is realistic on the technical level, as well as in various business dimensions. With PoC, we basically achieve three important things:
- Idea validation. Since with PoC, we use real-world data and environment for experimentation, we can come to the failure point much earlier than would happen with MVP or AI software in production. This provides the team and the customer with a clear view of whether the chosen approach is working, what resources are needed to make it work on a scale, or whether other alternatives will suit better.
- Realistic estimates. After the PoC stage, it is much easier to estimate further development and provide accurate estimates and budget allocation.
- Cost effectiveness. PoC may save you huge amounts of money on development since the resources required for running an experiment are much smaller than creating MVP or functional prototypes. Vice versa, a successful PoC can be translated to a working product faster.
PoC is often seen as a basic step where we only need the input from the client and minimal engineering resources to start. However, we embrace the idea of combining the PoC stage with other components that allow us to progress through the project faster, and get more allaround output. So here, multiple combinations are possible depending on the project complexity and set requirements:
- Business analysis, technical architecture and UI/UX stages supporting further PoC development and MVP.
- Backend/frontend development, DevOps, etc combined with PoC.
Concerning the PoC process itself, we need to formulate critical metrics to measure the success of PoC implementation. A business owner may wonder whether the accuracy of the final software will be sufficient. An AI engineer isn’t always ready to answer this question since it could occupy a new niche. PoC comes to the rescue, showing the minimum accuracy that can be obtained. For example, a client with a restaurant business needs to reduce food waste. By transforming a business problem into a technical solution, we have reached the conclusion that we need to predict purchases, so metric MAPE (Mean Absolute Percentage Error), would be optimal.
The next point to be defined before starting with PoC are limitations. This is a non-functional requirement that could become clear later, during implementation. PoC must be based on one hypothesis and solve the particular task. Once the input has been prepared, the AI team works on PoC, metrics, measurement of the results coming up with a report of their findings. All these findings one way or another will lead to the creation of functional prototypes, demos, MVP, and eventually, final product.
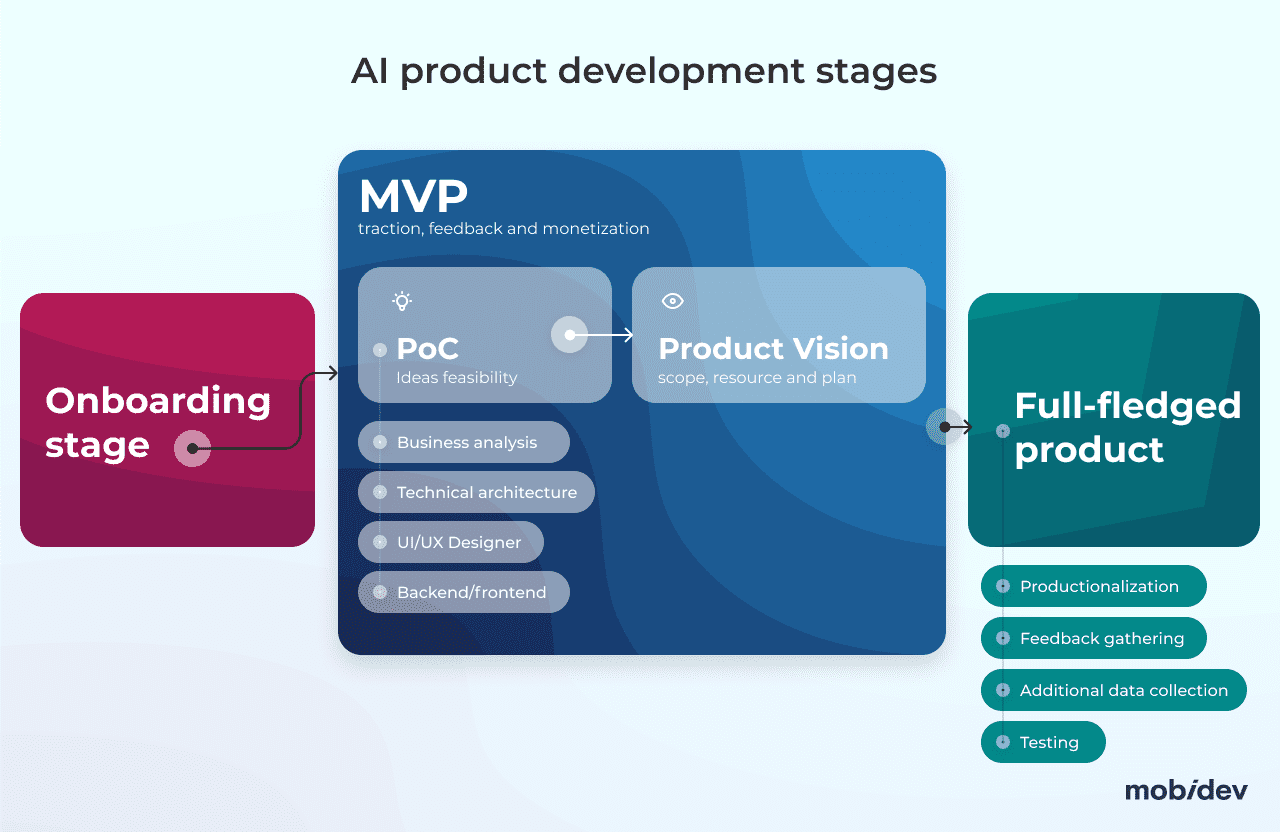
Inside the POC stage of AI product development
The PoC stage may come in several iterations if there is uncertainty or the client remains unsure about whether the project is moving in the right direction at the moment.
