
Contents:
Summary:
Can a machine attempt to approach the task of creating unique content that would be indistinguishable from human-produced artefacts? Is it possible to do this with the help of generative adversarial networks (GANs) — by learning the structure of the complex real-world data examples and generating similar synthetic examples that are bound by the same structure? With the recent advances in the development of generative models, the answer seems to be yes, at least to an extent. It is proved by existing GAN applications.
In this article, we are going to take a deep dive into what the generative models are, the recent developments in the field, and the usage of GANs in business.
Main Principle of GANs
Let’s start with pretty basic stuff. The generative-adversarial network consists of two parts: generative and discriminative. The generative neural network creates samples, and the discriminative tries to distinguish correct samples from incorrect ones.
Just imagine GAN as a counterfeiter and a policeman competing with each other. The counterfeiter learns to make simulated bills, and the policeman learns to detect them. Both are dynamic. The policeman also trains, and each side comes to learn the methods of the other in a constant escalation.
In other terms, GAN is like a writer and an editor, or an artist and a critic who always interact with each other, improving their skills, as well as generative and discriminative models during training.
The primary purpose of both types of models is to be able to classify the new observations as belonging to one of the categories. Models receive a limited sample of training data (data includes a set of observations with known category membership) from a larger population.
The discriminative model can only tell what differentiates the two or more categories but is not able to describe the categories themselves. The model learns the conditional probability.
On the other hand, a generative model learns what the categories are (how the values are distributed in each category). It can be used to tell whether a certain value belongs to one category or another. This model learns joint probability distribution.
A nice illustration of the models, provided by Google (Fig. 1), shows this principle in practice – a discriminative model learns only the general threshold between the categories. Still, a generative model is more specific and learns where the boundaries of each category lie.
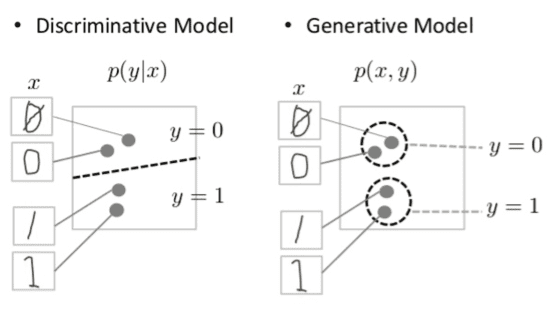
Figure 1. Discriminative and Generative Models of handwritten digits (source)
We will focus on the generative models, their ability to create new data samples, and how this can be used in practice.
Note: while GANs include both a generative and a discriminative model, generative and discriminative models can exist separately and be used for different tasks. However, only generative models are able to create novel data samples from the target distribution. As GANs are the prevalent type of generative models, we will pay them the most attention.
The concept of Generative Adversarial Networks was first coined by Goodfellow et al. in their now-famous 2014 paper [link]. The researchers proposed an unusual training setup (Fig. 2) where two networks, generator and discriminator, are pitched against each other in a competition. The generator has to generate fake images given random noise as input, while the discriminator has to discern between the fakes and the real images from the target domain we would like the model to learn (e.g. facial images). Over time, both networks progressively improve in their tasks, and one can obtain a trained generator model that replicates images from the target domain pretty well.
