

Contents:
Background removal and blur in a real-time video are in high demand in 2021. Their implementation can be comparable with the snowball effect. This avalanche will eventually sweep all platforms for video meetings. This fact is confirmed by the experience of market leaders that have already implemented such tools. For instance, Google has added Mobile Real-Time Video Segmentation to Google’s Broaded Augmented Reality Services. Microsoft Teams has also been using similar instruments since 2018. Skype introduced the functionality in April 2020.
Let’s try to dig deeper to understand the reasons for the growing demand for computer vision solutions, including real-time video background replacement and blurring. The statistics show the increased level of video meetings of all types: one-to-many, one-to-one, many-to-many.
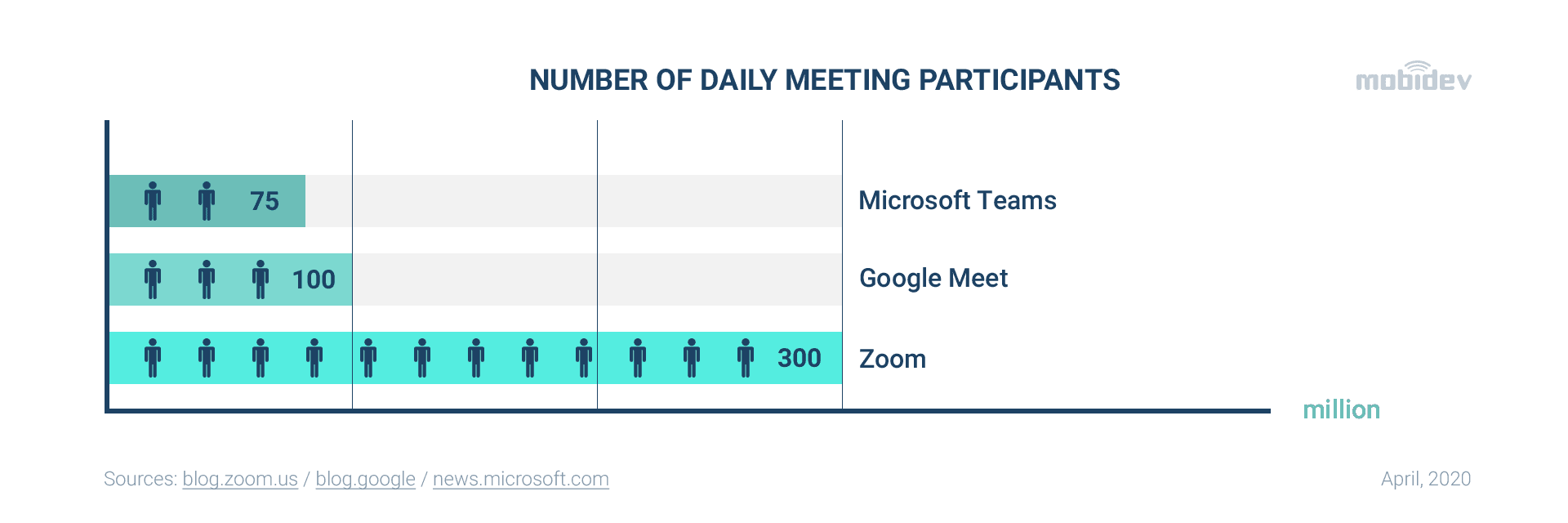
During meetings, the vast majority of participants pay special attention to how they look and what impression their environment gives. Background filters serve the purpose of hiding messy rooms and other inappropriate elements. Therefore, users prefer real-time video platforms that have tools for background replacement and blurring. Companies that provide users with such platforms and WebRTC video chat applications must include this functionality to remain competitive in the market.
Background Removal With Deep Learning: Main Approaches
Real-time human segmentation is the process based on face and body parts recognition; the main goal is achieving computationally efficient semantic segmentation (while maintaining a base level of accuracy).
