

Contents:
AI inspection in manufacturing helps to maintain quality control by recognizing defects and deformations. Recently, it has shown a growing adoption rate, being leveraged for observing production lines, monitoring product health at all stages, reducing waste, and decreasing maintenance costs.
This article explains how to implement AI visual inspection for defect detection in manufacturing lines, and this approach can be applied to building such solutions for different areas including automotive, electronics, aerospace, pharmaceuticals, consumer goods, and more. No matter what industry you’re involved in, this guide will help you gain an overview of how visual inspection works and how to implement it.
What Is AI-Based Visual Inspection?
In this section, we’ll focus on the basic concepts of AI inspection. If you’re already familiar with the topic, skip ahead to the next section for more advanced technical details and use cases.
AI-based visual inspection is the process of inspecting and evaluating products or components with the help of computer vision technologies. This method improves manual visual inspections by relying on advanced technology to spot defects, irregularities, or specific features in images or videos.
AI can detect patterns or issues that might be hard for the human eye to catch. Learning from labeled examples helps one assess the quality and condition of items during inspection.
AI inspection can be applied in multiple cases:
- Defect detection
- Assembly verification
- Predictive maintenance
- Material and packaging inspection
- Safety monitoring
Let’s take a look at the most prominent use cases revolving around defect detection.

TOP 4 AI Visual Inspection Use Cases
AI visual inspection can be applied in different industries, from manufacturing to agriculture. Here are five use cases that showcase the broad potential of this technology:
- Product defect detection
AI systems analyze products on production lines to identify defects such as cracks, scratches, or missing components. In this way, only high-quality items make it to customers. Also, it helps to reduce waste and detect assembly errors. - Damage detection
Advanced AI-powered imaging can spot signs of damage, such as dents, corrosion, or fractures, in products or infrastructure. This is particularly valuable for industries like construction, automotive, and aerospace. - Equipment and retail inventory management
AI visual inspection helps monitor equipment for wear and tear to undertake maintenance measures and prevent downtime. In retail software development, it can track inventory levels and identify damaged goods. - Agricultural inspection
AI can identify early signs of plant diseases or stress, allowing for targeted interventions. For example, AI inspection can be used to detect early-stage palm tree infections by identifying changes in leaf color or holes in the trunk. Being equipped with this technology, agricultural companies ensure timely treatment and prevent crop loss.
How AI Defect Detection Works
AI-based defect detection relies on deep learning to replicate the decision-making process of a skilled inspector. Advanced systems must identify a wide range of defects, distinguish between critical and non-critical flaws, and incorporate data-driven insights from previous inspections. Achieving this level of sophistication requires processing vast amounts of data.
By leveraging deep learning, the system can analyze extensive datasets of labeled images to extract patterns, classify new data accurately, and learn by example. The goal is to develop an AI system that can evaluate parts and surfaces with remarkable precision, addressing complex scenarios such as cosmetic flaws and nuanced defect categorization.
AI Defect Detection: It’s All About Data
The accuracy of AI defect detection systems hinges on two critical factors: the quantity and quality of the data used for training. Manufacturers can contribute to the success of such projects by gathering comprehensive and relevant datasets that align with their production environments.
Here are some essential elements that impact the quality of AI defect detection models:
- High-quality labeled data
The system requires labeled images captured under consistent conditions, such as uniform lighting, angles, and camera resolution. This ensures that the AI performs reliably in real production environments. - Balanced and comprehensive dataset
An exhaustive dataset, including a sufficient number of defective and non-defective samples, is crucial for the AI to generalize accurately across different products and defect types. - Generalization capabilities
AI-powered systems equipped with deep learning models can generalize patterns across surfaces and defect types. As a result, such systems can detect subtle issues, such as texture irregularities or cosmetic flaws without human engagement, providing 24/7 operation.
Importance of Data Sufficiency
Datasets for AI defect detection systems must correspond to the actual conditions under which these systems will operate, including lighting, angles, and equipment used on the production line.
Also, it’s important to cover production variability by collecting data that represents the full range of products, including different types, sizes, materials, and potential defects. For example, identifying defects in fasteners or spare parts requires examples from the entire product range, covering surface defects, mechanical damage, and issues like improper coloring.