Further AI Product Development
At this stage, the estimates along with technical vision and metrics are provided to the client, and the team prepares to move forward with the development process, adding up other software components like front-end, back-end and others. From this moment, AI projects can move on like a usual software project through the stages of MVP development and rounding up the project. But here we need to discuss another aspect of AI app development.
AI Degradation
AI models set in the production environment will retain the quality of their predictions for some period of time. The accuracy will decrease over the time because the model will use data collected at the point of its creation. Thus, it will not take into account the changes that took place since its inception.
This is what’s called AI degradation, and this problem should be addressed continuously through retraining the existing model or creating a new one. For businesses that operate in less dynamic environments, managing model retraining once every a few years shouldn’t be a problem. However, imagine a business where the degradation of models occurs in a matter of weeks or even days, as is the case with demand forecasting, stock price predictions, etc. Even the sales dynamics of hot dog buns fall into the category of business tasks with a high rate of model degradation.
So that’s why we need to discuss the automation of data gathering and sourcing. Automation involves a separate ecosystem in which your AI model can operate to source data for retraining while operating in the production environment. These software components include:
- Databases
- Data streaming
- Automation of data processing and storage (data testing, ETL)
- Systems for collecting and analyzing data statistics
- Automated deep learning systems CI/CD for AI-related projects
To manage such an ecosystem, solid experience in machine learning and data science is required because it involves a lot of AI-specific tools that are not used in conventional software development.
Can You Run an AI Business Without data?
There are several AI business directions for which data is not necessary or not critical in the early stages of your business development.
The main idea of such startups is to deliver the most advanced AI capabilities to users in a convenient form.
Content generation
Recently, content generation has been actively developing, and startups are being built around business solutions related to delivering the latest AI capabilities for content creation and editing to end users. What can be generated?
- Images. Here, it is worth mentioning well-known examples like DALL·E 2 and Midjourney.
- Video diffusion models
- Mubert text-to-music or Google’s ToneTransfer models for generating sounds or compositions.
- 3D models and video game assets, for example Nvidia’s
- Texts, for example, the well-known GPT-3 model, GPT 4, Google Bard, Bing AI.
It should be noted that all these solutions, being ready for use, have been trained on a huge amount of data and perform only a general task.
In other words, even when using these ready-made solutions, your business will be based on data “hidden” inside these models. And here you need to understand that you have to rely on something (data, their structure, characteristics, collection sources, internal statistics) that you cannot control.
Using third-party services
Instead of deploying your own AI solutions, spending resources and maintaining their infrastructure, and having developers who will monitor this infrastructure and make necessary changes, you can use ready-made AI services that provide the necessary AI services for your needs. Such services include:
- OCR services. They will help you quickly extract important information from documents, such as credit card numbers, customer names, addresses, and etc., from documents sent in the form of images and photos.
- Speech-to-text services. They will help you process and transcribe, for example, phone calls, turning them into convenient text dialogues.
- Chatbot services, where you can create a chatbot for your needs using a user interface.
- Biometric authentication and verification services provide APIs that allow you to easily implement biometric authentication in your application/service without any hassle.
Advantages and Disadvantages of Working Without Data
Pros:
- Quick start
- No need to maintain your own infrastructure
Cons:
- Lack of competitive advantage compared to companies using the same approaches
- Inability to scale solutions when needed
- The need to rely on “hidden” data within models that you cannot control
Let’s take a closer look at an example of a well-known solution for generating images from text – stable diffusion (an open-source alternative to DALL·E 2 and Midjourney).
There is currently a tremendous demand for industrializing stable diffusion and creating custom image generation services. The number of such services is increasing every day, which means the price for using them will decrease. However, the cost of infrastructure supporting stable diffusion and similar solutions remains high and does not decrease. This brings us to the question of the survival of the business and the search for competitive advantage.
How can you gain a competitive advantage if your solution and your competitor’s solution are based on the same AI algorithms?
- Improved UI/UX (design and usability, performance)
- Enhanced marketing strategy
- Rapid community growth
- Customization and improvement of the AI model
For example, Midjourney follows the path of continuously improving their approaches and models, aiming to generate human features, faces, fingers, and all the intricate details of both the person and their clothing. All of this is based on the use of new data.
Thus, we can observe that once an AI solution becomes widely accessible, it quickly saturates the market and soon becomes unprofitable to industrialize. However, working without data can be a good starting point for young businesses and startups that do not have data yet.
Learn more about our AI application development services to see how we can meet your needs.


