

Contents:
Recommendation systems built with machine learning can solve one of the most tedious tasks of gathering customer data, which is to study their preferences and suggest relevant information in the future. Besides searches, recommendations, or what’s also called discovery, provides customers with an endless stream of information that is relevant to their search history, preferences, and which generally helps them to find what they want much faster.
Machine learning recommendations are based on keywords, user activity, and other similar measures that help us define what a person may like. But they become ineffective if the user preference involves thousands of filters and subjective criteria that are specific to the user. So here, we discuss Natural Language Processing recommendation systems. Based on our previous experience, we’ll outline the general idea and limitations of this model, and explain some of the best approaches for how to build a NLP-based recommender system.
How do NLP-based Recommendations Work?
Natural Language Processing, or NLP, is good at handling plain text and colloquial speech. You can find tons of sentiment analysis or intelligent document processing cases that rely on NLP to solve the task of working with written language. These capabilities can be applied to recommendations as well, if we understand our inputs and outputs right.
Any recommendation system performs a basic function for a user. It matches user expectations with the discovered content, no matter if it was an intended request or not. Recommendations are formed by learning the previous activity of the user, and assigning categories to the content pieces that we call “filters”.
It is a known fact that the input of any AI model is numeric data. Obviously, when it comes to data such as the age of a user or years of experience, AI models can easily operate with these values. To work with this type of data, it will be necessary to follow the steps according to the CRISP-DM methodology, namely, analyze the data, understand how best to transform it into a training format and perform the conversion. Think, for example, of a professional network like LinkedIn where a user applies filters to search for a career opportunity.
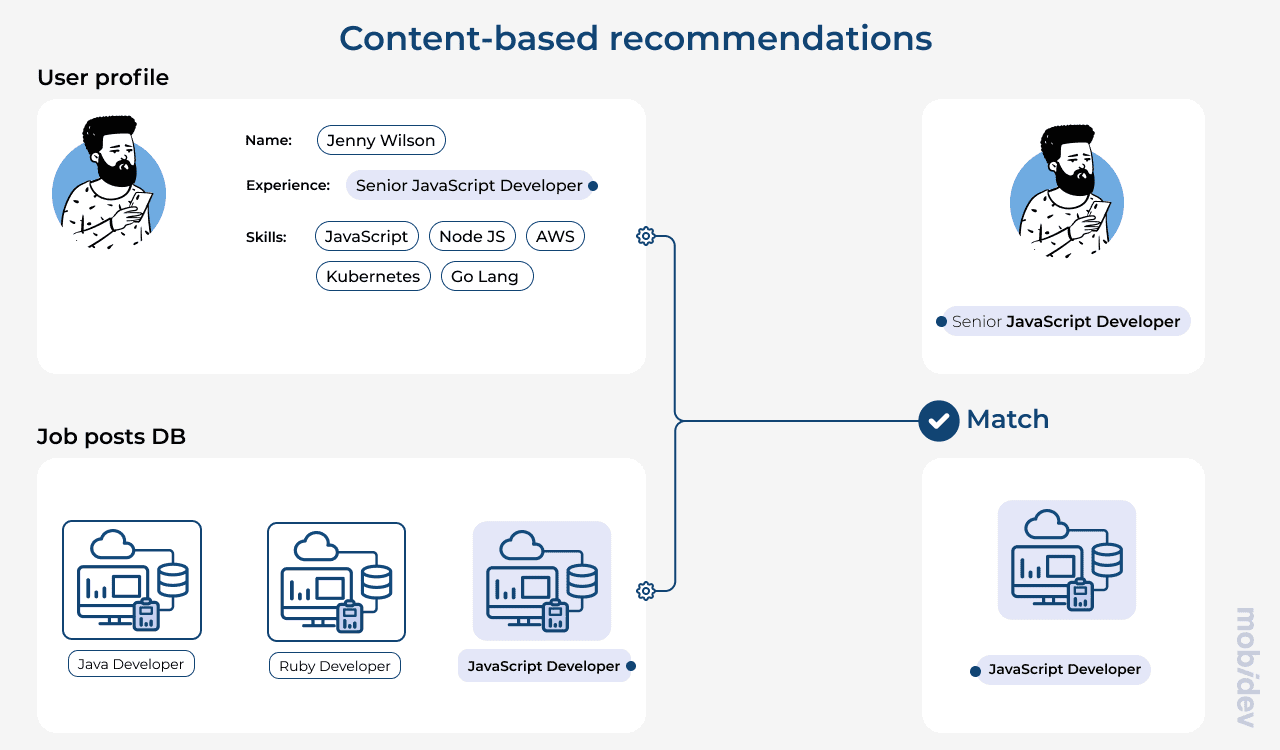
Basic recommendations using content-based filtering for job search
But, how can we handle text data? How can we convert words into numeric data? Descriptions, commentaries, and colloquial speech messages can specify data points like years of experience with a specific technology that may be crucial for correct matching.