Collecting Data in Real Production Conditions
The most reliable data comes from the production line where the AI system will be deployed. By collecting images or videos under real-world conditions, manufacturers can ensure:
- Consistency between the training data and the system’s operational environment
- Better accuracy in detecting defects once the system is live
Continuous Improvement Through New Data
After deploying the AI inspection system, manufacturers can gather additional data during production. This new data can be a part of the updated datasets used for retraining, addressing previously unaccounted-for variations or defect types. To improve accuracy, new data must be labeled and evaluated against the current model’s performance. With new datasets and Iterative training, the system’s ability to detect defects improves over time.
Complex Applications Require Larger and Specialized Datasets
Certain applications, like detecting defects in railway tracks or pipelines, require even more extensive datasets. These systems must process large volumes of images and videos while accounting for:
- Navigation-based context (e.g., defect location on a track)
- Measurements such as roll angles or elevation changes
The success of an AI defect detection system depends on all parties involved in the development process and the collaboration between the engineering team and manufacturer. By dedicating resources to gathering sufficient and high-quality data, manufacturers ensure that:
- The AI model can learn effectively during its initial training phase
- The system achieves high accuracy in real-world applications
6 Steps to Build an AI Defect Detection System
Building an AI defect detection system from scratch requires a well-structured plan. It will usually include clearly defined stages, such as business analysis, choosing a deep learning approach, data gathering and labeling, development phase, training and evaluation, and deployment with further improvements.
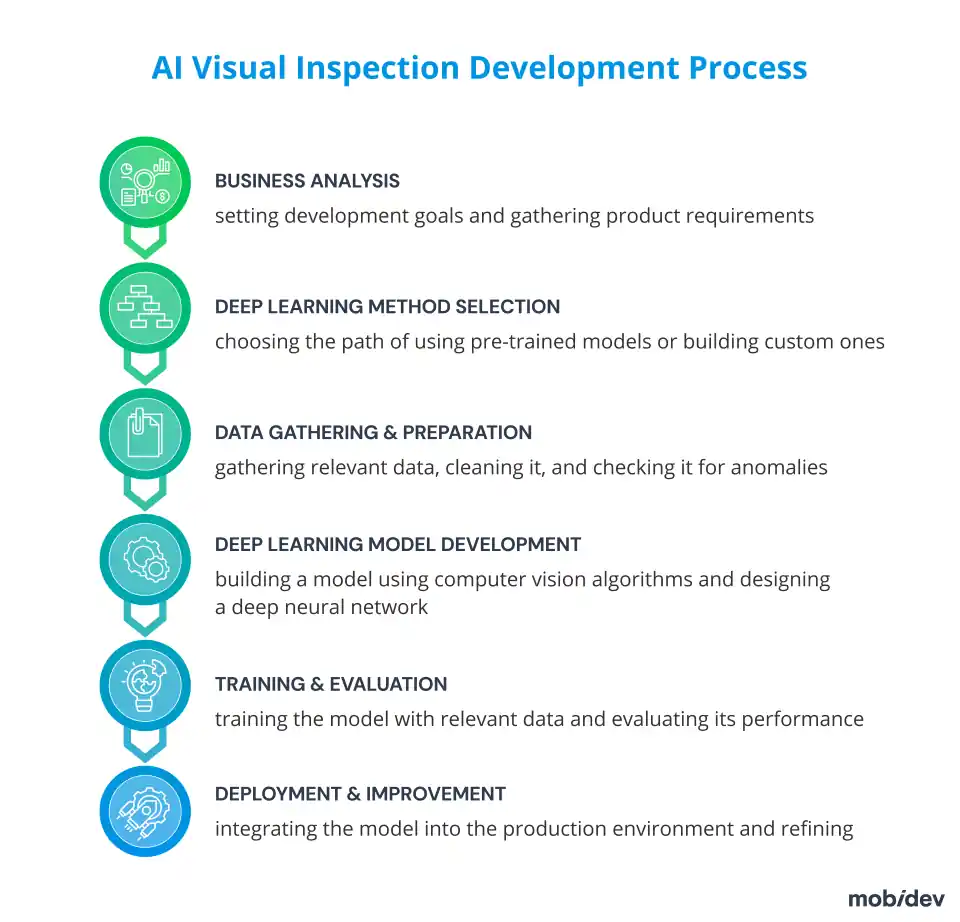
1. BUSINESS ANALYSIS STAGE
The development of AI-based visual control software, like any AI app development process, should start with a business analysis. It is necessary to comprehensively and clearly outline the client’s specific business problem, which will be solved by the visual inspection software product based on the available data.