Previously, real-time human segmentation was done with the help of hardware. In the past, it was also possible to apply dedicated software to this process. These technologies, as well as the Chroma-keying technique, are being gradually replaced by AI tools.
AI app development tools for background blurring and replacement in a real-time video differs depending on the applied approach.
In general, an algorithm of actions is as follows:
- Receive the video.
- Encode the video stream.
- Decompose the video into frames.
- Segment the person separately from the background.
- Replace pixels that do not depict a person with a new background or blur them.
- Decode frames in the video stream.
The main challenge is to create a system capable of separating a person in the frame from the background (item 4). If boundaries between foreground and background are clear, it’s possible to blur the background or replace it with a particular image. The process needs to be accomplished in the browser in each case. The real-time video must have high FPS, and be processed on the user’s side. At this stage, developers face the choice of how to solve the preset task.
There are three paths: use existing libraries based on neural networks without any changes, improve them with additional training, or build a custom model from scratch. Let’s overview the most significant among these paths connected to background removal with deep learning:
BodyPix
BodyPix is an open-source ML model. The neural network is taught to distinguish faces and body parts from the background. Processing takes place in the browser. The model is provided by TensorFlow.js – a JavaScript version of TensorFlow that relates to machine learning tools.
The neural network groups pixels into semantic areas of objects. Pixels are classified, making possible the differentiation between two classes: person and non-person.
The video stream is processed as a series of pictures. The base in the model is a mask consisting of a two-dimensional array of pixels. An indicator for each pixel is a float value that has a nominal range from 0 to 1. This value shows the confidence level (threshold). It helps to understand whether pixels represent the person. By default, if the value is over 0.7, it converts to binary 1s. Otherwise, it converts to binary 0s (pixels represented by zeros refer to the background).
In addition to the classification of person and non-person, the model can identify 23 body parts. The picture passes through the model. Each pixel gets an indication that identifies the part of the body. Pixels that form the background have value -1. Each body part can be indicated with the help of a unique color.
Look how BodyPix works in this demo.
When you choose BodyPix, take into account interrelated parameters of functionality that affect each other:
- Architecture: it can be MobileNetV1 or ResNet50. MobileNetV1 is suitable for mobile use or computers with lower-end or mid-range GPUs, meanwhile, ResNet50 architecture keeps up with computers that have powerful GPUs.
- Resolution of the frames: before the image is fed into the model, it is resized, so a higher resolution means better accuracy, but decreases work speed. Input resolution varies from 167 to 801.
- Output Stride: the output stride is 8, 16, or 32, it depends on the chosen architecture. A higher output stride increases speed, but decreases the accuracy.
- QuantBytes: weight quantization differs depending on the number of bytes, which is 4, 2, or 1. A higher number of bytes means higher accuracy.
- Multiplier: this refers to an optional parameter that varies from 0.5 to 1 and is foreseen only for MobileNetV1 architecture. This parameter describes the depth of the convolutional operations.
The first version of BodyPix is suitable for recognizing only one person, while the library BodyPix 2 works for multiple people.
It would appear BodyPix is an optimal model. It is quite flexible and open for commercial use (Apache License), but sometimes BodyPix doesn’t give enough FPS performance.
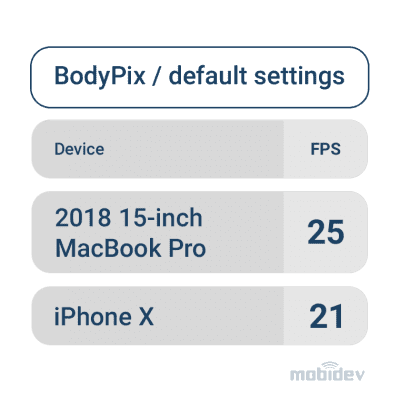
Source: TensorFlow Blog
MediaPipe
The MediaPipe is a kind of open-source framework that can be used in the preparation of ML solutions for a real-time video. It is open for commercial use (Apache 2.0 License).
