

Contents:
Workspace security can be a fiddly money drain, especially for corporations that deal with sensitive information, or run multiple offices with thousands of employees. Electronic keys are one of the standard options for how security systems can be automated, but in reality there are tons of downsides like lost, forgotten, or faked keys.
Biometrics have are a solid alternative to the conventional security measure, since they represent a concept of “what-you-are” as a authentication method. In this material, I’ll elaborate how biometric data can be used to architect an automated security system based on our own system used for MobiDev office security. We’ve been developing our artificial intelligence expertise since 2019 and got loads of experience on similar projects. So today, we’ll speak about the edge biometrics as a combination of edge devices, AI, and biometric data used for authentication and verification of users.
What Are Edge Biometrics?
First things first, what is edge AI? In a traditional architecture of artificial intelligence, a common practice is to deploy models and data in the cloud, separate from the operating device or hardware sensor. This forces us to maintain the cloud server in a proper state, preserve a stable internet connection, and pay for the cloud service. If the storage appears inaccessible in case an internet connection is lost, the whole AI application becomes useless.
“In contrast, the idea of edge AI is to deploy artificial intelligence applications right on the device, closer to the user. Edge devices may have their own GPU which allows us to process the input in place on the device. This provides a number of advantages such as reduced latency due to fact all actions are performed locally, on device. Overall cost and power consumption also become lower. Additionally, the system becomes portable, since the device can be easily moved from one location to another.
Given the fact we don’t need large ecosystems, bandwidth requirements are also lower opposed to traditional security systems that rely on stable internet connection. Edge device can operate even in case of connection shut down, as data can be stored in device’s internal storage. Which makes the whole system design more reliable and robust.”

The only notable pitfall is that as all the processing has to be done on the device in a short amount of time, and the hardware components need to be powerful enough and up to date for this function.
For tasks like biometric authentication with face or voice recognition, fast response and reliability of the security system are critical. Since we want to ensure seamless user experience as well as proper security, relying on edge devices gives those benefits.
Biometric information like employee faces and voices appears to be secure enough, since they represent unique patterns that can be recognized by neural networks. Additionally, this type of data is easier to collect, as most businesses already have photos of their employees in their CRM or ERP. This way you can also avoid any privacy concerns by gathering, say, fingerprint samples of your people.
Combined with edge, we can create a flexible AI security camera system for workspace entrance. If you are exploring the ways to use biometric data in your own office, MobiDev offers AI product consultancy services to assist business owners at their AI initiatives. This service implies the combination of business and tech consultancy that covers investigation procedures and preparation of artifacts such as technical vision and product development strategy that further converts into smaller milestones. So if you are ready to discuss the requirements for your project, contact us to book a call with me or other architects from MobiDev.
NEED AI CONSULTANCY?
Our engineers will analyze your infrastructure and provide you with all the necessary deliverables to move on with development
Get in touchAI-based Workplace Surveillance System Design
The main idea behind the project was to authenticate employees at the office entrance with just a glance in the camera. The computer vision model is able to identify a person’s face, compare it with the previously obtained photo and unlock the door. Voice verification was added as an additional step to avoid tricking the system in any way. The whole pipeline consists of 4 models that carry different tasks from face detection to speech recognition.
All of these steps are done through a single edge device that serves as a video/audio input sensor, as well as a controller for sending commands to lock/unlock doors. As an edge device, NVIDIA Jetson Xavier has been chosen. The main reasons behind this choice were the presence of GPU memory (which is vital for accelerating inference for deep learning projects) and the availability of Jetpack – SDK from NVIDIA, which allows coding on devices in Python3. Therefore, there is no strict need to convert the DS model to another format and nearly all of the codebase can be adapted to the device by DS engineers, so no rewriting from one programming language to another is required.
