
Contents:
Object detection and tracking have become essential tools for companies looking to enhance efficiency, improve security, and make better-informed decisions. Solutions like edge biometrics and automated item counting help industries tackle complex challenges while unlocking new possibilities. This would have seemed like a distant possibility a few years ago, but now it’s within our grasp. The real challenge lies in helping businesses incorporate these technologies in ways that fit their specific needs, all while overcoming challenges like limited datasets or computational resources.
With over ten years in the software development industry, I’ve led various projects, focusing especially on computer vision and AI app development. This article draws on my professional experience and the collective expertise of MobiDev’s consulting and engineering teams. It focuses on practical applications of object detection and tracking, offering insights into techniques that can help with current tasks or even transform your organization through AI adoption. Let’s dive into the details and explore how these technologies can make a real impact!
Comparison of Object Detection vs. Recognition vs. Tracking
Object detection, recognition, and tracking are technologies that allow visual data interpretation, but they do so in distinct ways. Grasping their differences and how they complement one another is vital for unlocking their full potential in a wide range of applications.
These technologies are having a real impact across different industries, from improving security systems to streamlining supply chains and improving customer experiences. In this section, I’ll break down how each process works and how they help address real-world challenges.
Object Detection
To start with, object detection primarily relates to the process of locating and recognizing patterns in images. It determines both the presence and position of objects, typically through bounding boxes. Consider manufacturing, where object detection is employed to identify defective components on assembly lines. In retail, this same technique determines the location of products on the shelves for stock management purposes.
Object Recognition
Object recognition goes a step further by classifying detected objects into predefined categories. It emphasizes understanding what the object is rather than its location. For instance, it helps to determine what type of vehicle is in a traffic monitoring system: a car, truck, or motorcycle. Other uses might include the recognition of tumors in medical images and the scanning of bar codes in retail stores.
Object Tracking
Meanwhile, object tracking is used to continuously monitor the location of detected objects across video frames. Unlike detection, which works frame by frame, tracking creates trajectories for objects over time. This is vital for real-time systems like surveillance, where following a person’s movement or a vehicle’s route is necessary for security or traffic management.
| # | Feature | Object Detection | Object Recognition | Object Tracking |
|---|---|---|---|---|
| 1 | Primary Goal | Locate objects in an image | Classify objects | Monitor object movement |
| 2 | Use Case Examples | Defect detection, inventory, etc. | Barcode scanning, healthcare, etc. | Surveillance, autonomous vehicles, etc. |
| 3 | Output | Bounding boxes | Object categories | Trajectories over time |
Deep Learning Approaches for Object Detection
In general, object detection has come a long way, evolving from traditional computer vision techniques to advanced methods driven by deep learning. Traditionally, common practices, such as edge detection, or histogram, were feature engineered and thus were less adaptable to variations in real-world scenarios, like changes in lighting or object orientation.
Deep learning opened the door for Convolutional Neural Networks (CNNs), enabling feature extraction and leading to a breakthrough in detection accuracy. That said, let’s see the popular object detection deep learning frameworks:
1. YOLO (You Only Look Once)
YOLO is a one-stage detector used to process images in a single pass. It is extremely fast, making it ideal for real-time applications such as self-driving cars and drone navigation.
2. SSD (Single Shot MultiBox Detector)
Similar to YOLO, SSD is a one-stage detector designed for speed. It uses multiple convolutional layers to predict objects of varying scales. SSD is known for its ability to combine speed with accuracy, which makes it a favored choice for mobile and embedded applications such as augmented reality.
3. Faster R-CNN (Region-based Convolutional Neural Network)
Faster R-CNN is a two stage detector that uses a Region Proposal Network (RPN) to identify all probable object regions and their classes. It offers high accuracy, yet it is known for its slower processing speeds. Faster R-CNN is commonly used in research and healthcare, where precision is critical.
Evolution of Techniques for Object Detection
It’s worth noting that early object detection approaches relied on rigid frameworks like the Viola-Jones algorithm, which struggled with complex scenarios. The introduction of CNNs revolutionized this field by enabling feature learning directly from data. Over time, advancements like the Feature Pyramid Network (FPN) enhanced the detection of small objects, while transformer-based models (e.g., DETR) have started to reshape the landscape with their attention mechanisms.