Google Meet tools for background removal and blur in a real-time video are based on MediaPipe. For handling complex tasks in a web browser, MediaPipe is combined with WebAssembly. Such an approach increases speed because instructions are converted in the fast loading machine code.
Crucial steps include segmenting the person, preparing the mask with a low resolution, and improving this mask and its alignment considering image borders. When these tasks are completed, the model moves further. The video output is rendered, and the background is blurred or changed with the help of a mask.
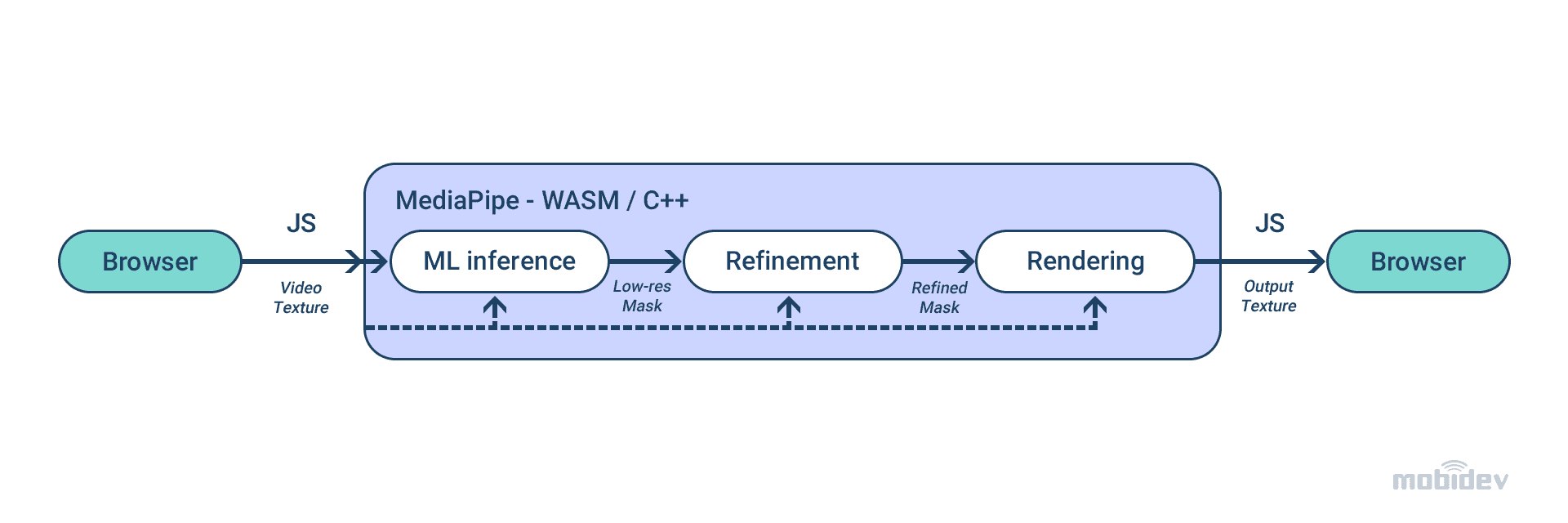
WebML Pipeline
The client’s CPU helps to execute the model inference. It enables the most comprehensive device coverage and reduces energy consumption. Additionally, the segmentation model is sped up through the XNNPACK library. This library accelerates the machine learning framework.
Mediapipe’s solutions are quite flexible. It means that the background replacement in real-time video corresponds with device characteristics. If it’s possible, the user has a top-notch picture. Otherwise, the mask refinement is skipped.