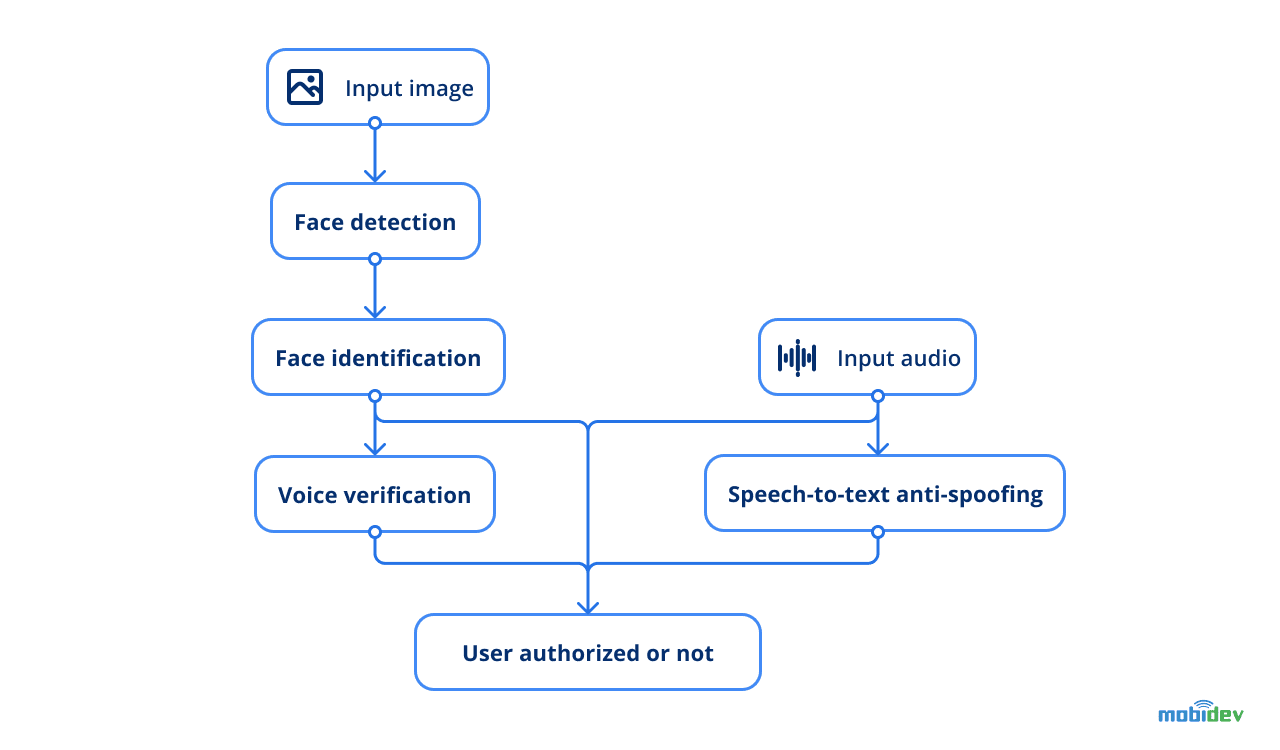
AI security system workflow
So the general flow looks as follows:
- Input image is provided to the face detection model to find the user.
- Face identification model runs inference by extracting vectors and comparing them with the existing photo of an employee to identify whether it’s the same person.
- Another model is fed with voice samples to verify the voice of a specific person.
- Additionally, speech-to-text anti-spoofing is used as a technique to prevent any type of trickery.
Let’s discuss each of the elements, and elaborate on the training and data collection procedure.
Dataset Gathering
Before diving deep into system modules, it’s important to note what database is used. Our system relies on the availability of so-called reference, or ground-truth data for users. This data currently includes precomputed face and voice vectors for each user and looks like an array of numbers. The system also stores data from the successful attempts of logins for their possible use for re-training later. Given this, we’ve chosen the most lightweight solution, SQLite DB. With this DB, all the data is stored in a single file that’s easy to browse and backup, while data science engineers’ learning span is shorter.