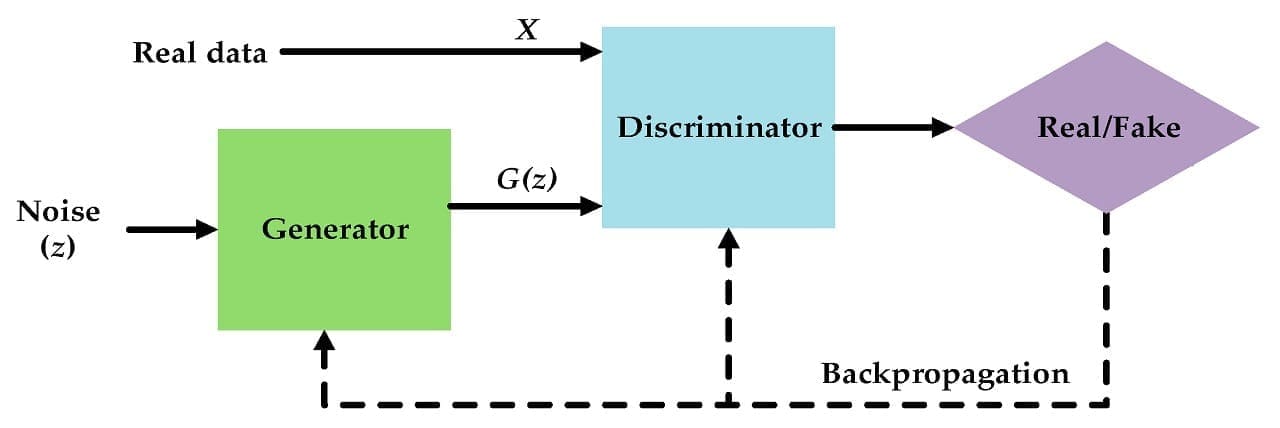
Figure 2. Schematic representation of a typical Generative Adversarial Network (source)
We have already found out the basic structure of GAN. So let’s move further to their possibilities.
What Can Generative Models do?
With the correct problem definition, GANs are capable of solving different problems while working with images, namely:
- Generating novel data samples such as images of non-existent people, animals, objects, etc. Not only images, but other types of media can be generated in this way as well (audio, text).
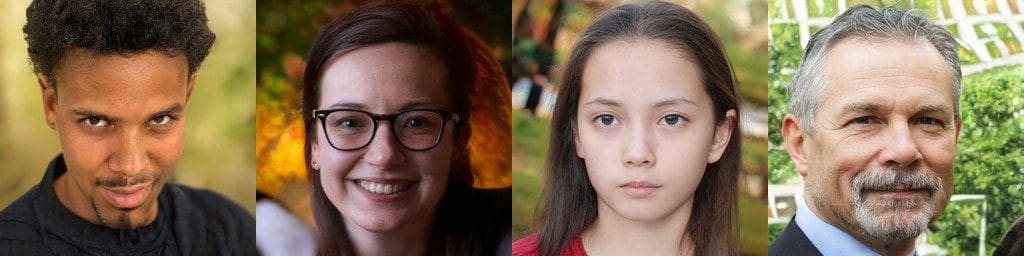


Figure 3. Examples of different images generated by GANs (source 1, source 2, source 3)
- Image inpainting — restoring missing parts of images.

Figure 4. Inpainting and restoring removed parts of images (source)
- Image super-resolution — upscaling low-res images to high-res without noticeable upscaling artefacts.

Figure 5. Upscaling image using GAN (SRGAN) in comparison with non-machine learning bicubic interpolation method and non-GAN ML method SRResNet (source)
- Domain adaptation — making data from one domain resemble the data from the other domain (e.g. making a normal photo look like an oil painting while retaining the originally depicted content).


Figure 6. Domain adaptation with GAN examples (source)
- Denoising — removal of all kinds of noise from the data. For example, removing statistical noise from x-ray images fits medical needs, which will be described in our use cases.
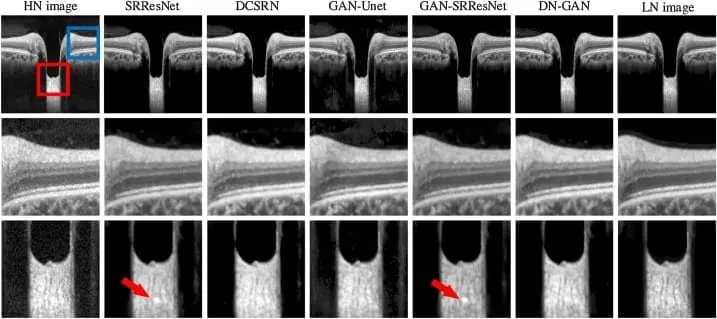
Figure 7. Removing noise from tomography images using GAN (source)
Besides the above-mentioned procedures, GANs are capable of a lot more. Creating data – from images to texts or even melodies – is just the tip of the iceberg. In the future, we might be the witnesses to great processes and the emergence of new GAN applications dedicated to the medical field, Augmented Reality, creating training data, etc.