NLP methods can help the user to provide search input in a free form and without any restrictions, according to the system’s requirements, to get an answer to the desired request. Text information can store a large amount of data that cannot be covered by ordinary filters, as in the example above.
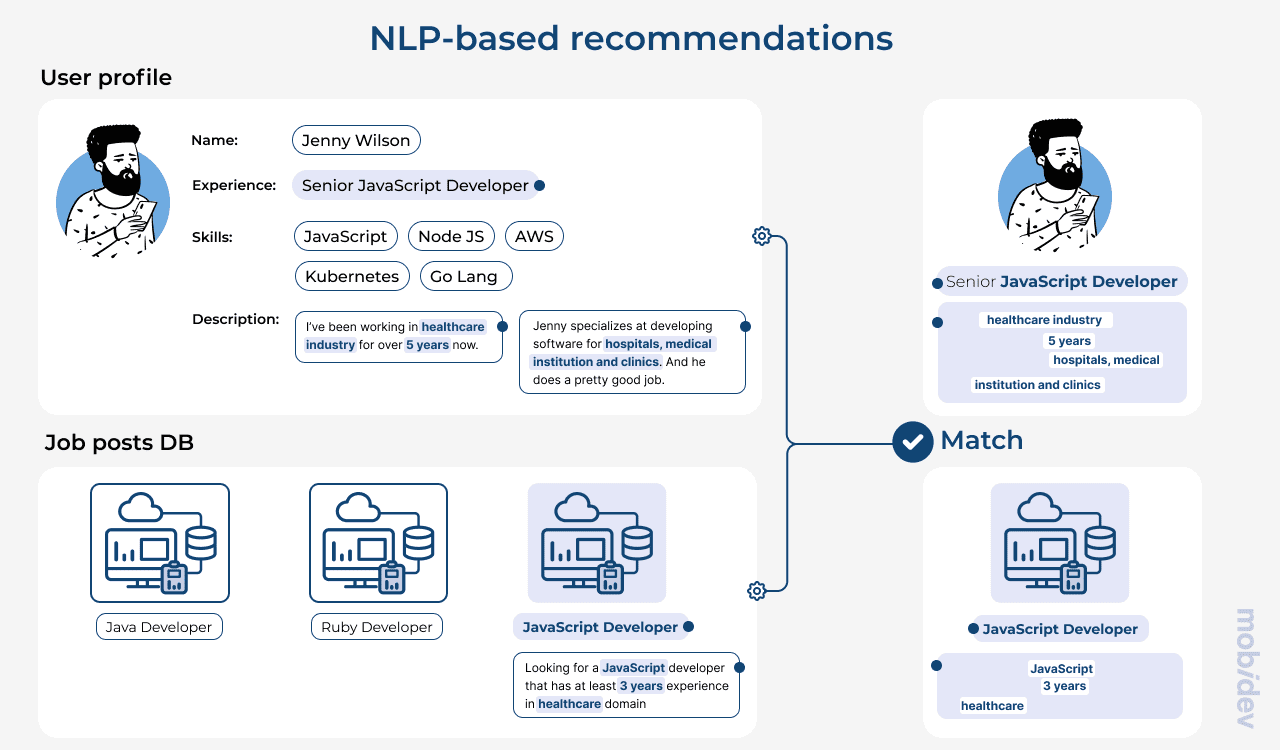
NLP-based recommendations for job search matching
In this simple example, we can see that extracting data from text can instantly improve matching results, and save time both for the user, and the company that searches for a professional. So now, let’s discuss what approaches we can apply to work with text data and build an NLP-based recommender system.