Since facial recognition requires photos of all employees that may enter the office, we used facial photos stored in corporate databases. A Jetson device placed on the office entrance also collected face data samples as people used face verification to open the door.
Voice data wasn’t available initially, so we organized data gathering by asking people to record 20-second clips. Then, we used a voice verification model to obtain vectors for each person, and stored them in DB. Voice samples can be collected with any audio input device. In our case, casual mobile phones and web cameras with inbuilt microphones were used to record voices.
Face Detection
Face detection provides an answer to the question of whether there are any faces in a given scene. If there are, the model should give coordinates of each so you will know where each of the faces is located on the image, including facial landmarks. This info is important because we need to receive a face in a bounding box to run face identification on the next step.
For face detection, we used the RetinaFace model with a MobileNet backbone from the InsightFace project. This model outputs four coordinates for each detected face on an image as well as 5 facial landmarks. The fact that images captured at different angles or with different optics can change the proportions of the face due to distortion. This may cause the model to struggle identifying the person.
For this need, facial landmarks were used to perform warping, a technique to reduce possible differences between these images of the same person. As a result, obtained cropped and warped faces will look more similar, and extracted face vectors also will be more accurate.
Face Identification
The next step is face identification. At this stage, the model has to identify the person from a given image, which is the obtained picture. Identification is done with the help of references (groundtruth data). So here, the model will compare two vectors by measuring the distance score of difference between two vectors to tell if it’s the same person standing before the camera. This assessment is compared with the initial photo of an employee we had.
Face identification is done with the model with SE-ResNet-50 architecture. In order to make the model results more robust, before obtaining the face vector input, the image is averaged with the flipped version of itself. At this point, the flow of user identification looks as follows:
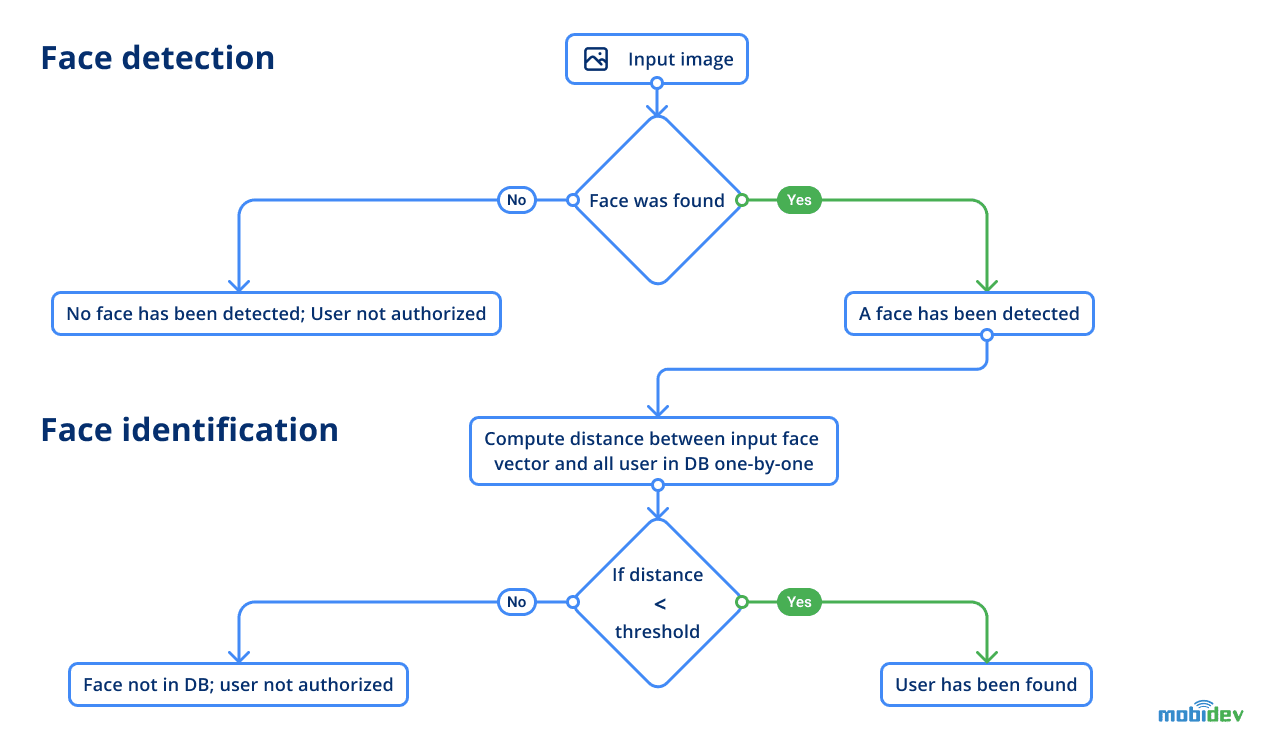
Face and voice verification flow
Voice Verification
Next we move to voice verification. This step should verify if two audios contain the voice of the same person or not. You may ask why not do voice identification as well? The answer is, facial recognition works much better than voice nowadays, and an image gives a lot more information to recognize the user than voice. To avoid identifying the same person as user A by face, and user B by voice, only face recognition is applied.