GANs applications are able to solve different tasks:
- Generate examples for Image Datasets
- Image-to-Image Translation
- Text-to-Image Translation
- Semantic-Image-to-Photo Translation
- Face Frontal View Generation
- Generate New Human Poses
- Photos to Emojis
- Photograph Editing
- Face Aging
- Photo Blending
- Super Resolution
- Photo Inpainting
- Clothing Translation
- Video Prediction
- 3D Object Generation
Now is the best moment to implement GANs gaining from their abilities because they can model real data distributions and learn helpful representations for improving the AI pipelines, securing data, finding anomalies, and adapting to specific real-world cases.
Since we already know what generative models can do, it’s time to go further. Let’s find out examples of applications of GANs in different areas.
GAN Use Cases and Project Ideas
Moving on from theory and academic/non-academic research, let’s now take a look at where and how GANs are actually being used in business. It seems that while the research on the topic has been very active since 2015-2016, the practical adoption of these models are starting right now, and there are good reasons for this.
GANs already produce photorealistic images, for example, for industrial design elements, interior design, clothing, bags, briefcases, computer games scenes, etc.
Also, GANs have been used to train film or animation personnel. They are able to recreate a three-dimensional model of an object using fragmentary images and improve photos obtained from astronomical observations.
GANs application in Healthcare
The possibility of image improvement allows us to implement GANs in medicine for Photo-Realistic Single Image Super-Resolution. Why is this significant?
The reason for the high demand for GANs in healthcare is that images should fit particular requirements and be high-quality. High image quality can be difficult to obtain under certain measurement protocols, for example, there is a strong need to decrease the effect of radiation on patients when using low-dose scanning in Computer Tomography (CT, to reduce the harmful effect on people with certain health pre-conditions such as lung cancer) or MRI. It has the effect of complicating efforts to obtain good quality pictures because of the poor quality scans.
Super-resolution improves the captured images and can remove the noise quite well, however adoption of GANs in the medical area is quite slow as many experiments and trials have to be made due to safety concerns. When dealing with healthcare, it is mandatory to involve a number of domain experts to evaluate the models and ensure the denoising does not distort the actual content of the image in some way that could lead to an incorrect diagnosis.
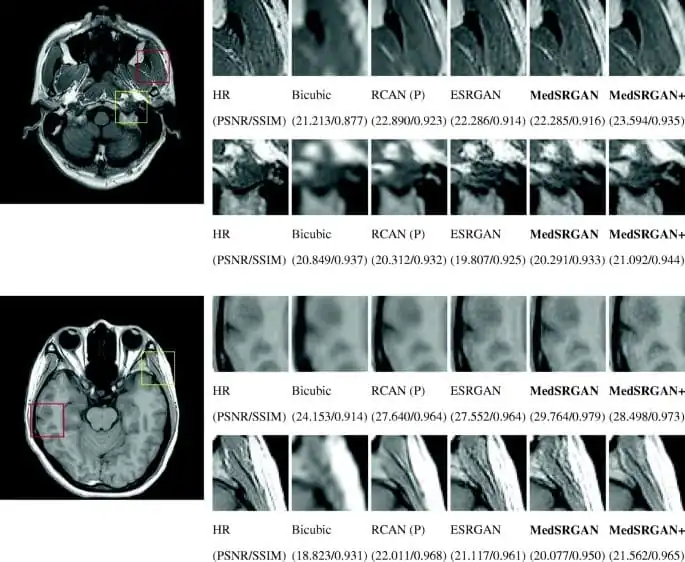
Source: Springer Link
Despite the enormous opportunities, GANs have issues. The biggest one is their instability. GANs are notoriously difficult to train, and sometimes these networks may generate images with artefacts because the models do not have enough information in the training data to understand how certain things work in real life. For example, given a dataset of portrait images, the network may know how to model human faces but may fail at grasping the idea of what particular elements of clothing must look like. So it is mandatory to carefully choose the data to be relevant to the expected result.
