

Contents:
Document processing remains a burdensome task even in highly digitized environments because text-related data always comes in various formats that are difficult to organize. Utilizing AI can mitigate some of these challenges and facilitate the establishment of a data management process.
In my role leading the AI department at MobiDev, I have come across many cases related to intelligent document processing (IDP). For example, I have worked on AI data management for a healthcare insurance company for over four years. It taught me a lot. So I’m eager to share with you practical solutions leveraging AI techniques to adopt IDP in business flow more effectively.
BUSINESS DOCUMENT PROCESSING SYSTEM COMPONENTS
Automating paperwork with documentation involves a range of AI technologies that are used on different levels to extract information from physical documents, recognize the patterns and process text, improve data quality, and finally aggregate the data for analytical purposes.
For this purpose, documentation should be searchable and compliant with the industry standards which are critical in various domains such as healthcare, finance, insurance, and also meet legal requirements. This is achieved through implementing data privacy regulations like GDPR, HIPAA and other industry specific standards into the pipeline.
There are separate modules that perform separate tasks in a pipeline of document processing:
- Optical Character recognition (OCR) – is used to scan paper documents, and to recognize the layout and characters to transfer them into a digital format. An optical sensor is required to provide input for the model. Given that a single OCR model can operate within multiple cameras, it makes it easier to scale such a system unless the input parameters vary enough.
- Natural Language Processing (NLP) and language generation models like GPT apply to text analysis to recognize the structure of sentences and semantic relations. NLP components can grow quite large because they will perform a number of important tasks like:
– Document classification – which is based on different parameters like layout, contained information, domain, etc.– Data validation – is the process of validating the extracted data if it accurately refers to the original source via techniques like reference data checks, pattern matching, and statistical and contextual analysis.– Layout and entity recognition – or breaking your data down to the layout section and recognizing entities that are meaningful to operations, such as client name, address, phone number, insurance number, etc.
– Data quality improvement – as a process of enhancing the accuracy, completeness, consistency, and reliability of the data extracted. Some of these procedures can be handled via unsupervised learning, such as standardization and deduplication, while error handling and compliance adherence should be applied manually.
- Analytics and insights – which can use any type of interface like business intelligence, separate dashboards, or a simple query bar for dragging required documents from the database. Although, analytical systems can be a large module in itself, because they can entail a number of algorithms for demand or sales forecasting, predictive models, and visualization graphs.

Organizations like banks, insurance companies, real estate agencies, hospitals, and transportation companies can suffer the most from inefficient handling of paperwork. Since OCR and NLP models have become more widespread, the adoption of intelligent document processing is now accessible to mid-sized and smaller companies.
Now, let’s run through some typical examples of document types that can be processed with such systems.
WHAT BUSINESS DOCUMENTATION CAN BE AUTOMATED WITH AI?
Documents vary in type, and generally even simple invoices will differ in their layout and entities. However, OCR paired with NLP can solve quite complex tasks given that we have enough data with decent quality. For those types of projects, we generally don’t expect issues with the training data amount, since operational documents are produced as long as the company operates and these samples can be used for training purposes.
Now that we have a general representation of the automation pipeline, we also need to clarify which type of documents can be processed in this way:
- Invoices used in accounts payable and invoice processing workflows
- Purchase orders & receipts
- Contracts with all included entities like clauses, dates, parties involved, and contract terms
- Shipping and delivery documents like waybills and packing slips
- Tax Forms
- Legal documents such as case files, court documents, and legal agreements
- Healthcare records like patient records, insurance claims, and surgery documentation, drug recipes, etc.
- Insurance documents such as claims, policy documents, and customer inquiries
- Real Estate documents such as property records, contracts, and lease agreements
- Utility bills
- Identity documents such as passports, driver’s licenses, and identity cards
We also had experience with the automation of complex document types like engineering drawings and manufacturing blueprints. This type of documentation requires a custom approach to development since there are few models that can recognize engineering patterns and extract entities that are domain specific to machinery used in 3D printing, CNC, and other aggregates. If this is something of interest for you, you can read our dedicated article to learn about the techniques and methods used to process this type of documentation.
OCR for Engineering Blueprints
Read the GuideHowever, any type of document has a similar set of techniques that allows you to analyze what’s included on a paper, and extract required entities so they are correct, searchable, and structured. So let’s also discuss what data manipulations are needed to ensure smooth and secure document processing with AI.
AI DATA MANAGEMENT PIPELINE EXPLAINED
Let’s break AI-driven intelligent document processing down to several stages, and see what operational algorithms can handle either to preprocess, or improve the quality of data. Our zero step is the process of document collection from various sources like scanned documents, PDFs, emails, etc. Data-wise, documents used for business purposes are considered semi-structured or unstructured data. This is also not consistent across sources and organizations, and differs between document types. Here we move on to data processing.