When setting development goals and gathering product requirements, the core need is to determine what kind of defects the system should detect. It is also essential to find the answers to the following questions:
- Does data for deep learning model development exist, including images of “good” and “bad” products and the different types of defects? This question can be considered key.
- What is the automatic visual inspection system environment?
- Should the inspection be real-time or deferred?
- How thoroughly should the visual inspection system detect defects, and should it distinguish them by type?
- Is there any existing software that integrates the visual inspection feature, or does it require development from scratch?
- How should the system notify the user(s) about detected defects?
- Should the visual inspection system record defect detection statistics?
Having formed a set of documents that define the aims and tasks of the project, you can move on.
2. DEEP LEARNING METHOD SELECTION STAGE
This stage involves a fork in the road. It is necessary to make a decisive choice for the project between the search for a pre-trained model, if it is possible to choose one, and the building of a custom model from scratch. The selection of a deep learning model development approach depends on the complexity of your task, required delivery time, and budget limitations.
Using pre-trained models
A pre-trained model is a deep learning model that is trained on large datasets and can accomplish tasks similar to the one you want to perform. It provides significant time and cost savings but might require fine-tuning to match the features of your production line. This approach works well to improve metrics if such a model is trained on at least somewhat similar data. Meanwhile, there is a pitfall on this path, it may be fiendishly difficult to find a relevant model for some cases.
Deep Learning model development from scratch
Custom model training can be time and effort-intensive, though the results are worth the effort. This method is ideal for complex visual inspection systems and solving specific business issues. After all, such a product can be endowed with all the necessary functionality and optimized for the manufacturer’s needs.
However, the main challenge is data availability. Data in small volumes will not bring the proper effect in detecting defects since it will not be enough for gradual training and improvement of deep learning systems.
The inability to obtain the necessary data can be an insurmountable obstacle for newly launched businesses. This is why AI defect detection development is more affordable to production pipelines that run long enough to collect data. In contrast, companies that have just appeared or are just planning to implement new production lines do not yet have the necessary data and cannot always acquire them.
Choosing the right option
The availability of relevant data significantly increases the probability of building a working system, both in custom development and based on an off-the-shelf AI visual inspection solution. However, the more unique your product`s defects are, the less likely they are to be covered by pre-trained models. This should be considered when choosing between custom development and ready-made software. The two examples below will show how it works in practice.
- Upon visual inspection for pharmaceutical manufacturing, it is necessary to differentiate air bubbles from particles in products. The presence of bubbles is the only defect category here. So, the required dataset will not be extensive. The optimal approach to building computer vision defect detection software might be to use a pre-trained model over training from scratch.
- Or, let’s say that we’re developing a visual inspection model for defect detection in construction. The main focus is to identify defects on the walls. Defect categories might be incredibly diverse, from peeling paint and mold to wall cracks. Therefore, an extensive dataset is necessary to obtain accurate visual inspection results. A pre-trained model approach may be viable in some cases. But still, the optimal approach here would be to develop an instance segmentation-based model from scratch.
3. DATA GATHERING AND PREPARATION STAGE
From our extensive experience developing AI apps in various domains, we know that the probability of getting perfect ready-made datasets is the same as finding a faceted diamond in a diamond mine.
Therefore, our AI engineers can gather and prepare the data required to train a future model before deep learning model development starts.