The general overview proves that the advertising and marketing industries have the highest GAN adoption rate. This is reasonable because promoting a certain product or service often requires the creation of unique but repetitive content, such as capturing images of photo models.
Read about the recent AI use cases in the marketing industry and how to use machine learning in marketing for business growth.


Figure 13 – Artificial faces generated from a real photo using Generative Photos (real photo source)
To address this opportunity, Rosebud AI has developed a Generative Photos app that makes heavy use of the recent advances in GANs. The application сreates custom images of fashion models that do not exist. This is achieved by using stock images of real models and replacing the faces with generated ones. The really interesting thing here is that you can swap the face for a generated one and customize the generated face in more than one way.
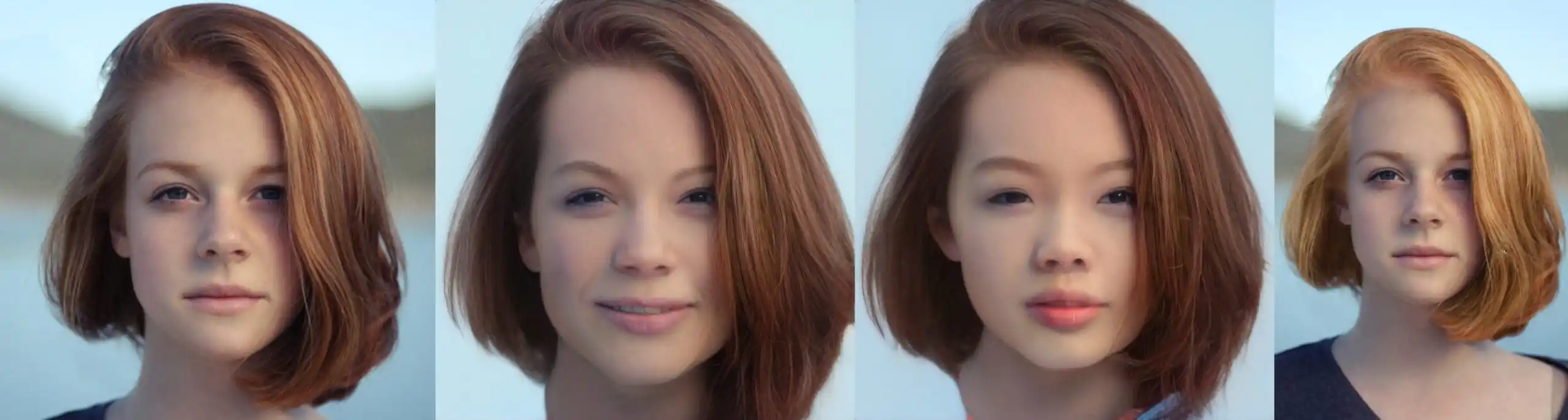
Figure 14 – Generated face customization (Source: Generative Photos). Left to right: original, adding smile and age, race editing, hair color editing.
Solutions like this often approach the task with the following steps:
- A face and its boundary box have to be detected in the image, which is a fairly common operation that can be done using existing face detection models.
- The detected face is cropped out of the image (there are different approaches to solving this task. One of them is considered in our research about background removal).
- A cropped face is projected into a latent space of the GAN model, and a similar face is synthesized by the model (inversion).