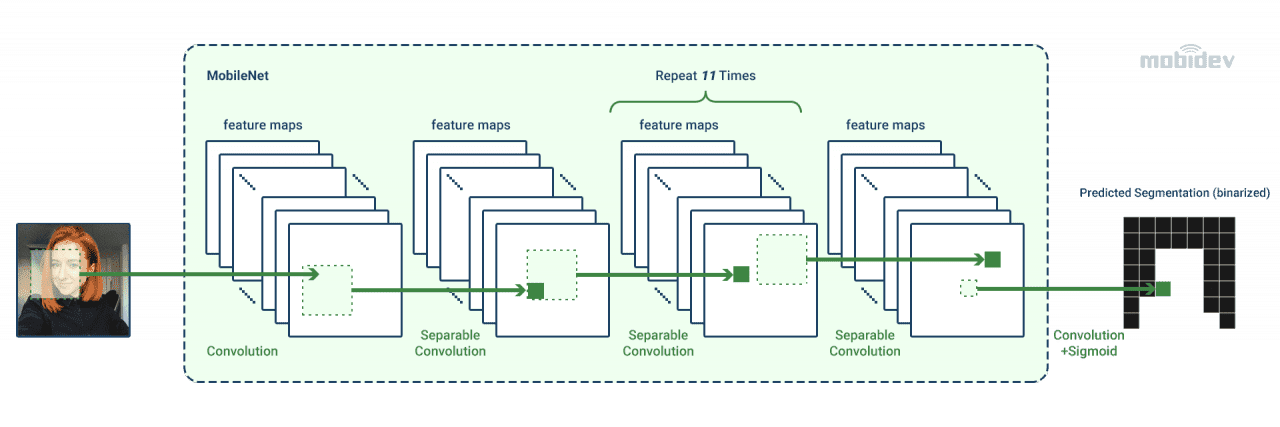
The ML model for segmentation must be lightweight, especially for running in the browser. The lightweight backbone allows reduced energy consumption and accelerated inference. The number of steps of frame processing depends on the input resolution. Therefore, we should down-size the image before integration in the model.
The main steps of the segmentation process are shown in the scheme below.
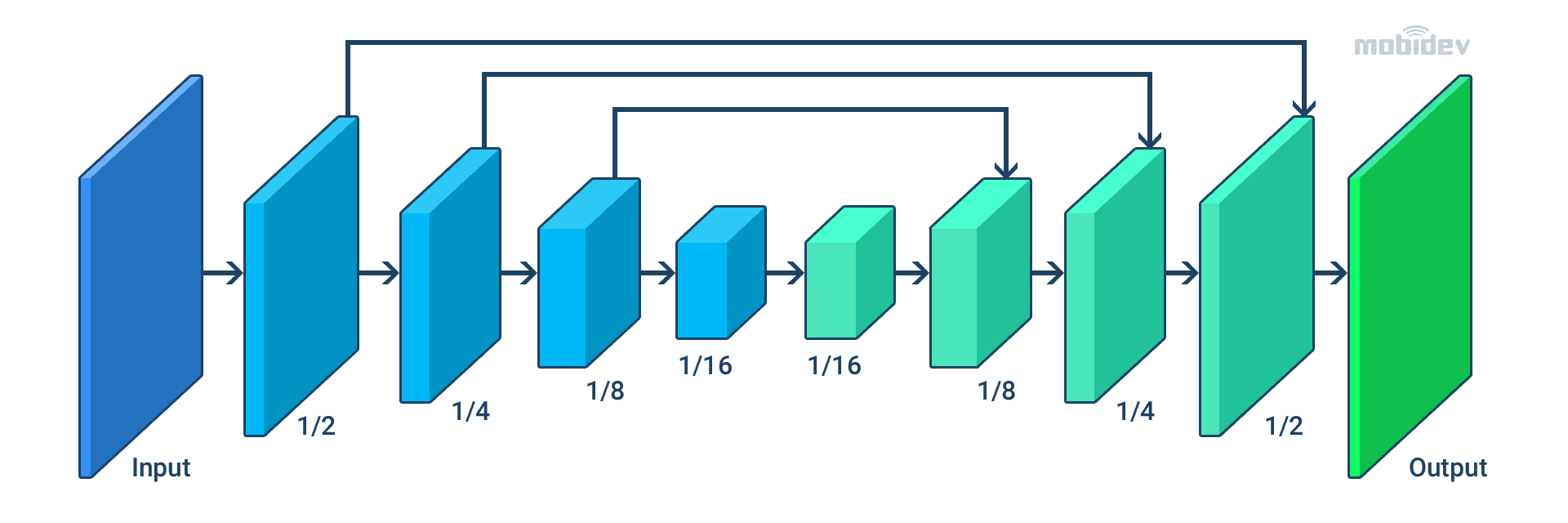
MobileNetV3 serves as an encoder. It helps to increase the performance while the resource requirements are low. TFLite reduces the model size by half. Also, the float16 quantization is applied. All this provides the tiny size of the model – 400KB. The total number of parameters reaches 193K.