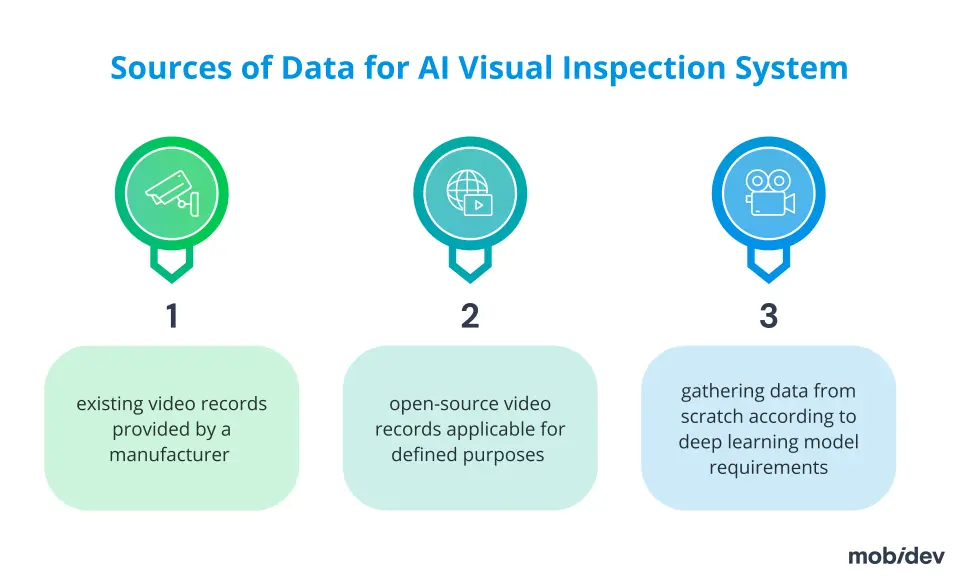
There are several possible sources of obtaining such data, but the most common are:
- videos from the actual production line
- open-source video records applicable for defined purposes
- gathering data from scratch according to deep learning model requirements
Much of the data for the AI visual inspection models comes from video footage captured on production lines. The video record’s quality does matter. Higher-quality data will lead to more accurate results.
Having gathered the data, AI engineers prepare it for modeling, improving the quality. They clean it, check it for anomalies, and ensure its relevance to form working datasets for developing and training a deep learning model. Preparation of gathered data includes at least two essential components:
- Data Labeling
- Exploratory Data Analysis (EDA)
Data labeling
Specialists should label each piece of collected data with informative tags. In this way, images are identified, and their details are characterized. This is all necessary for training the model. To develop a visual inspection system, for example, such tags may contain an indication of the presence of a defect and its type, and perhaps some helpful comments, etc.
Labeling of visual data includes, in particular, the following:
- Data labeling for classification consists only in putting images into some categories
- Detection requires labeling bounding boxes with the objects of classes we need
- Segmentation requires selecting very specific areas of the image
Exploratory Data Analysis (EDA)
In Exploratory Data Analysis (EDA), AI engineers perform statistical analysis of images to find the proper way to normalize them and check whether the dataset is balanced. In data cleaning, specialists check data for errors, lacking values, and inconsistencies, and identify and remove outliers.
At this stage of the data work, it is critical to identify and eliminate bias in the data, i.e., the overweighting or overrepresentation of certain elements of the dataset. The use of a balanced, unbiased dataset increases the accuracy of the deep learning model’s defect detection. Data Quality Assessment at the end of EDA allows you to make sure the data set is suitable for further steps in building the AI visual inspection system.
Note that the latest ML trends and advancements like Segment anything, foundation models, and Multimodal Language Models (LLMs) open new possibilities for defect detection data labeling. These models can be used for preliminary data labeling automation and help speed up the data labeling process. However, to use them, you have to pay for tokens. If you have a huge amount of data, this can be costly.
4. DEEP LEARNING MODEL DEVELOPMENT STAGE
When developing custom visual inspection models, AI engineers use one or, if necessary, several computer vision algorithms, which depend on business goals and specific issues.