- The newly generated face has to be “transplanted” back into the original image. It can be accomplished with the FaceShifter model, or similar models.
Another curious piece of software by Rosebud AI, Tokkingheads app can animate any facial photo (synthetic or real) with audio or text serving an input (Fig. 15). The next technology step that GANs is allowed to make – is to not only generate artificial photos but to animate them and make them live.

Figure 15. Examples of synthetic facial animation – Tokkingheads app, Rosebud AI (source)
Generated Media Inc – this company applies the StyleGan model to create synthetic facial photos of varying ethnicity, age, and gender. While the generation process is nothing remarkable (the company mentions they use StyleGAN by Karras et al. and Nvidia), the interesting point is how the partner companies use the AI generated photos.

Figure 16. Synthetic faces from Generated Media Inc (source)
The use cases span a wide range of domains. It turns out synthetic faces are useful in the 3D graphics industry, where the 2D facial image can be converted into 3D models and used as assets for video games or animation (Video 1).
When it comes to the mobile app market, GANs are gaining ground there and primarily as an entertainment tool. Two particularly well-known apps of this kind, FaceApp (oriented at the western market) and ZAO (targets eastern market), provide users with original features — the ability to edit a person’s facial appearance or even swap the face of a celebrity in a video with their own faces.
FaceApp uses a face editing approach based on StyleGAN or a similar neural network. It can work with photos and videos, suggesting some modifications are made to ensure temporal consistency of the generated frames. If each frame in the video is processed by GAN individually, this will most likely result in “face flinching” artefacts, when the processed frames are joined back into a video. Thus an extra effort is required to make sure the frames smoothly transition from one to another.
It is worth noting that the computations required for this process are still too intensive to run the software directly on mobile devices. Therefore, the processing is done in a centralized manner on the company’s servers.

