

Contents:
Speech recognition targets at translating individual speech into a text format, to further process words and extract meaningful information from it. This can be used in various scenarios where UI is implemented with voice control features, or reacting to certain words with assigned actions is important. In this post, we’ll focus on the general approach for speech recognition applications, and elaborate on some of the architectural principles we can apply to cover all of the possible functional requirements.
MobiDev has been working with artificial intelligence models designed for processing audio data since 2019. We’ve built numerous applications that use speech and voice recognition for verification, authentication and other functions that brought value to our client’s. If you’re looking for tech experts to support your speech recognition project of any complexity, consider getting in touch with MobiDev experts.
How Do Speech Recognition Applications Work?
Speech recognition covers the large sphere of business applications ranging from voice-driven user interfaces to virtual assistants like Alexa or Siri. Any speech recognition solution is based on the Automatic Speech Recognition (ASR) technology that extracts words and grammatical constructions from the audio, to process it and provide some type of system response.
Voice Recognition vs Speech Recognition
Speech recognition is mostly responsible for extracting meaningful data from the audio, recognizing words and the context they are placed in. This should not be mistaken with Voice Recognition, which targets human voice timbres to identify the owner’s voice from other surrounding sounds or voices.
Voice recognition is used in biometric authentication software that uses user’s biometric data such as voice, iris, fingerprint, or even gait to verify the persona and provide access. The pipeline for voice and speech recognition may be different in terms of data processing steps, so these technologies should not be mistaken. Though, they are often used in conjunction.
If you are interested in biometric authentication software, you can read our dedicated article where we describe our practical experience implementing office security systems based on voice authentication and face recognition.

Which type of AI is used in speech recognition?
Speech recognition models can react to speech directly as an activation signal for any type of action. But since we’re speaking about speech recognition, it is important to note that AI doesn’t extract meaningful information right from the audio, because there are many odd sounds in it. This is where speech-to-text conversion is done as an obligatory component to further apply Natural Language Processing or NLP.
So the top-level scope of a speech recognition application can be represented as follows: the user’s speech provides input to the AI algorithm, which helps to find the appropriate answer for the user.

High-level representation of an automatic speech recognition application
However, it is important to note that the model that converts speech to text for further processing is the most obvious component of the entire AI app development pipeline. Besides the conversion model, there will be numerous components that ensure proper system performance.
So approaching the speech recognition system development, first you must decide on the scope of the desired application:
- What will the application do?
- Who will be the end users?
- What environmental conditions will it be used in?
- What are the features of the domain area?
- How will it scale in the future?
What is important for speech recognition technology?
When starting speech recognition system development, there are a number of basic audio properties we need to consider from the start:
- Audio file format (mp3, wav, flac etc.)
- Number of channels (stereo or mono)
- Sample rate value (8kHz, 16kHz, etc.)
- Bitrate (32 kbit/s, 128 kbit/s, etc.)
- Duration of the audio clips.
The most important ones are audio file format and sample rate, so let’s speak of them in detail. Input devices record audio in different file formats, and most often audio is saved in loosy mp3, but there can also be lossless formats like WAV or Flac. Whenever we record a sound wave, we basically digitize the sound by sampling it in discrete intervals. This is what’s called a sample rate, where each sample is an amplitude of a waveform in a particular duration of time.
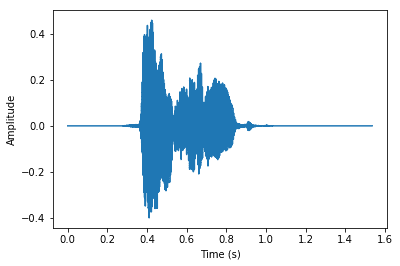
Audio signal representation
Some models are tolerant to format changes and sample rate variety, while others can intake only a fixed number of formats. In order to minimize this kind of inconsistency, we can use various built-in methods for working with audio in each programming language. For example, if we are talking about the Python language, then various operations such as reading, transforming, and recording audio can be performed using the libraries like Librosa, scipy.io.wavfile and others.
Once we get the specifics of audio processing, this will bring us to a more solid understanding of what data we’ll need, and how much effort it will take to process it. At this stage, consultancy services from a data science team experienced in ASR and NLP is highly recommended. Since gathering wrong data and or setting unrealistic objectives are the biggest risks in the beginning.