STAGE 1. DATA PREPROCESSING
Data preprocessing includes numerous operations that are meant to improve the quality of a document sample before it is fed to OCR and NLP models. The main operations done at this stage are:
- Deskewing — which is basically a correction of angle for the scanned image, and achieving a consistent angle across different scans.
- Denoising — removing visible artifacts such as grain, uneven contrast, light spots, scanner defects, or any other physical and digital defects.
- Binarization — converting the image to black and white.
- Cropping — or framing the image.
STAGE 2. DATA STRUCTURING, CLASSIFICATION, AND LABELLING
At this stage, AI algorithms will inspect, evaluate and classify data, adding labels to important fields and recognizing entities. Different fields can be combined into entities that make sense for each specific business task.
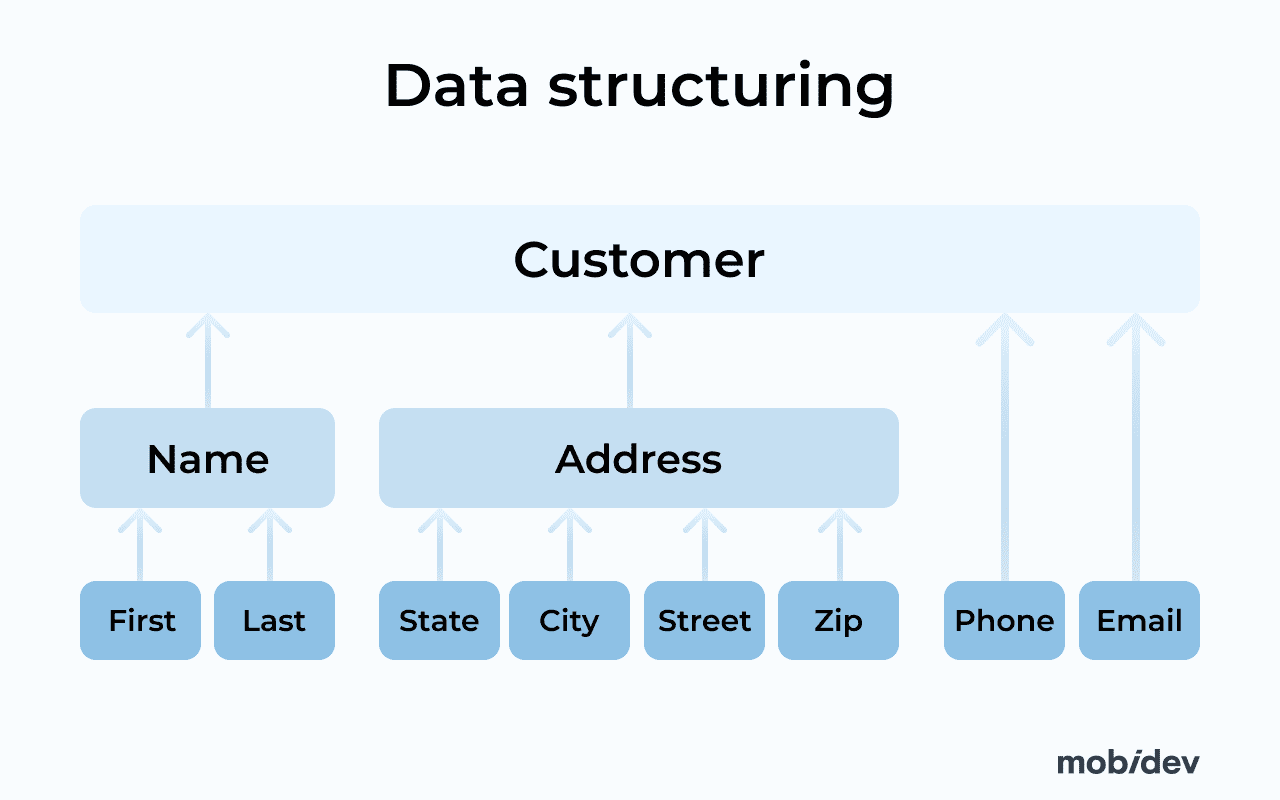
One of the most important aspects is data normalization. This is the stage when we transform the data to bring it to some common format, or change the way it is written in the database to make it easier to access. Take for instance, such a common entity as an address that is important for various types of businesses. Addresses are often entered with mistakes and inconsistencies between the samples.
One sample may look like this.