Figure 17. Face editing options – FaceApp (source)
GANs as a Service
Instead of finding a specific niche application for the models, some companies offer access to GANs and all the infrastructure and interfaces to handle the data, train the models, and obtain the final results.
Runway AI is one of such companies, positioning itself as a platform for Machine Learning and enabling novel content creation techniques. Generative media features, as the company calls them, are part of a web interface that supports training a GAN model on your own dataset and collecting the results in the form of images or even videos – it can be very useful for content creators and other interested parties as it helps bing the capabilities of GANs to the masses (working with GANs without graphical UI may prove too inconvenient for most of the non-programmer users).
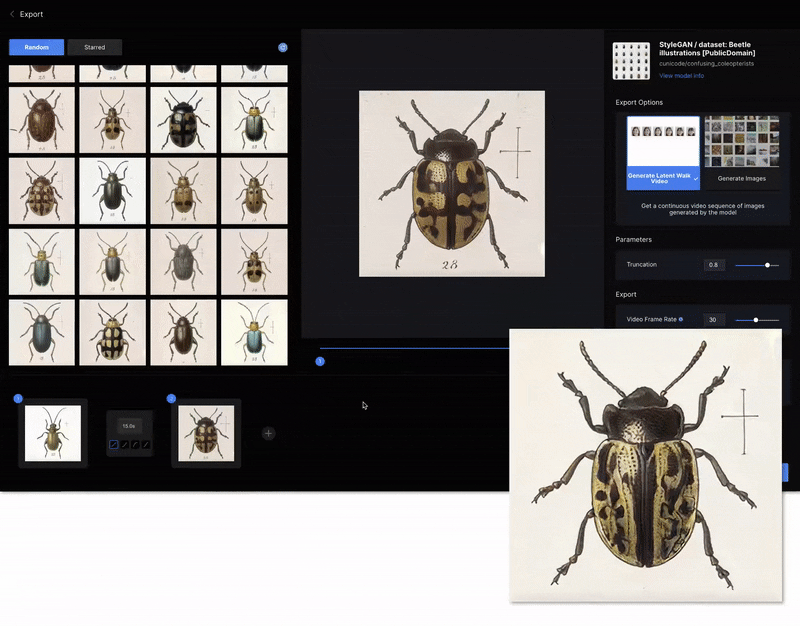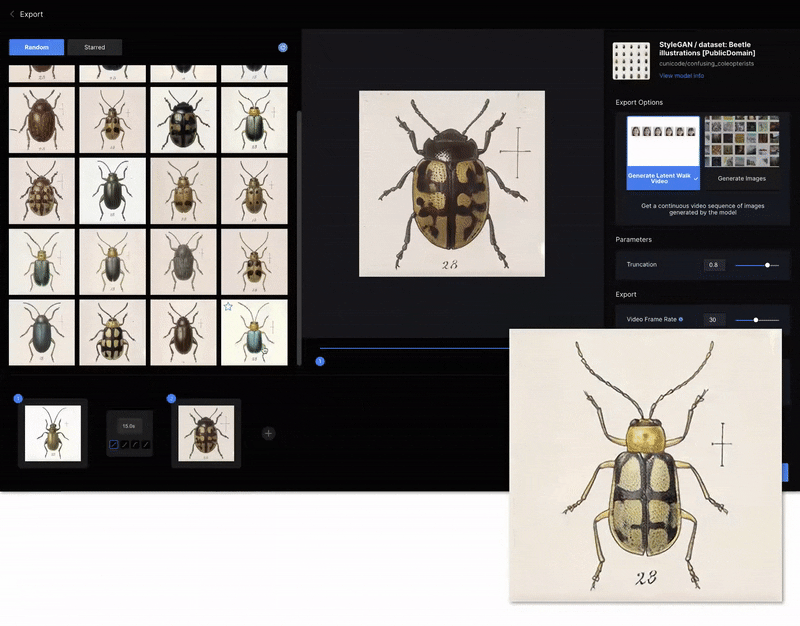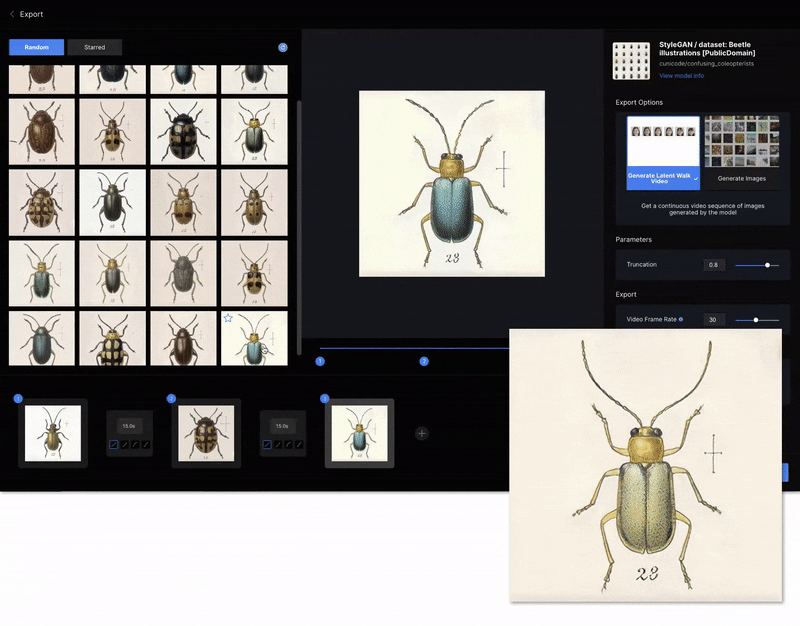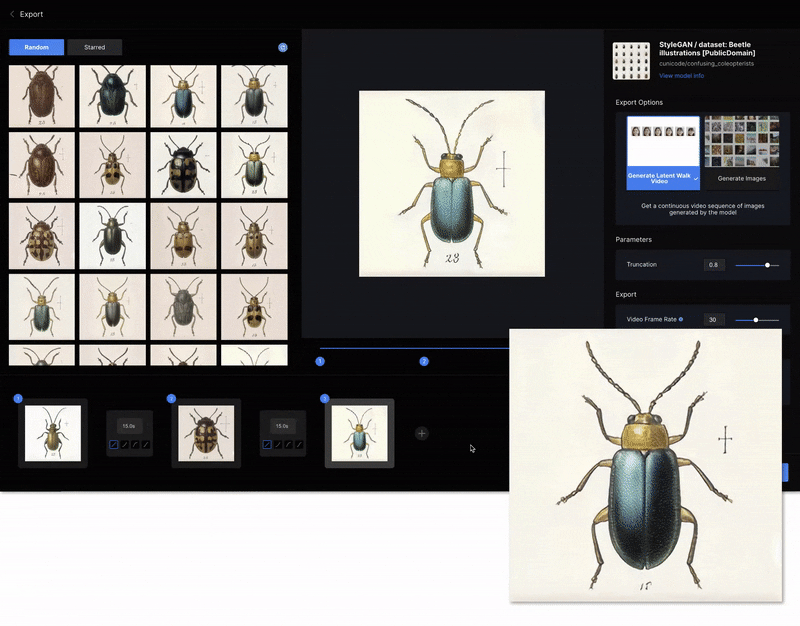
Figure 22. Interface for experiments with GAN by Runway AI (source)
GANs Technology AI for Dataset Generation in Computer Vision
It is not a secret that any Computer Vision Model (and to that extent any neural-network-based model) is hungry for data — the more data you have, the better the model you can potentially create. However, manually annotating data labeling for training is a slow and costly process. Many companies cannot afford it.
A possible solution (at least partial) can be found in the generative model domain — it turns out generative models can work as a tool for the synthesis of new labeled data samples based on a relatively small number of hand-crafted assets. This approach is taken by Israel startup DataGen that reported to have secured 18.5 mln USD of funding in March 2021.
The company focuses its efforts on closing the gap between the real and the simulated data so that the knowledge obtained from the simulated data could be used in real-world scenarios. To achieve that, the company first creates a database of 3D models tailored to a specific application area (e.g. 3D models of faces for face recognition) using 