The basic logic is almost the same as in the face identification stage, as we compared two vectors by the distance between them unless we found similar vectors. The only difference is that we already have a hypothesis about who is the person who is trying to pass from a previous face identification module.
During the active development of the voice verification module, many issues were popping up.
The previous model with Jasper architecture was not able to verify the recordings of the same person taken from different microphones. So we solved this problem by using ECAPA-TDNN architecture, which was trained on VoxCeleb2 dataset from the SpeechBrain framework which did a better job at verifying employees.
However, audio clips still needed some pre-processing. The goal was to improve the quality of audio recording by preserving voice and reducing present background noise. However, all the tested techniques affected the quality of the voice verification model badly. It is likely that even the slightest noise reduction could modify voice audio characteristics in recording so the model will not be able to correctly verify the person.
Also, we performed an investigation into how long the audio recording should be and how many words the user should pronounce. As a result of this investigation, a few suggestions have been made. Such a recording should have a duration of at least 3 seconds and around 8 words need to be spoken.
Speech-To-Text Anti-Spoofing
The final security grain was added with speech-to-text anti-spoofing built on QuartzNet from the Nemo framework. This model provides a decent quality user experience and is suitable for real-time scenarios. To measure how close what the person says to what the system expects, requires calculation of the Levenshtein distance between them.
Obtaining a photo of an employee to trick the face verification module is an achievable task, as well as recording a voice sample. Speech-to-text anti-spoofing excludes scenarios in which an intruder tries to use a photo and audio of an authorized person to get inside the office. The idea is quite simple: when each person verifies themselves, they pronounce a phrase given by the system. The phrase consists of randomly selected words of a chosen set. While the number of words is not huge in a phrase, the actual number of possible combinations is. Applying random generation of phrases, we eliminate the possibility of spoofing the system, as it will require a large number of recorded phrases spoken by an authorized user. Having a photo of a user is not enough to trick an AI security system with this protection in place.

The Benefits Of The Edge Biometrics System
At this point, our edge biometric system follows a simple flow for a user, which requires them to say a randomly generated phrase to unlock the door. Additionally, with face detection, we provide AI surveillance for the office entrance.