Automatic Speech Recognition process and components
Automatic speech recognition, speech-to-text, and NLP are some of the most obvious modules in the whole voice-based pipeline. But they cover a very basic range of requirements. So now let’s look at the common requirements to speech recognition, to understand what else we might include in our pipeline:
- The application has to work in background mode, so it has to separate the user’s speech from other sounds. For this feature, we’ll need voice activity detection methods, which will transfer only those frames that contain the target voice.
- The application is meant to be used in crowded places, which means there will be other voices and surrounding noise. Background noise suppression models are preferable here, especially neural networks which can remove both low-frequency noise, and high frequency loud sounds like human voices.
- In cases where there will be several people talking, like in the case of a call center, we also want to apply speaker diarization methods to divide the input voice stream into several speakers, finding the required one.
- The application must display the result of voice recognition to the user. Then it should take into account that speech2text (ASR) models may return text without punctuation marks, or with grammatical mistakes. In this case, it is advisable to apply spelling correction models, which will minimize the likelihood that the user will see a solid text in front of them.
- The application will be used in a domain area, where professional terms and abbreviations are used. In such cases, there is a risk that speech2text models will not be able to correctly cope with this task and then training of a custom speech2text model will be required.
In this way, we can derive the following pipeline design which will include multiple modules just to fetch the correct data and process it.
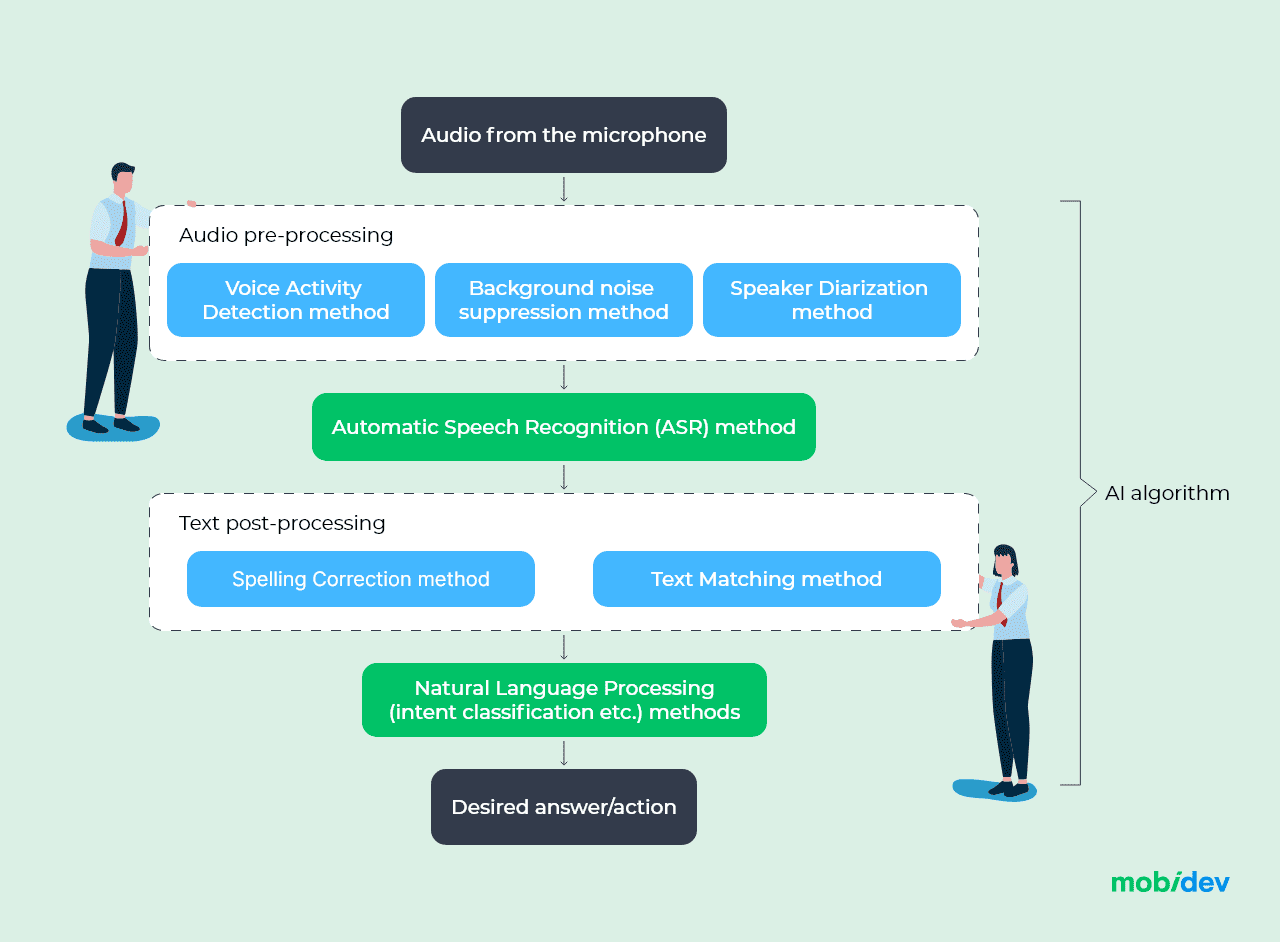
Automatic Speech Recognition (ASR) pipeline
Throughout the AI pipeline, there are blocks that are used by default: ASR and NLP methods (for example, intent classification models). Essentially, the AI algorithm takes sound as an input, converts it to speech using ASR models, and chooses a response for the user using a pre-trained NLP model. However, for a qualitative result, such stages as pre-processing and post-processing are necessary.