Choosing One of 5 NLP-Based Recommendation Approaches
Let’s consider this task using the Data Science and AI Jobs Indeed dataset, which contains information about various job posts in the field of AI. In the context of this dataset, the matching task can be formulated as follows: to find a suitable vacancy for a candidate, based on the skills and experience described by him. So as an input, we’ll get tons of written descriptions that convey information about the skillset of our potential employees.
Our dataset contains the following textual data:
- title of the vacancy
- location
- A detailed description of the requirements for the candidate

Dataset information example
Given that the dataset was scraped from a real professional network, we can understand which NLP methods will work the best in a real world environment.
1. Text Similarity
The text similarity approach provides the coefficient of similarity of two texts, comparing the vectors of both texts. In this case, the feature that will be used when building the AI model is the value of this coefficient. Below is an example of the work of the text of the similarity model, where the similarity score is the coefficient of similarity of the job description with the description of the candidate’s skills.
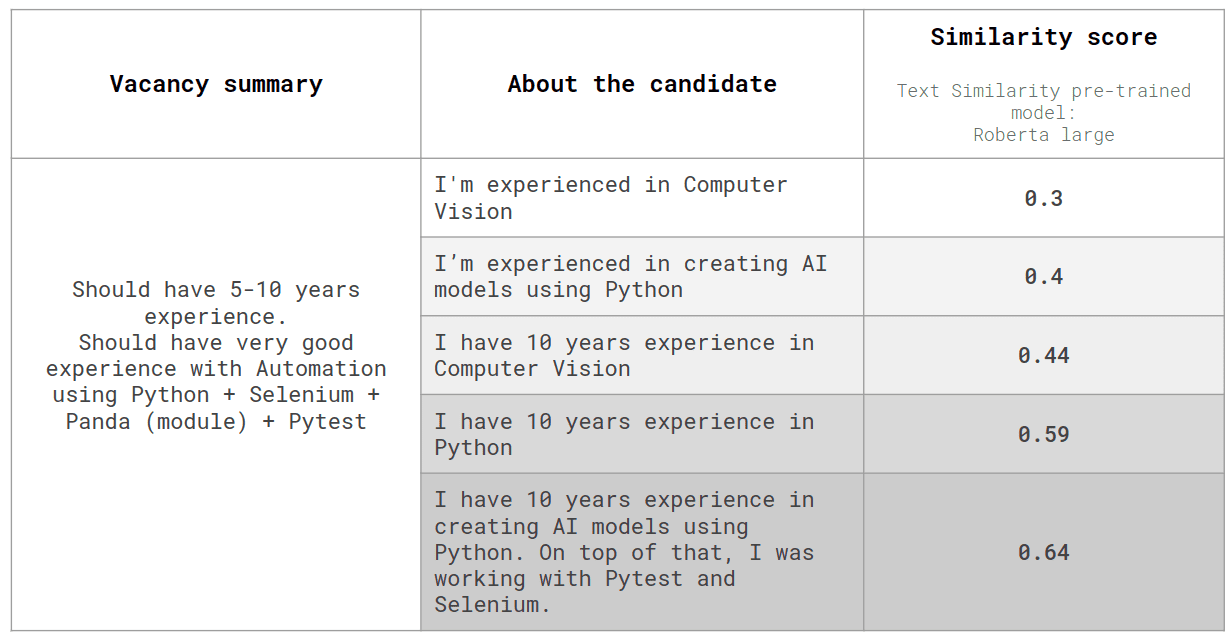
Text similarity model output example
Text similarity models can be used in a raw form, because they provide more accurate results and indicate whether two texts explain the same thing based on semantic analysis. Additionally, text similarity can also be used in conjunction with other NLP models like text summarization.
2. Named Entity Recognition
Another NLP approach is called Named Entity Recognition or NER. The essence of this method is to find named entities in the text, such as: location, organization, person, and so on. As long as we target certain keywords, we want to be sure the model indicates named entities accurately, so that the recommendation system doesn’t mistake organization names with locations, or technologies with projects.