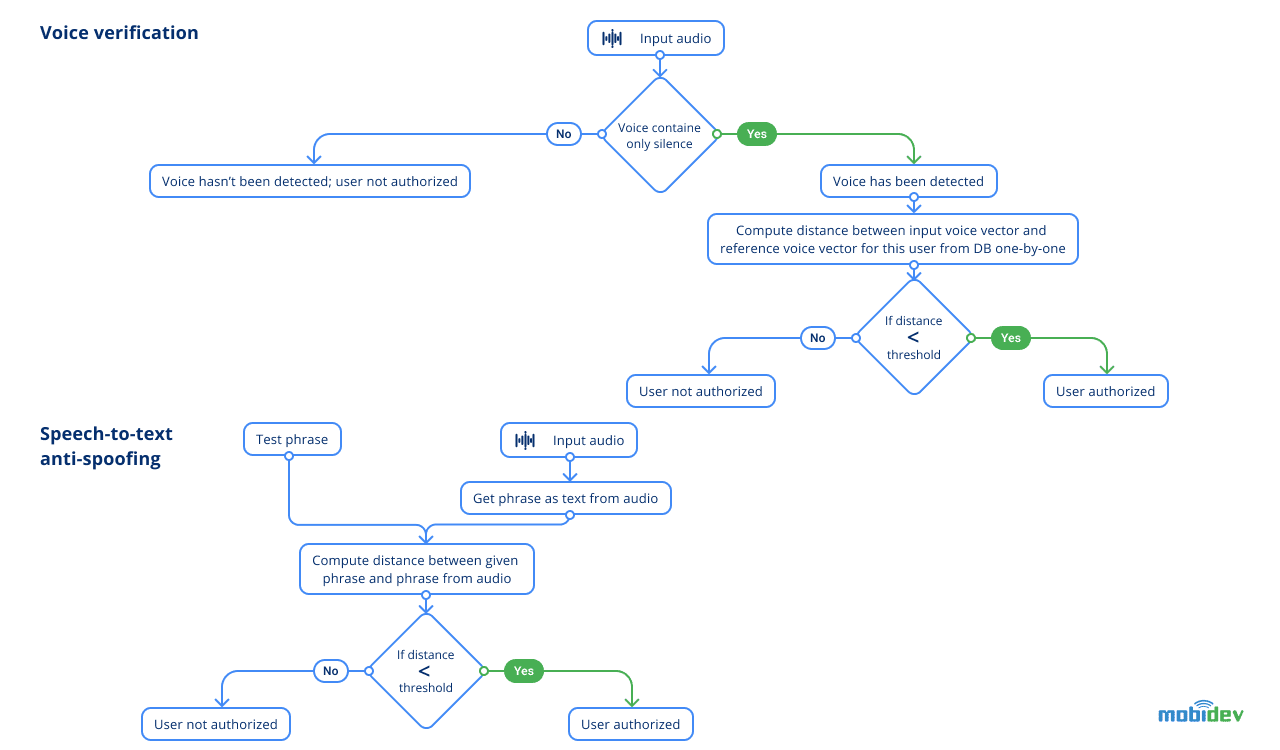
Modules of voice verification and speech-to-text anti-spoofing
“By adding multiple edge devices, the system can be scaled to different office locations or easily modified. We can directly configure Jetson through the network, set up connection with low-level devices via GPIO interface, and upgrade it with new hardware quite easily, compared to a regular computer. We can also integrate with any digital security system that has a web API.
But the main benefit here is that we can collect data for improving the system right from the device, since it appears convenient to gather data on the entrance, without any specific interruption.”
Develop Your Biometric Software With MobiDev
In case you are already investigating the optimal ways to implement biometric solution for office security or any other entities within your company, it might be challenging to analyse your existing infrastructure and foresee potential risks without relevant experience. Usually this requires CTO with the background in artificial intelligence and edge devices that can process data even during the bandwidth/power shortages to ensure security of your biometric data.
MobiDev offers a transparent flow of actions to analyze your specific project requirements, formulate technical vision, set time frames, and estimate the required budget and engineering resource. All of this is accessible through our AI consultancy service where I, or my colleagues will support at choosing technically viable decision, allowing to focus on your business. So if made a decision to develop an edge biometric solution, fill out the contact form and we’ll handle your request in the shortest amount of time.


 for a smart office")