Comparison of Object Detection Models
Switching from traditional methods to deep learning has allowed object detection systems to work more reliably, even in tough, real-world conditions. As these models keep improving, we can expect even better speed and accuracy, bringing research closer to real-world applications.
| # | Model | Type | Speed | Accuracy | Object Detection Use Cases |
|---|---|---|---|---|---|
| 1 | YOLO | One-stage | Very high (50-140 FPS) | Moderate to high | Real-time applications like drones or robotics |
| 2 | SSD | One-stage | High (30-90 FPS) | High | Mobile and lightweight applications |
| 3 | Faster R-CNN | Two-stage | Moderate (15-25 FPS) | Very high | Precision-critical tasks, such as healthcare |
Object Recognition in Machine Learning
Object recognition is critical in applications where understanding the type or identity of an object is more important than its location.
For example, in healthcare, object recognition is a cornerstone of advanced medical image analysis, aiding in diagnoses and treatments. It is commonly used to identify tumors or abnormalities in medical scans. This technology is revolutionizing diagnostics, as seen in applications like AI for cancer detection, which enhances early detection and improves patient outcomes.
In retail software development, object recognition is leveraged for barcode scanning, SKU identification, and analyzing customer behavior to optimize product placement. These systems improve efficiency and create more personalized shopping experiences.
Supporting Technologies: Object Segmentation and Tracking Integration
It’s worth mentioning that segmentation and tracking complement each other to deliver precise, actionable insights. Together, they enable accurate object identification and motion analysis, enhancing the performance of AI systems across industries.
Object Segmentation
During the object segmentation process, the model gets an input image or video and provides a mask of needed objects as an output.
There are different types of object segmentation. The most common of them are semantic and instance segmentation. Semantic segmentation creates one mask for all objects of the same type. Instance segmentation returns a separate mask for every instance of the same class.
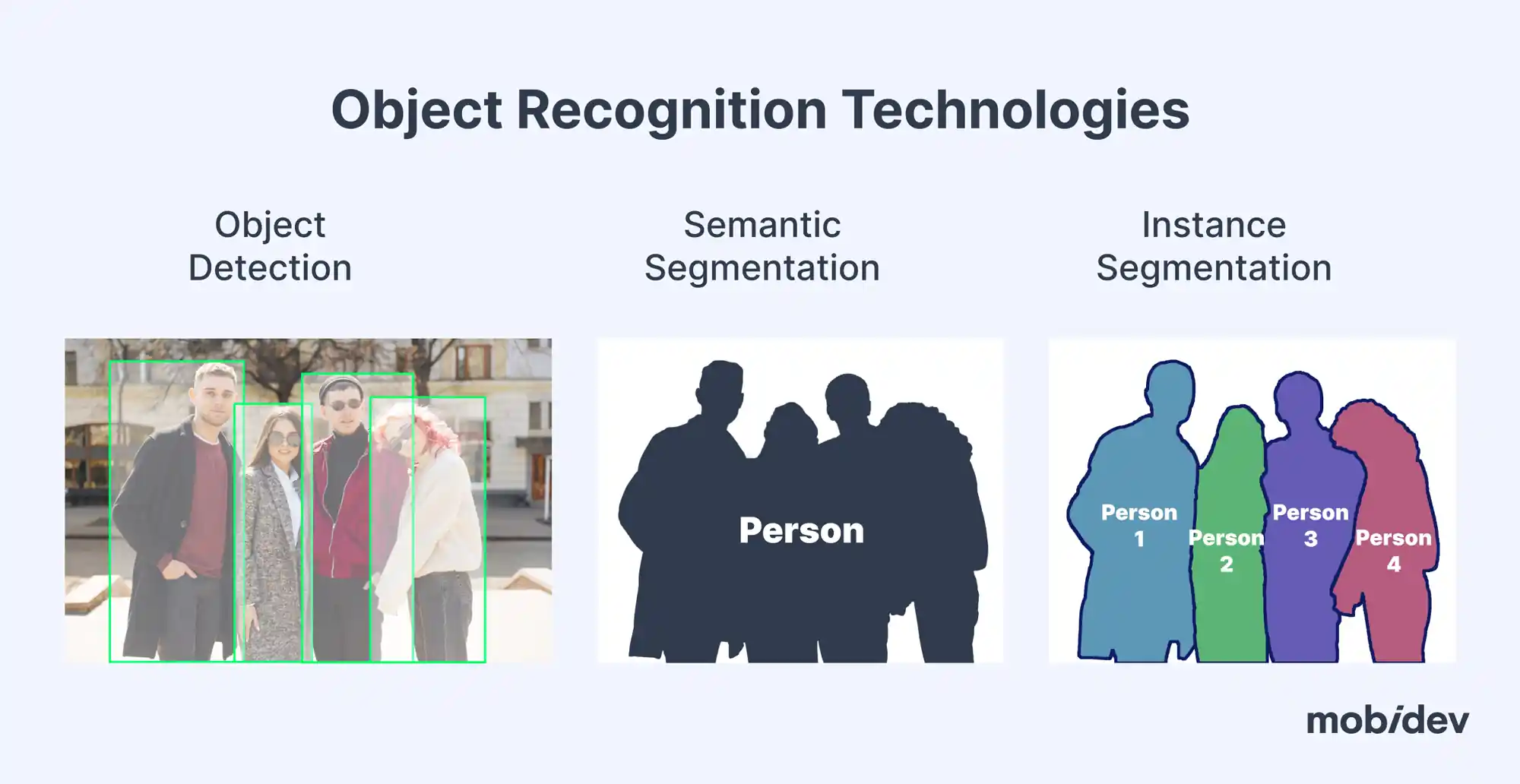
Object segmentation helps identify and locate objects pixel-precisely. This approach can also be used as a separate solution or as a part of a more difficult pipeline, e.g. changing the background for a photo/video.