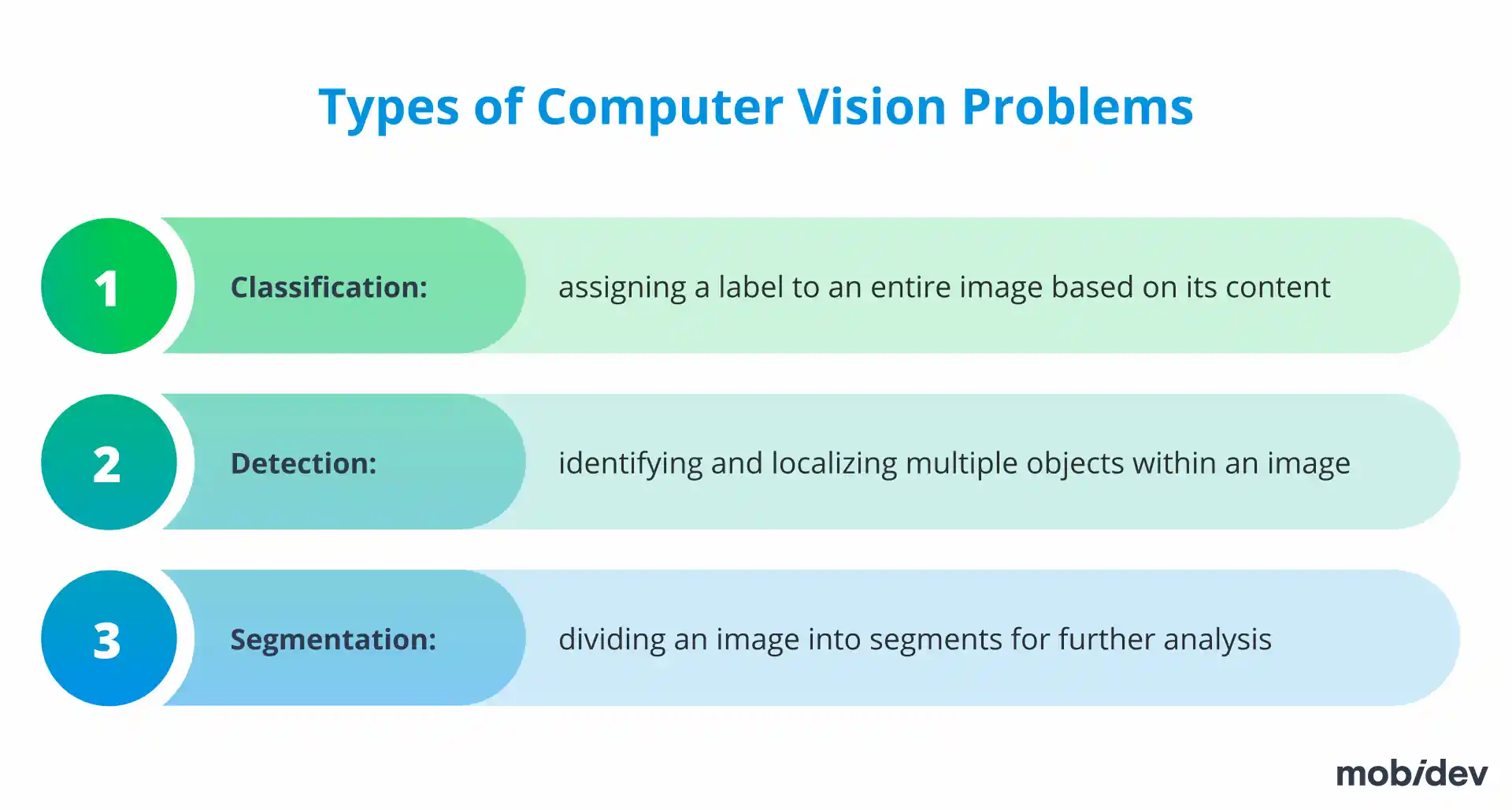
To develop AI defect detection software, depending on business requirements, it is necessary to focus on different types of computer vision problems:
- Classification: It works well for the case when we have only one product in the frame, and we need only to know if it is good or defective
- Detection: It takes place when we need bounding boxes for each product
- Segmentation: We deal with it when we need to understand which pixels belong to which object
Creating one automated visual inspection system may require coping with several types of computer vision problems. We can, for example, combine a detection model to find separate products and then use a classification model to understand if it has any defects.