3D scanning or conventional 3D modelling technologies. After that, the initial 3D models (their 3D meshes, textures, and semantic information) are converted into latent space (a compressed representation that reflects all these features). GANs are applied to search and sample from this distribution, effectively creating new assets from the same domain as the original ones.
This approach seems very promising and will undoubtedly be adopted by more companies over time. The synthetic data opens a path to an entirely new range of possibilities in simulating very complex objects and environments while providing much more accurate annotations than the manual ones would ever be.
The simulated data gives us full control over the variance of the data (e.g., for human body models, we can select what races, body shapes, sizes, etc., we would like to have and in which proportions). We may be standing at the dawn of a new era for computer vision-intensive applications, such as robotics, self-driving cars, and virtual reality.

Figure. Synthetic hands models by DataGen (source)
Wrapping up with GANs technology
The more accurate and advanced GANs become, the more benefit businesses can get from them. The development of generative adversarial networks is easily traced thanks to new GAN apps. At the same moment, theory without practice is worth nothing. Therefore, we focused on our use case — logotype synthesis with Generative Adversarial Networks.
If you want to know how that worked out, read our research dedicated to GAN image generation. What value will you find there, and what actually was done?
MobiDev’s AI engineers used two data sources with images that were fed to StyleGAN2. Our goal was to train a generative model on this dataset to produce novel logotype samples. Also, we overviewed possibilities to enhance the diversity of the logotypes or give a designer the ability to “nudge” the visual style of one logotype in the direction of another logo.
Overviewing conditional image generation with GANs, we face obstacles related to the control outputs of the model. Anyway, the task of logotype synthesis was solved. Feel free to contact us if you need assistance with AI app development.