Below is an example of using the NER model on the location entity. The feature that will be used for modeling will be the coefficient of the similarity of two entities, as shown below.
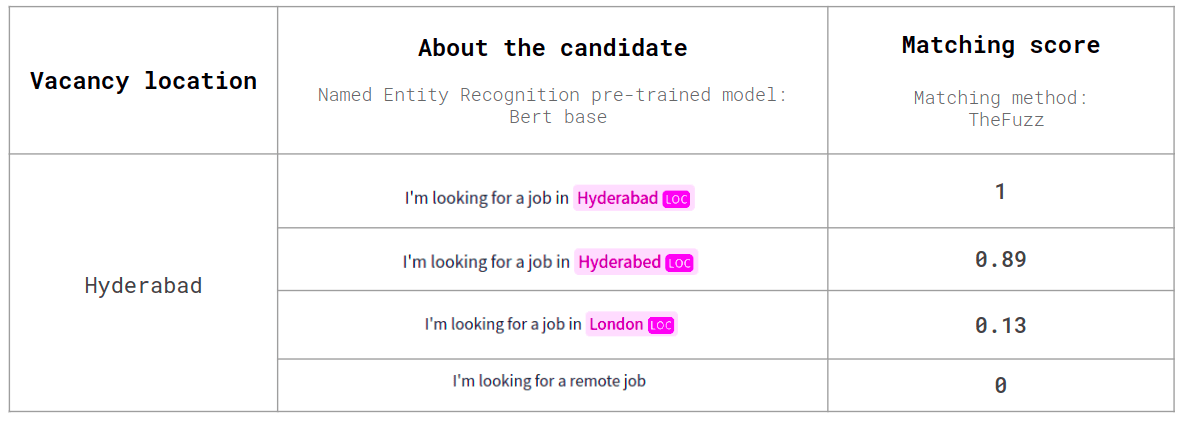
Named Entity Recognition results
This method can be useful in replacing standard filters, such as choosing a city, or choosing a previous place of work, allowing the user to provide search queries in free form.
3. Topic Extraction
The topic extraction method will help to identify implicit subgroups in the training data (in our case, in the list of vacancies), into which the input data can then be classified. For example, speaking about our dataset, namely job titles, the topic extraction model (BERTopic) helped to identify several topics, each of which is described by the 5 most common words.
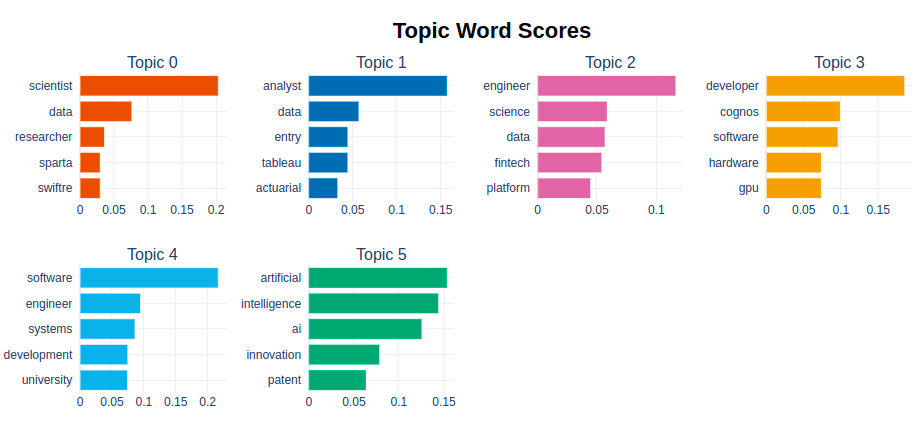
Most common topics of the Data Science and AI Jobs Indeed dataset
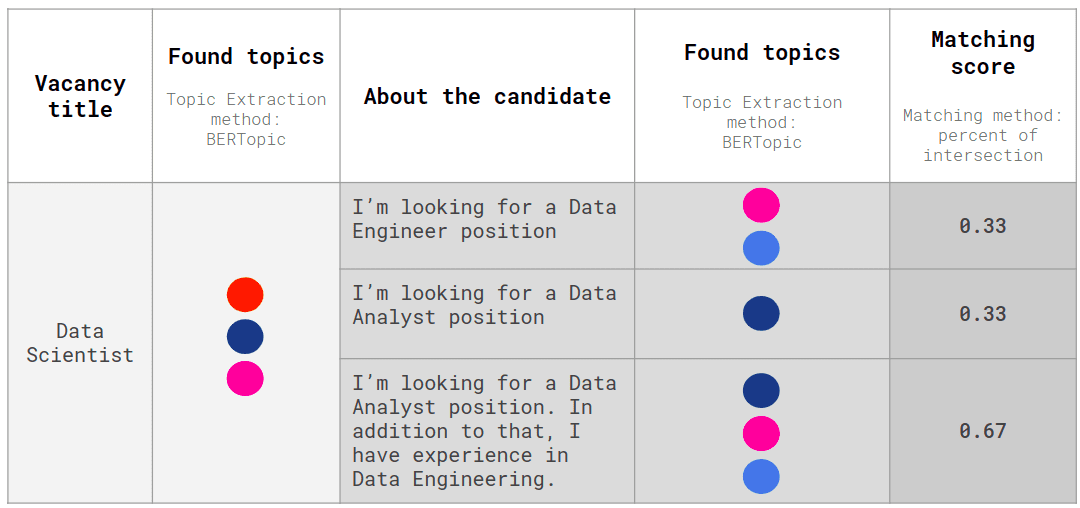
