


Contents:
AI-driven demand forecasting and planning software is a powerful tool for retail and hospitality operators struggling to manage demand shocks and tighter margins. Fluctuations in demand, especially for perishable products, are often a major budget leak because it is difficult to predict demand accurately, in a timely manner, and regularly.
The ReFED/2023 data show that 31% of the nation’s 237 million-ton food supply went unsold. The U.S. restaurant sector generates 11.4 million tons of food waste annually estimated to cost more than $25 billion.
Traditional demand forecasting ERP add-ons and spreadsheets scramble to keep pace, while full system replacement is too risky.
AI-driven demand forecasting modules offer a practical upgrade that can deliver tangible wins without core-system surgery being required.
In this article, we’ll share our experience in developing machine learning modules for AI demand forecasting and planning, based on MobiDev’s 7+ years in AI consulting & engineering and 15+ years in general software development. We will elaborate on frequent concerns about what AI demand forecasting systems are capable of, and what you’ll need to develop one for your specific business case.
Why AI-Driven Demand Forecasting Should Top Your 2025 Agenda: Executive Summary
The implementation of AI demand forecasting and planning can answer the recurring questions more swiftly:
- How often does inventory need to be replenished?
- What are the required stock levels for each SKU?
- How do you calculate demand for different selling points?
- How do you manage inventory when anomalies occur?
Traditional demand forecasting models rely on historical sales alone and assume stable seasonality patterns. Machine learning models analyze POS data enriched with promotions, weather, and foot traffic, including third-party signals. Algorithms self-tune every week, flagging SKU-store anomalies before they erode margin.
The impact is tangible and already proven in the field:
- 65% less lost-sales from stockouts after one season
- 20 – 50% less excess inventory, freeing tied-up working capital
- 25% jump in customer retention rates thanks to better on-shelf availability and targeted promotions
- 20-50% reduced forecasting errors over traditional spreadsheet-based analytic methods
To learn more about a real-world example of how AI demand forecasting drives real business impact get our use case:
A SMARTER WAY TO PLAN
Learn how businesses can cut stockouts by 65% and boost customer retention by 25%
DOWNLOAD THE USE CASEBelow you can find more detailed information about AI demand forecasting.
Demand Forecasting: The Basics
Sales and demand forecasting are closely related terms but use different sets of data. While sales forecasting requires only historical data generated through actual transactions, demand forecasting may also include weather reports, customer surveys, web analytics, social media scraping, etc.
Businesses-wise, it can make sense to start gradually with the development of a sales forecasting system if there is not enough qualified demand data. However, for both types of forecasting systems, it’s essential to understand that they are vulnerable to anomalies or unpredictable situations. It means that machine learning models should be upgraded according to the current reality.
AI Demand Forecasting Implementation Readiness Checklist
Before you wire money into a pilot, run through this AI demand forecasting implementation readiness checklist. If you perform demand forecasting in some manual form with the help of spreadsheets, you might already have a set of data that you use for calculations. So, at this point, it already makes sense to think about automating the whole process with machine learning if you have a number of preconditions.
1. CHECK DATA AVAILABILITY
Even though sales data is the most available piece of information for working with machine learning forecasting models, demand forecasting requires more than just historical sales. If you already set up some processes and infrastructure to collect data on your internal and external factors, it can be used for machine learning easier than collecting it from scratch.
Additionally, if you already have historical data for multiple years from the past, it will allow you to start developing an AI solution and already bring value. Predicting inventory level implies we need your specific sales, which can’t be sourced elsewhere or bought on a dataset market.
2. SET PREDICTION FREQUENCY
Different business types will require different frequencies of demand forecasting. Conducting analysis on a monthly or even weekly basis can be a challenging task in terms of manual forecasting.
In this case, it’s a no-brainer that using machine learning frees up the resources, because it enables an automated pipeline that gathers data and provides demand forecasts for given periods. One thing to keep in mind is that, the shorter the forecasting period, the less accurate it will be, since it’s impossible to generate enough data to cover all the required time changes.
3. UNIFY DATA FROM MULTIPLE VENUES
For businesses owning multiple selling points that are set across different regions, traditional demand forecasting will require a lot of human resources since seasonality, geography, and competition will all be different.
Based on our experience building AI demand forecasting modules for our clients, the use of machine learning is a large competitive advantage. This is because your business obtains better visibility and frees up human resources for development activities, rather than focusing on operational things.
Setting up a system that sources data scattered across multiple databases and presents analytics through a single dashboard, reduces the cost of demand forecasting in retail itself. In turn, a unified analytical solution presents a 360 view of your venues, inventory and sales activities allowing more flexibility in terms of planning and inventory management.
From a technical standpoint, creating forecasts for multiple venues in most cases doesn’t require developing separate models for each specific case. The same goes for forecasting each separate product demand because we only need a suitable set of data that we can aggregate and properly feed to the model.