When the segmentation is finished, video processing and rendering start. In this particular case, OpenGL helps to solve these tasks. After that, each pixel is blurred in accordance with the segmentation mask.
The technique of compositing named light wrapping is being implemented for real-time background removal and blurring. It blends a segmented person with the chosen background. Background light extends to the foreground to soften segmentation edges and minimize the number of halo artifacts. The contrast between background and foreground is getting less visible, which gives more realism to the real-time video.
User experience with blurring or changing background during a video call is related to the type of device and its hardware resources. We can use different devices and compare the speed of inference and the end-to-end pipeline. It’s also notable that background removal and blurring tools in Google Meet don’t even work if devices’ technical characteristics are lower than required. For example, if the device has less than 3 GB of RAM, or if the processor runs at a clock speed of less than 1.6 GHz, background removal and blur in Google Meet are unavailable.
More info about MediaPipe: https://ai.googleblog.com/2020/10/background-features-in-google-meet.html
The problem with MediaPipe is that released solutions have hidden initial source code. This can be quite risky for developing new models. There is no information about the data on which the model was trained.
PixelLib and other models
Background subtraction using deep learning can be implemented with PixelLib. It performs semantic segmentation. The library is useful both for video and image. PixelLib helps to separate the background and foreground. There are two types of Deeplabv3+ models available for performing semantic segmentation with PixelLib:
- Deeplabv3+ model with xception as the network backbone trained on Ade20k dataset, a dataset with 150 classes of objects.
- Deeplabv3+ model with xception as the network backbone trained on Pascalvoc dataset, a dataset with 20 classes of objects. It enables the removal and the creation of the virtual background.
There is a lack of information about how PixelLib and other models were trained. Therefore, they are used less often than MediaPipe or BodyPix.
Teaching a custom ML model
There are two ways to develop the ML model that will process the real-time person segmentation: build it from scratch, or use a pre-trained model like MobileNet, U2-Net, DeepLab, etc.
Training the model from scratch
We can use open sources like COCO dataset, Human segmentation dataset, AISegment, Supervisely Person, Automatic Portrait Segmentation for Image Stylization to train the model from scratch.
The model architecture can include a lightweight backbone like EfficientNet or MobileNet, with a reduced number of channels and a segmentation head. It could be trained, tweaked, and, most importantly, pruned to reduce the number of parameters while increasing the inference speed. In this case, to achieve the whole line’s high quality and speed, the next steps are mandatory: resizing and denoising the image, geometric transformations, fourier transform, etc.
When the training is done, the results performed with the help of Python and PyTorch can be converted to TensorFlow.js. This is because TensorFlow is a production backend for the applications. All preparations, which are done for the training, must be integrated into JS implementation.
Custom training that is based on the pre-trained model
You can use a pre-trained model as a starting point for custom training. For example, apply the pre-trained EfficientNet model. Below, you can see its comparison with other options.