In order to use this information when building a matching model, you can designate a feature that will indicate the similarity of two texts in terms of the similarity of the topics found, as shown in the figure below.
4. Keyword Extraction
The keywords extraction method will help to check the presence of the most important keywords in the input text, as shown below. Automatic keyword extraction is useful for parsing the text and denoting which parts of a sentence, or separate words are the key ones. Further, we can compare how many keywords are met in a target text like the one shown in the example below.
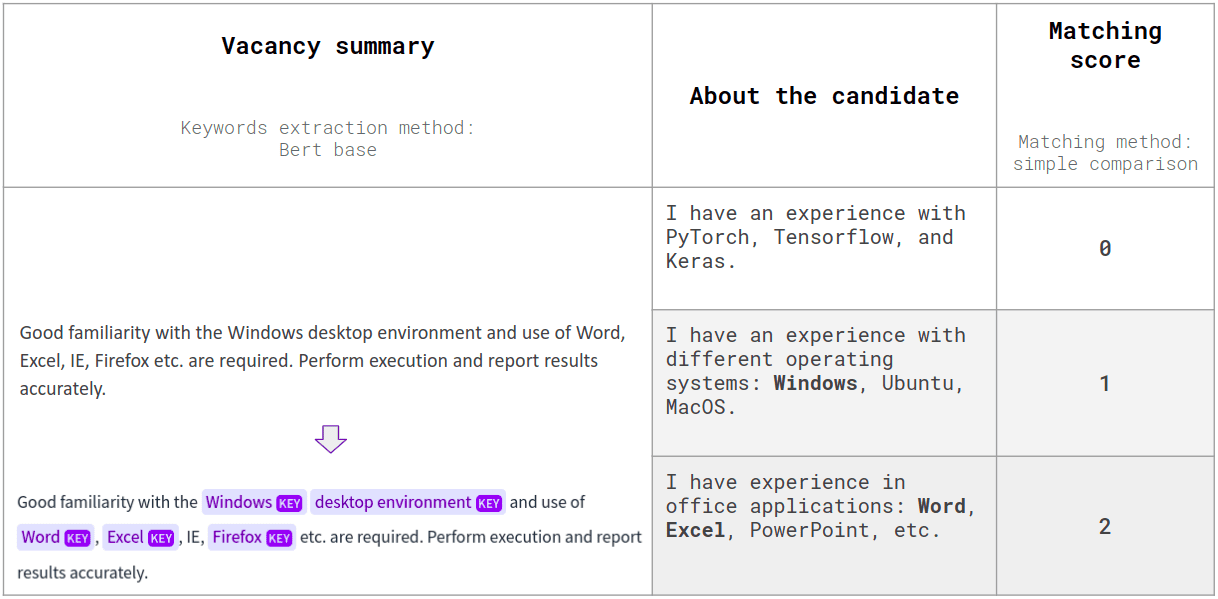
Keyword extraction model output
5. Text Summarization
In addition to all of the above mentioned methods, you can also consider using text summarization to work with large texts. Large bodies of descriptions may often appear on content platforms that want to enlist as many product features and as much information as possible. While it’s not the case for professional networks, summarization helps to produce shorter versions of the text while preserving key information points.