Object Tracking
So, objects can be detected or segmented on every separate frame, but often we also need to track these objects. Tracking provides ID for every unique object, associates these objects between frames, predicts moving trajectories, and as a bonus corrects the work of the detecting algorithm.
Approaches for 3D and 2D multiple object tracking are almost the same and include such algorithms as JPDAF, SORT, and DeepSORT or different types of neural networks.
The object tracking problem we solved in one of our projects was palm tree detection and finding withered trees using drone footage. When a tree is detected, it is highlighted by a gray bounding box, and after several classifications, if a palm tree is healthy, it gets highlighted by a green or red bounding box.
Instance Segmentation and Its Applications
As we mentioned above, an advanced form of object recognition, instance segmentation identifies each object in an image and outlines it precisely, providing more detailed results than bounding boxes. It’s particularly valuable in high-granular scenarios, such as distinguishing individual objects in overlapping or complex environments.
This capability is transformative for sectors like security, where instance segmentation improves surveillance systems by enabling:
- Intrusion Detection: Identification of intruders who may be completely or partially unknown, as well as objects that could cross the designated perimeter.
- Object Recognition and Tracking: Scanning and assessing specific persons and items in the collected footage to increase understanding of the situation.
- Crowd Monitoring: Tracking individuals in public spaces to identify potential threats or manage emergencies effectively.
Object Recognition in Defect Detection
Object recognition processes are also widely implemented in defect detection in manufacturing. AI visual inspection systems detect disfigurements like cracks, scratches, or missing parts on products. As a result, it enables the market to eliminate all substandard items and improve customer satisfaction while minimizing waste in production processes.
On top of that, beyond manufacturing, AI visual inspection supports damage detection in industries like aerospace and construction, equipment maintenance, and even agricultural monitoring by identifying plant diseases early.
Object Detection for Retail Analytics
Retail object detection combined with recognition enables real-time inventory management and customer behavior analysis. This capability supports use cases like:
- Retail Analytics: Analyzing customer movements and how long they spend in different areas helps improve store layouts and ensures products are placed where they are supposed to be.
- Shelf Monitoring: Checking if products are in stock and properly positioned on the shelves boosts sales.
- Inventory Management: Managing inventory audits to minimize the cost of labor and enhance accuracy.
Object Tracking Techniques
Unlike object detection, which processes each frame independently, object tracking predicts the motion and association of objects over time. This is essential for applications that require continuous monitoring or understanding of object movement patterns, such as surveillance or autonomous vehicles.
The thing is that modern object tracking algorithms are tailored to address varying demands of speed, accuracy, and computational efficiency. Techniques like Kalman Filters, Deep SORT, and Optical Flow exemplify how tracking can adapt to dynamic environments, from crowded urban settings to remote agricultural landscapes. As a result, by leveraging these algorithms, businesses can ensure precise motion prediction and association, enabling smarter systems across industries ranging from security to transportation.
Kalman Filters are often employed for motion prediction in linear systems. They predict an object’s state (position, velocity, etc) using noisy sensor measurements and prior knowledge. This approach is considered computationally efficient and thus applicable for real-time applications.
Optical Flow tracks objects by analyzing pixel intensity changes between consecutive frames. It excels in capturing motion in complex environments and is often used in tracking small or fast-moving objects. However, it can be computationally intensive when applied to high-resolution videos.