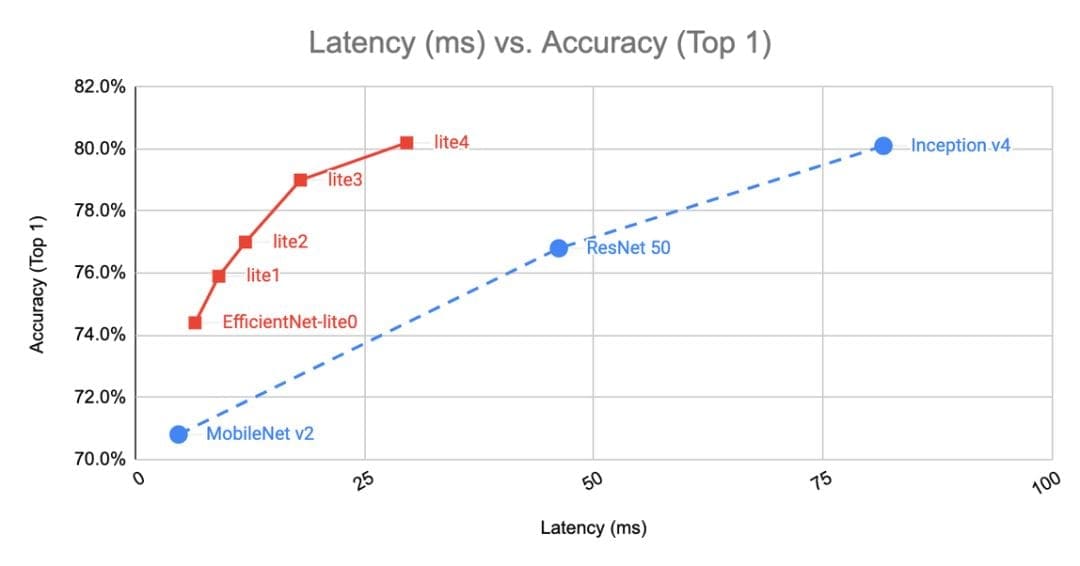
Models comparison. Source
According to research, developing a real-time person segmentation model from scratch isn’t the best option. It is useful only if we need to prepare the model adapted to a particular scenario, for example, detecting a headset. Anyway, all the peculiarities of the technology choice you can see below.
How to Choose The Suitable Background Replacement Technology For a Real-Time Video
In every case, communication platforms and apps must include a system capable of separating a person from the background and replacing the background with any image. The additional requirement is that the system should run in the browser with sufficiently high FPS for real-time processing and on the users’ side. The most suitable approach for solving this task is semantic segmentation via a deep learning model trained to differentiate between two classes: person and non-person.
Choosing a model must be based on objective parameters, considering the pros and cons of different approaches. Pay attention to ready-to-use solutions on Bodypix, as they are sensitive to browser selection. FPS can range from 40 in Google Chrome and 15 in Mozilla on the same device under identical conditions.
Alternative solutions on MediaPipe have hidden initial source code. Training a custom model can be expensive and time-consuming. The decision must be made with the help of previous research.
The algorithm for choosing the right technology for real-time background removal can look as follows:

The system can be improved in the future. For example, to increase the system’s performance, the models could be deployed in the native mobile app using Tensorflow Lite. This will almost certainly grant a speed boost, as Tensorflow Lite is better optimized compared to Tensorflow.js. For desktops with Intel CPUs, the oneDNN library can be used for speed optimization.
To sum up
The major challenge for background replacement in a real-time video is finding the optimal combination of performance, accuracy, and the right platform.
The most logical solution is to give preference to the pre-trained model paying particular attention to its combination with the framework and execution process in the browser (WebAssembly, WebGL, or WebGPU).
Approaches to the technology choice are clear, but the main question remains open. Where does it all go? Tools for video background replacement and blurring will become better thanks to custom solutions. For example, they can work faster, without lags, if we find a solution that handles frames rapidly and is compatible with the existing architecture.
To make the algorithm accurate, we need to improve the model with the help of additional data and more epochs of learning. It will help tools for real-time background removal and blur to prosper. The developing ML solutions will show the tremendous gains coming from the precise definition of dividing lines and layouts, high FPS, and fast, automatic choosing of the forefront object regardless of the color, texture, and quantity of shadows.
So, the avalanche that is mentioned at the beginning of the article has already started. Where will this go? Only time will tell.