Basic implementation described here will be helpful if you already have a team with relevant experience and engineering skills. If you need to fill the expertise gap in specific areas of audio processing, MobiDev offers engineers or a dedicated team to support your project development. But if you don’t have clear technical requirements and struggle to come up with the strategy, let’s move on to advanced architecture where we can provide consulting, including full audit of the existing infrastructure, documenting the development strategy and running you through technical supervision if needed.
Our 4 recommendations for improving quality of ASR
To optimize the planning of the development and mitigate the risks before you get into trouble, it is better to know of the existing problems within the standard approaches in advance. MobiDev ran an explicit test of the standard pipeline, so in this section will share some of the insights found that need to be considered.
1. Pay attention to the sample rate
As we’ve mentioned before, audio has characteristics such as sample rate, number of channels, etc. These can significantly affect the result of voice recognition and overall operation of the ASR model. In order to get the best possible results, we should consider that most of the pre-trained models were trained on datasets with 16Hz samples and only one channel, or in other words, mono audio.
This brings with it some constraints on what data we can take for processing, and adds requirements to the data preparation stages.
2. Normalize recording volume
Obviously, ASR methods are sensitive to audio containing a lot of extraneous noise, and suffer when trying to recognize atypical accents. But what’s more important, speech recognition results will strongly depend on the sound volume. Sound recordings can often be inconsistent in volume due to the distance from the microphone, noise suppression effects, and natural volume fluctuations in speech. In order to avoid such inaccuracies, we can use the Pyloudnorm library from the Python language that helps to determine the sound volume range and amplify the sound without any distortion. This method is very similar to audio compression, but brings less artifacts, improving the overall quality of the model’s predictions.
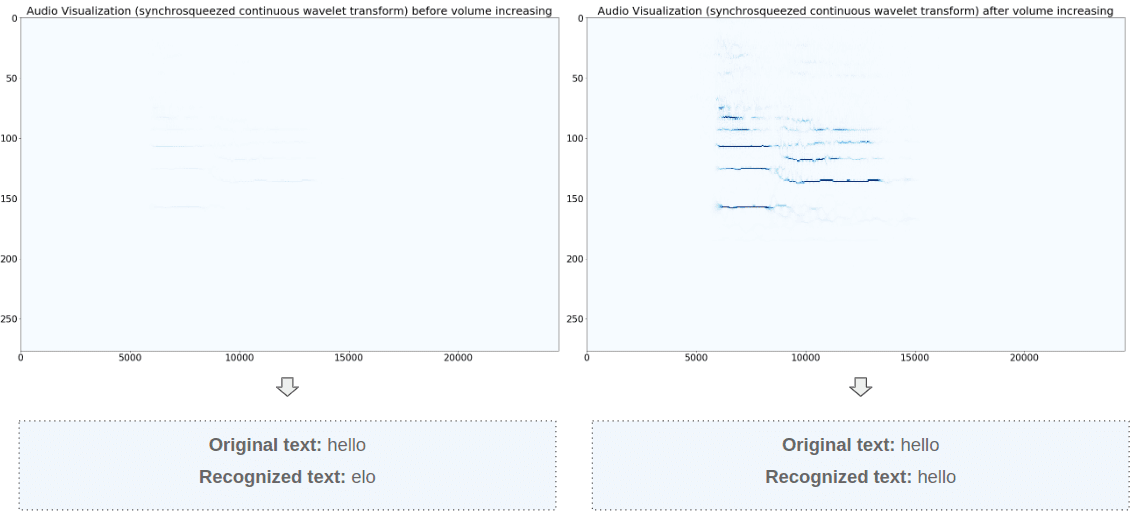
Nvidia Quarznet 15×5 speech recognition results with and without volume normalization
Here you can see an example of voice recognition without volume normalization, and also with it. In the first case, the model struggled to recognize a simple word, but after volume was restored, the results improved.