Deep SORT (Simple Online and Realtime Tracking) enhances the original SORT algorithm by integrating deep learning-based appearance features. It matches detected objects between frames by combining motion and visual information, offering robust tracking in crowded or dynamically changing environments. This makes it ideal for applications like pedestrian tracking in smart cities or vehicles in traffic monitoring systems.
In light of this, the versatility of object tracking lies in its ability to deliver actionable insights across industries. From enhancing surveillance with precise motion tracking to enabling autonomous navigation in vehicles, real-time applications showcase the transformative power of tracking technologies. In agriculture, drones equipped with AI models detect and monitor crop health, while in manufacturing, tracking ensures seamless quality control on production lines.
TOP 6 Real-World Applications of Object Tracking
Let’s see 6 use cases explaining how these technologies tackle real-world challenges and unlock new efficiencies.
1. Surveillance and Security
Object tracking serves as one of the fundamental components of a surveillance system. For example, it can assist in monitoring children in educational institutions or child-care centres in order to guarantee their safety and that they are not attempting to exit the premises. Similarly, it is used in wildlife tracking to monitor animals leaving a farm or zoo.
Additionally, object tracking can enhance privacy protection by enabling features like face blurring during live video streams for conferences, public events, or CCTV footage. You can learn more about real-world implementations in our article on AI video processing.
2. Autonomous Vehicles
Self-driving cars often combine object tracking with the general detection of other cars, people, and any other obstacles on the road. Algorithms like Kalman Filters and Deep SORT ensure precise trajectory predictions, enabling safer navigation in dynamic environments.
3. Manufacturing and Defect Detection
In robotics-driven manufacturing facilities, object tracking identifies and monitors defective components on production lines. Combined with segmentation techniques, it ensures that anomalies are tracked and addressed promptly, contributing to the quality control process.
4. Agriculture and Drone Applications
Object tracking is extensively used in drone-based agriculture for tasks like palm tree health monitoring. In one of our projects, drones were equipped with computer vision models to detect and track trees. Healthy trees were highlighted with green bounding boxes, while unhealthy ones were marked in red.
5. Healthcare
Object tracking is also making strides in healthcare, particularly in monitoring patients. In settings like hospitals or elderly care, it helps track patient movements, ensuring their safety and providing alerts if falls or other concerns occur. It’s also valuable in monitoring physical therapy progress.
6. Sports Analytics
Object tracking in sports is used to analyze player movements during games. By tracking athletes in real time, teams can gather valuable insights into performance, refine strategies, and identify potential injury risks based on movement patterns. This technology is extremely important in tracking the players’ physical condition so that they can maintain maximum performance throughout the season.
Challenges and Solutions in Object Detection and Tracking
Despite its potential, object detection and tracking face barriers like limited dataset size, computational resource constraints, and some others. All these challenges may postpone the implementation of AI-oriented systems, particularly in certain industries.
Key Challenges
Let’s discover the intricacies of these challenges and their significance for AI implementation:
Small Datasets. Building accurate object detection systems often requires large, labeled datasets. However, in niche applications or constrained environments, data scarcity can hinder model performance. Solutions include leveraging pre-trained models for transfer learning and fine-tuning, such as using YOLO for similar object types, which reduces the need for extensive datasets.
Occlusion. Occlusion occurs when certain objects in a video or image are blocked, either partially or fully, resulting in errors in object identification or tracking. 3D bounding boxes and multi-view learning can solve this problem by ensuring better spatial awareness.
Class Imbalance. Class imbalance occurs when certain object categories dominate the dataset, leading to biased detection or tracking. This can be resolved using weighted loss functions, data augmentation, or synthetic data generation to ensure balanced representation during training.
Computation Power Constraints. Real-time object detection and tracking, especially on edge devices, require significant computational resources. Optimizing models for performance through techniques like quantization, pruning, and deploying lightweight architectures like YOLOv5 or MobileNet can overcome this limitation.
Case Study: Object Detection Using Small Dataset for Automated Items Counting in Logistics
MobiDev AI team has conducted a case study in which an automated item counting system for logistics was developed. The main goal was to enhance accuracy in inventory management for the logistics industry. Without a doubt, verifying quantities during transportation or warehouse operations takes lots of time and may also involve human error. The challenge was to determine if a small annotated dataset could be used to accurately count diverse items under varying conditions, such as different shapes, lighting, and image quality.
While traditional computer vision techniques, like Sobel filters and Hough circle transforms, are useful in controlled environments, they struggle with the variability seen in logistics operations. We addressed this by fine-tuning a neural network-based object detector, a solution better suited for learning from data and adaptable to real-world conditions, ensuring more reliable and scalable item counting.