All of the above mentioned methods can be, or rather should, be combined into a single NLP pipeline. The complexity of NLP processing will depend on the domain area, goals, and features of the existing system. However, the best matching results can be provided to the user once a recommender system is capable of working with different types of content, different text length and so on.
After converting the source text into a set of numeric features, we have to build an AI model. Here we can use three types of models:
Сlassification model that will predict two possible values: match / no match (1/0). Based on the probability of the model prediction, you can choose the most appropriate matching option.
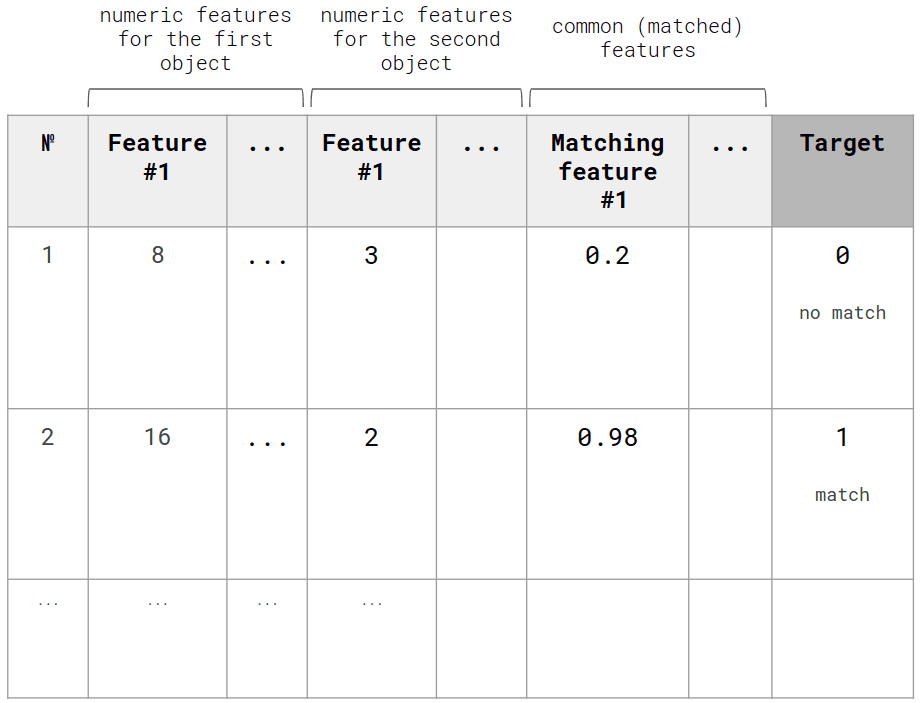
Regression model to predict the coefficient of similarity of two candidates.