3. Improve recognition of short words
The majority of ASR models were trained on datasets that contain texts with proper semantic relations between each sentence. This brings us to another problem with recognizing short phrases taken out of context. Below is a comparison of the performance of the ASR model on short words taken out of context and on a full sentence:
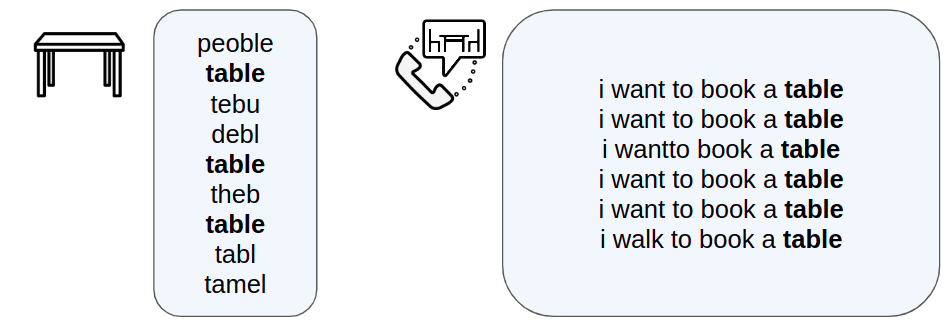
The result of recognizing short words in and out of context
In order to overcome this problem, it is necessary to think about the use of any preprocessing methods that allow the model to understand in which particular area a person wants to receive information more accurately.
Additionally, ASR models can generate non-existing words and other specific mistakes during the text to speech conversion. Spell correction methods may simply fail in the best cases, or choose to correct the word to one that is close to the right choice, or even change to a completely wrong one. This problem also applies to very short words taken out of context, but it should be foreseen in advance.
4. Use noise suppression methods only when needed
Background noise suppression methods can greatly help to separate a user’s speech from the surrounding sounds. However, once loud noise is present, noise suppression can lead to another problem, such as incorrect operation of the ASR model.
Human speech tends to change in volume depending on the part of the sentence. For example, when we speak we would naturally lower our voice at the end of the sentence, which leads to the voice blending with other sounds and being drowned out by the noise suppression. This results in the ASR model not being able to recognize a part of the message. Below you can see an example of noise suppression affecting only a part of a user’s speech.