Many factors influence the choice of a deep learning algorithm(s). These include:
- Business goals
- Size of objects/defects
- Lighting conditions
- Number of products to inspect
- Types of defects
- Resolution of images
Depending on the agreed parameters of the model, AI engineers design the architecture of a deep neural network. The created neural network architecture and prepared large datasets of labeled data are necessary to train a deep learning model for AI visual inspection.
5. TRAINING & EVALUATION STAGE
The next step is to train the built AI visual inspection model. For these purposes, AI professionals split the data set into training, validation, and testing datasets.
For example, in our case, a test dataset can be built from video recordings made on the production line. This requires getting separate frames from videos and labeling them. Such a set of labeled images is suitable for use in the creation of an automated visual inspection system.
Fundamental to model training is the loss function, which compares the target and predicted output values, thereby showing how well the neural network models the training data.
Completing the training and evaluation stage, AI engineers validate and evaluate the performance and result accuracy of the model.
6. DEPLOYMENT & IMPROVEMENT STAGE
When deploying a vision inspection system, the software and hardware architectures must match the model’s capabilities.
Let us briefly describe the main elements of the AI visual inspection system.
Software
Visual inspection software includes web modules for data transmission and a module for neural network processing. The key parameter here is data storage. There are three common ways to store data: on a local server, a cloud streaming service, or on serverless architecture.
The choice of data storage solution often depends on the functionality of the deep learning model. For example, if a visual inspection system uses a large data set, a cloud streaming service may be the optimal choice.
Hardware
Depending on the industry and automation processes, devices required to integrate a visual inspection system may include:
- Camera: The main camera option is real-time video streaming. Some examples include IP and CCTV.
- Gateway: Both dedicated hardware appliances and software programs must work well for a visual inspection system.
- CPU / GPU: If real-time results are necessary, a GPU would be a better choice than a CPU. The point is that the GPU boasts a faster processing speed when it comes to image-based deep learning models. It is possible to optimize a CPU for operating the visual inspection model, but not for training. An example of an optimal GPU might be the Jetson Nano.
- Photometer (optional): Depending on the lighting conditions, the visual inspection system may require photometers.
- Colorimeter (optional): When detecting color and luminance in light sources, imaging colorimeters have consistently high spatial resolutions, allowing for detailed visual inspections.
- Thermographic camera (optional): In the case of automated inspection of steam/water pipelines and facilities, it is a good idea to have thermographic camera data. Thermographic camera data provides valuable information for heat/steam/water leakage detection. Thermal camera data is also useful for heat insulation inspection.
- Drones (optional): Nowadays, it is hard to imagine automated inspection of hard-to-reach areas without drones. Some examples are building internals, gas pipelines, tanker visual inspection, and rocket/shuttle inspection. Drones may be equipped with high-resolution cameras that can do real-time defect detection.
The complete set of hardware for AI visual inspection for defect detection has many options. For example, there are many manufacturer requests to use for visual inspection purposes portable devices like Raspberry PI or Arduino computers. Likewise, in some situations of practical application of image processing defect detection, it is useful that compact but powerful Nvidia Jetson Nano or Nvidia Jetson Xavier can work in pairs to perform optical analysis.
A valuable feature of deep learning models is that they can be refined after deployment. A deep learning approach can increase the accuracy of the neural network through the iterative gathering of new data and model re-training. The result is a perfected visual inspection model that can be trained by increasing the amount of data during operation.
Build your AI inspection system for defect detection with MobiDev
With over a decade in software development and 6 years of expertise in AI, MobiDev can assist you in developing a modern AI inspection system. The MobiDev team can find a custom approach to any product need, starting from RnD research for scientific institutions to implementing a custom AI inspection system for manufacturing environments with strict security limitations.
Tap into our expertise to seamlessly integrate pre-trained models or develop custom AI solutions tailored to your unique data and business requirements. With dedicated in-house AI labs focused on R&D, our team is ready to meet any challenge and provide AI consulting or AI development services!