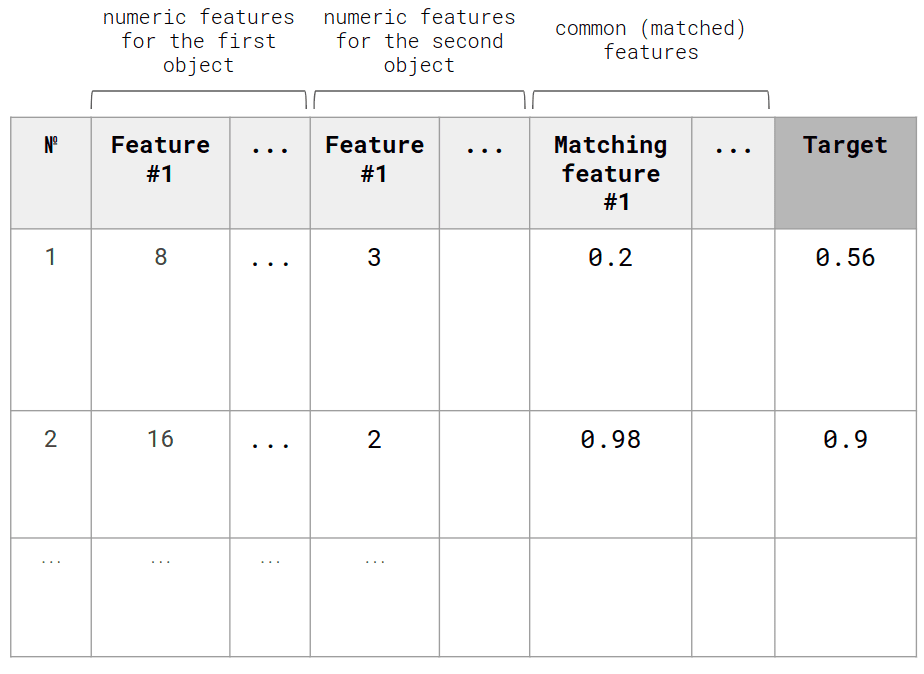
Graph-based solution, where the features obtained from the text will be used as additional graph vertices, and matching will be performed by the number of matching vertices, as shown below.
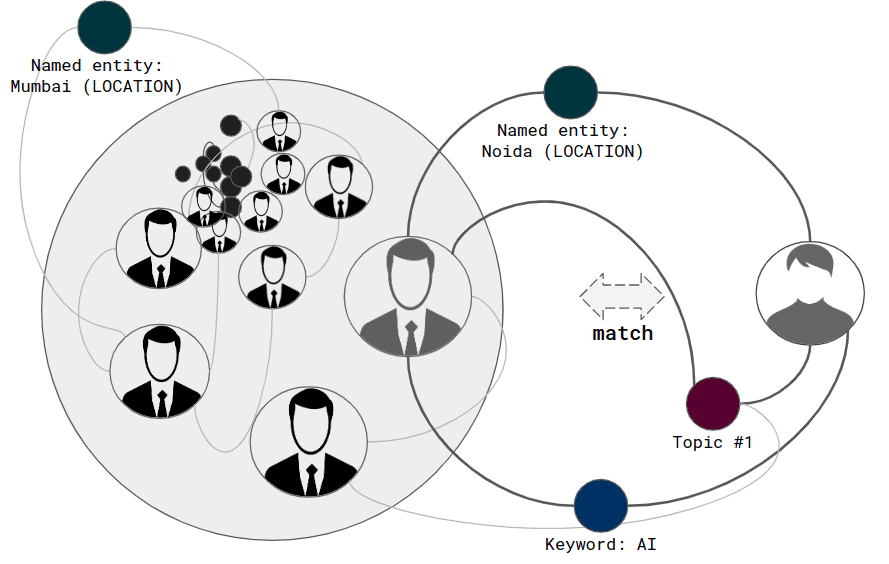
Here, you can watch our short demo that shows how the described approach can be applied to recommend job posts based on the matching coefficients of the vacancy description and the candidate’s skills. The dataset for training was the already mentioned Data Science and AI Jobs Indeed.
Where to Apply Recommendations Using NLP
Despite the fact NLP can be superior to standard search capabilities because it allows the user to type their request in a free form, it doesn’t mean we can’t combine it with conventional recommendation systems. NLP serves a specific purpose here, and does require setting up an infrastructure for data collection, a server for model operation, and other elements.
So this approach fits perfectly in the case that you already have data collected, or there is a relatively small amount of content that you want to recommend this way. This requires a solid data science expertise to analyze the requirements of your existing infrastructure, prepare data, and implement NLP methods.
As an alternative, we can apply GPT models that have become popular lately. ChatGPT, or GPT 3 represent conversational bot models that can be integrated via API and won’t require a huge data collection hassle. This is because they can already recognize human speech in context and provide recommendations without applying any filters. Our AI engineers are always looking for challenging tasks and projects that require using advanced machine learning techniques. So feel free to discuss your project vision with us.
 Use Cases in Business")