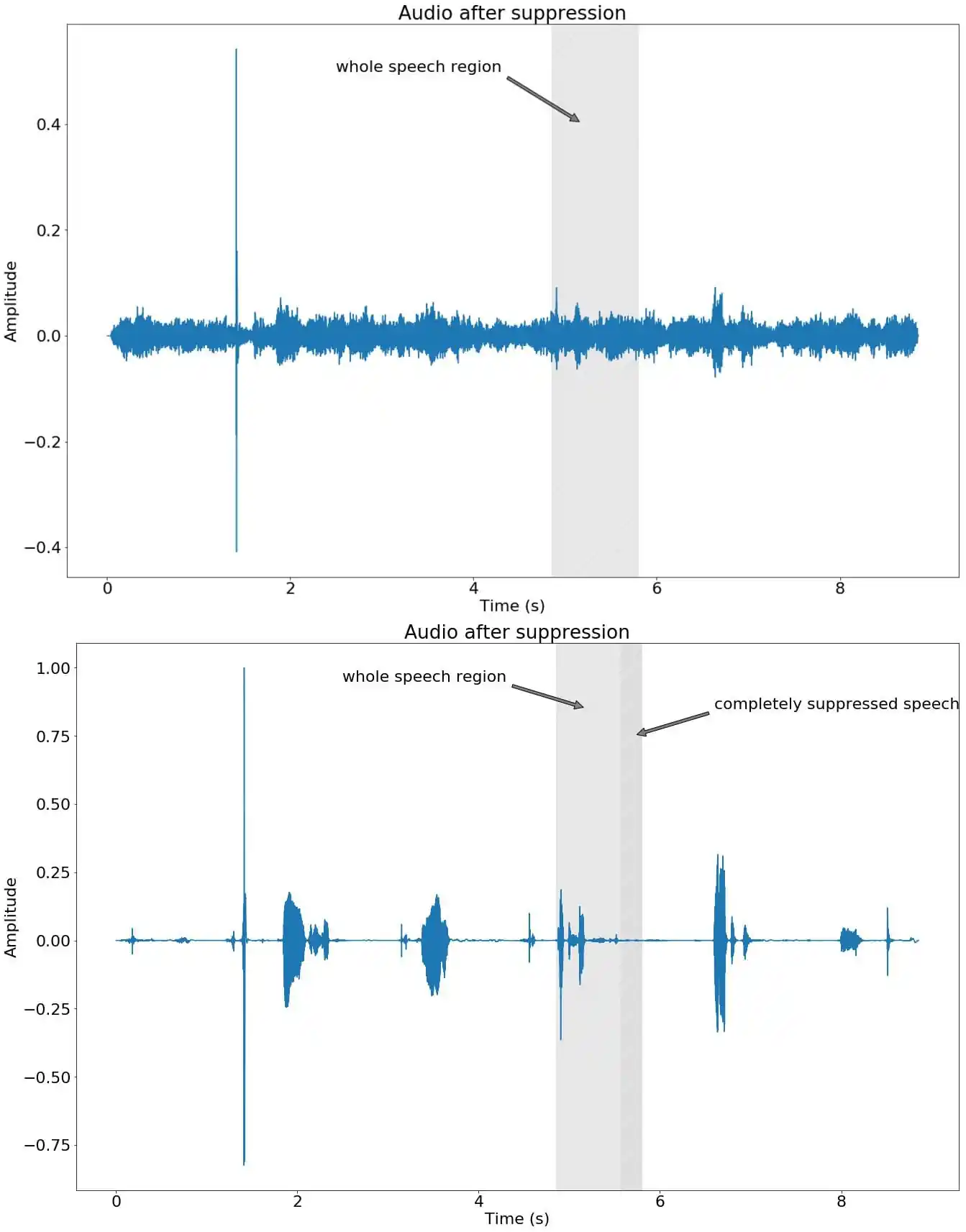
Noise suppression effect on the speech recognition
It is also worth considering that as a result of applying Background Noise Suppression models, the original voice is distorted, which adversely affects the operation of the ASR model. Therefore, you should not apply Background Noise Suppression without a specific need for it. In our short demo, we demonstrate how ASR model handles general voice processing, as well as with the application of noise suppression, so you can check how it looks like in real life.
How to Move On With ASR Development?