Address Line 1: Apple Park Way Building One
Address Line 2: Floor 1
City: Cupertino
State: CA
Zip code: 95014
While the other can look like this:
Address Line 1: 1 Apple Park Wa
Address Line 2: –
City: Cupertino
State: CA
Zip code: 95014
The same address can have different variants of writing, have omitted lines, and mistakes. So the task is to match the format between different samples, fill in missing data, and remove inconsistencies. Normalized data should be easy to search or use for other purposes like forming reports, filtering data, etc.
Duplicates and overlays in databases are another severe problem applicable to most organizations. Incorrect synchronization of information leads to difficulties with operational activity. For instance, medical, insurance, and real estate records are often recorded with misspellings, inconsistencies, and duplicates. AI can be applied to resolve these issues, firstly training on synthetic data, and then extending to actual operational documents.
There are also cases when the data could be partly stored in external databases (3rd parties), not owned by the organization. Companies could create an “on the top” software layer when there’s no possibility of interfering with the data at its core. So after getting the data from its source(s), cleaning, structuring, and other operations could be used on the client’s side.
Let me give you an example of how it can work in practice. At MobiDev, we worked with a client who operates in the US healthcare sector. They faced challenges searching for similar medical cases across different national and local databases. Due to data inconsistency, it was hard to correctly identify the patient with a certain medical case. Without an identifier shared by all facilities, health institutions suffer from the violation of patient safety, data integrity failures, and medical identity thefts – all consequences of ineffective master data management strategy.
To address these challenges we created a system that synchronizes records with proven registers, and automatically normalizes patches of data mapping different entities between each other so that the data remains searchable. Those patches of data that miss some entities are set into a separate category to be reviewed and filled up, and further reapplied to the system to process.
STAGE 3. DETECTING DATA ANOMALIES
There are plenty of ways the data could get corrupted, and in some cases, an algorithmic approach is not enough. So an AI-based algorithm for anomaly search could be performed. It allows for determining data entries that match formal data criteria but are still somehow different from the data patterns in a certain dataset.
The origin of the deviation could highlight incorrect data, as well as appeal to a business process itself. So after AI evaluation, a data analytic should join to validate the results.
The process of data validation can be a separate step in the overall flow. One way or another, it will require the involvement of a human expert to validate the extracted data and make manual corrections, since there might be domain-specific factors that impact the quality of data.
STAGE 4. GETTING INSIGHTS FROM DATA ANALYTICS
As a final destination for our data, once normalized and validated documents are ingested into the database, they need to be accessible to the right parties in a suitable format. This breaks the analytical component into multiple important aspects:
- Integration with databases — as a part of engineering tasks to settle the connection between different databases and end-user interfaces
- Access policies — are required in case analytical software is provided to employees at different levels, to set the limitations for accessing required data layers
- Analytical functionality — which can range from simple querying that returns an excel to the user, to customizable dashboards that source data in real time and turn them into visualizations, or automatically compile data into reports on a weekly/monthly basis.
Analytical software is usually a separate project under the digitization/document processing automation umbrella. However, if you aim to bring maximum value to your automation of paperwork, aggregating data to make it more accessible is a logical step. Since in most cases, the absence of a user interface that presents the insights to required parties will lead to lower ROI for such projects.
However, there are alternative solutions that are based on NLP capabilities that allow an end user to enter queries in spoken language to search through data. This is what’s called an NLP recommendation system and can be applied to different tasks that require a search system to understand the context of human speech and tolerate inaccurate sentences. You can watch our short video that shows a demo of NLP-based search engines and how they work in practice.
WHY DEVELOP A CUSTOM INTELLIGENT DOCUMENT PROCESSING SYSTEM?
The market of automation technologies is full of different solutions tailored to document processing as well. However, it is important to understand that vendors who propose platforms for document processing as a SAAS solution, may have a lot of restrictions such as formats and amount of data they can accurately handle, security concerns, and scalability issues.
If you deal with large amounts of paperwork that need to be managed digitally, and a large amount of these documents are unique, it’s better to go with a custom solution. NLP and OCR modules trained on your specific data will do a better job at extracting valid information while maintaining better control over your general data flow.
Another important aspect is that custom solutions can be integrated with other software components more seamlessly, offering a robust and secure ecosystem for data transmission.
How MobiDev Can Help You
MobiDev has 6+ years of experience in developing AI applications and 14+ years of expertise in software development overall. During this time, we have developed an effective framework for integrating AI into various business verticals to help our clients create the most effective solution to meet their business needs. MobiDev’s AI product consulting services aim to reduce the uncertainty associated with developing AI solutions, manage risks, and optimize costs.
Feel free to reach out to us through your preferred channel to discuss your business goals and explore how we can accelerate your progress toward achieving them.