Trends and Future of Object Detection and Tracking
It should be noted that object detection and tracking have continued to grow at a fast rate, mainly due to groundbreaking developments in artificial intelligence and computational technologies. Other new creations, like transformers and edge AI, are expected to alter real-time applications, making them more efficient and smarter.
1. Transformers in Object Detection and Tracking
Transformers, originally designed for natural language processing, have shown remarkable potential in computer vision tasks, including object detection and tracking. Models like DETR (DEtection TRansformer) and its successors leverage attention mechanisms to process global context more effectively than traditional CNNs, advancing the field of object detection with machine learning object detection methods that improve accuracy and scalability.
Key advantages of transformers in object tracking include:
- Improved Accuracy: They provide better detection in cluttered scenes, which is critical for applications like crowd monitoring or autonomous navigation.
- End-to-End Processing: Transformers streamline object detection and tracking pipelines by removing the need for separate region proposal networks or handcrafted algorithms.
- Scalability: Their ability to process large datasets makes them suitable for handling complex scenarios like multi-object tracking in urban environments or industrial settings.
As transformer-based models mature, their integration into real-time systems is becoming feasible, offering significant performance gains for tasks requiring high accuracy and speed.
2. Real-Time Edge AI Processing
Edge AI involves performing AI computations directly on devices (rather than on cloud servers). This method reduces latency, improves privacy, and fosters reliability in settings with unstable or weak internet connections.
A prime example of edge AI applications is biometric-based office security systems (read more on edge security systems in our latest article). MobiDev has developed a solution that authenticates employees at office entrances using face and voice recognition. The entire pipeline—face detection, identification, voice verification, and anti-spoofing—is processed on an NVIDIA Jetson Xavier, a powerful edge device with GPU capabilities.
Benefits of real-time edge processing include:
- Enhanced Security: Biometric authentication with edge AI ensures fast and reliable verification, reducing vulnerabilities associated with cloud dependence.
- Cost-Effectiveness: Edge devices eliminate ongoing cloud service costs while providing scalable solutions for industries like surveillance and manufacturing.
- Privacy Preservation: Sensitive data, such as facial or voice biometrics, is processed locally, minimizing exposure to external threats.
Emerging Trends Driving the Future
Trends and possibilities are advancing daily, including AI, edge AI, and transformers. These technologies enhance machine learning and real-time processing, improving their ability to identify and track objects, thus making businesses more efficient. Thanks to these advancements, AI-powered autonomous vehicles, security systems, and other sectors that depend on real-time data are now becoming the norm.
Let me show you how these innovations are transforming various sectors:
- Integration of AI with IoT (Internet of Things): The AI-IoT devices are able to enhance the experience of tracking objects with the help of sensor data and advanced analytics. For example, smart cameras integrated with object detection algorithms can monitor industrial operations for predictive maintenance or public spaces autonomously.
- 3D Tracking for Augmented Reality (AR): With AR gaining traction in marketing, gaming, retail, and education, object tracking technologies are evolving to handle 3D environments. This trend enables precise spatial understanding and interaction with virtual objects in real-world scenarios.
- Energy-Efficient AI Models: With the rise of edge AI, creating lightweight models optimized for low-power devices is becoming more relevant. Pruning and quantization techniques are making real-time AI possible on devices with constrained computational resources, for example, for building edge AI biometrics solutions.
- Focus on Explainability and Ethics: As artificial intelligence is increasingly deployed in areas like autonomous vehicles and surveillance, increasing transparency in tracking decisions is imperative. To alleviate these issues, there has been an increase in research activities into explainable artificial intelligence (XAI).
Emerging Solutions
We’ve noticed an increasing number of people turning to Roboflow, a no-code platform that simplifies the process of preparing data, training object detection models, and deploying them—all without needing advanced programming skills. This has made AI development more accessible, especially for smaller or specialized projects.
Why Choose MobiDev as Your AI Consulting and Engineering Ally
MobiDev is your reliable expert in AI consulting and AI engineering, with solid experience in software development and AI technology for more than a decade. Since 2018, the in-house AI team has been reinforcing our business model with custom solutions while also enhancing technological advancement in the market.
How do we approach AI products? We begin by helping you understand what AI is and how it can work for your company. Whether we’re embedding existing models into your systems or developing entirely new ones, we ensure every solution meets your requirements for performance, scalability, and purpose.
Discover how MobiDev can elevate your business with customized AI solutions tailored to your industry needs—contact us today!