Based on the mentioned points, the initial pipeline can bring more trouble with it than actual performance benefits. This is because some of the components that seem logical and obligatory may interrupt the work of other essential components. In other cases, there is a strict need to add layers of preprocessing before the actual AI model can interact with data. We can therefore come up with the following enhanced ASR system architecture:
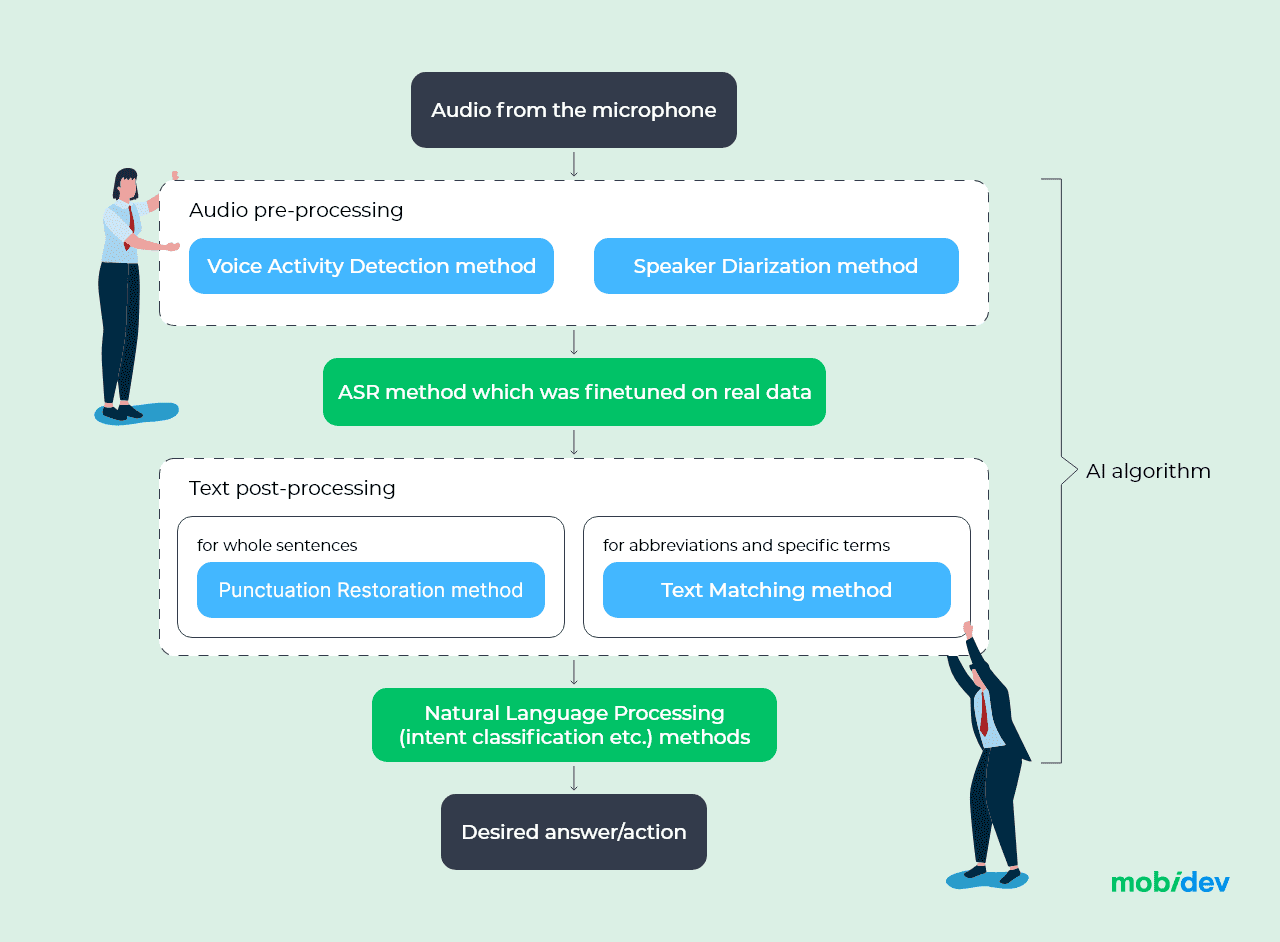
Enhanced automatic speech recognition system pipeline
That is why, based on the above points, noise suppression and spelling correction modules were removed. Instead, to solve the problem of removing noise and getting rid of errors in the recognized text, the ASR model has to be fine-tuned on the real data. This data will fully reflect the actual environmental conditions and features of the domain area.
While audio processing AI modules may seem easy to implement compared to computer vision tasks, and the amount of data required, there many aspects you need to learn about before hiring engineers. If you have troubles at the initial stages and won’t to move on without a clear development strategy, you can contact us to get concise answers to your questions, receive information on the preliminary budget and development timelines. MobiDev stands for transparent communication, so we product a list of artifacts such as technical vision and development strategy that includes POC stage to clarify the requirements with the client. Feel free to leave your contact through the contact form down below if you need AI consultancy for building robust speech recognition software.