Top 5 Factors That Influence AI Demand Forecasting Accuracy
Now, speaking of an actual demand forecasting model, we need to discuss what external and internal factors can impact its work. Since the machine learning (ML) model will make its predictions from past events, its prediction accuracy rate is unlikely to be 100%. However, by understanding the following things, we can mitigate those risks on the stage of building the actual model.

1. PRODUCT TYPES AND MODELING ERRORS
The product type is an important factor to consider for the ML demand forecasting model selection.
Example: for a perishable item that has an actual demand of 100 cases, the prediction of selling 90 cases is preferred over the prediction of 110 cases. Missing the sales of 10 cases is a better result than wasting 10 cases, even though the actual error is the same percentage.
2. SEASONALITY
For each product, the seasonality cycle plays a crucial role in predicting demand.
Example: if you sell tents for hiking, seasonal growth in demand appears to be during the summer period, with peaks in a certain month in your area.
If we take the data for only 5 months for training the ML model, the prediction of the machine learning model won’t give accurate results, since we need a year’s data as a bare minimum to calculate the seasonality.
For products that don’t fluctuate in demand seasonally, say forks and spoons, a three-month data set will be enough to start training the model and producing forecasts. But it always depends on the item itself and other external factors like competition, or amount of holidays for a given period.
3. REGIONAL IMPACTS ON MODEL PERFORMANCE
Machine learning demand prediction models are strongly influenced by regional factors that include customer behavior and cultural determinants:
- Marketing campaigns may be regionally specific and have a different impact that depends on where a customer is located.
- Holidays may vary between regions, which might be a consideration for adjusting the model.
- Legal issues/laws may limit the use of certain data in different regions.
4. EXTERNAL DATA RICHNESS
Relying on POS history alone leaves your model blind to the real-world forces that actually move demand. External data sources, such as promo calendars, weather swings, mobility trends, and local events, feed the algorithm the context it needs to separate signal from noise. According to BCG’s 2023 study on AI-driven integrated business-planning platforms, enriching ML forecasting models with external signals boosts forecast accuracy by 10% compared to raw data baselines.
So, it is recommended to add this information dynamically to your AI demand forecasting model.
5. ECONOMIC SITUATION
The state of the economy influences businesses and ML demand forecasting models.
Example: periods of economic decline are likely to cause lower demand for expensive products, though sales of low-priced goods may go up. Therefore, an economic situation, as well as trends, aren’t external factors and should be considered when building artificial intelligence models.
5-Step Roadmap to Implementing AI Demand Forecasting
Now, let’s discuss the practical steps to implement AI demand forecasting. Before embarking on ML demand forecasting model development, you should understand the workflow of ML modeling. What follows offers a data-driven roadmap of how to optimize the implementation process.
STEP 1. DATA GATHERING
The first step when initiating AI demand forecasting module development is to make sure that the data amount and quality is enough to provide meaningful insights.
When we start working with a client, we gather available data, and briefly review its structure, accuracy, and consistency. Then we run a few data tests and look through a statistical summary.
In our experience, a few days is enough to understand the current situation and outline possible solutions. This is a part of data science exploration that requires the involvement of the client to gather the data and provide the most relevant corporate storage.
This stage is a part of the AI consulting process aimed at finding the best possible solution that syncs your business goals, tech capabilities, and market needs.
STEP 2. SETTING BUSINESS GOALS AND SUCCESS METRICS
Before coming to the stage of developing an AI demand forecasting solution, we need to agree with stakeholders on target SKUs, time horizon and accuracy thresholds (MAPE, MAE or custom).
Success metrics offer a clear definition of what is “valuable” within AI demand forecasting. A typical message might state:
“I need a machine learning solution that predicts demand for […] products, for the next [week/month/a half-a-year/year], with […]% accuracy.”
This statement example will help you to identify what your success metrics will look like.
Pro Tip: Aim for data latency below 24 hours to have yesterday’s POS transactions land in your data warehouse during the early morning batch window. This allows today’s forecast to include yesterday’s sell through, promo uplift, and stockouts. Anything slower forces the model to learn from stale signals and misforecasts shortlife SKUs. If you operate flash sales or Q-commerce, consider an ≤ 1 hour latency to enable intraday re-forecasts when weather or social media buzz changes demand multiple times a day.
Treat different categories that come at the same time each month (e.g., perishable groceries, fashion apparel, subscription services) differently. Perishables need fine-grained, shelf life-aware models, while fixed interval subscriptions follow predictable renewal curves. Separate models keep seasonality, price elasticity, and life cycle dynamics from smearing across the portfolio.
STEP 3. DATA UNDERSTANDING & PREPARATION
Regardless of what we’d like to predict, data quality is a critical component of an accurate AI demand forecast. The following data could be used for building ML forecasting models:
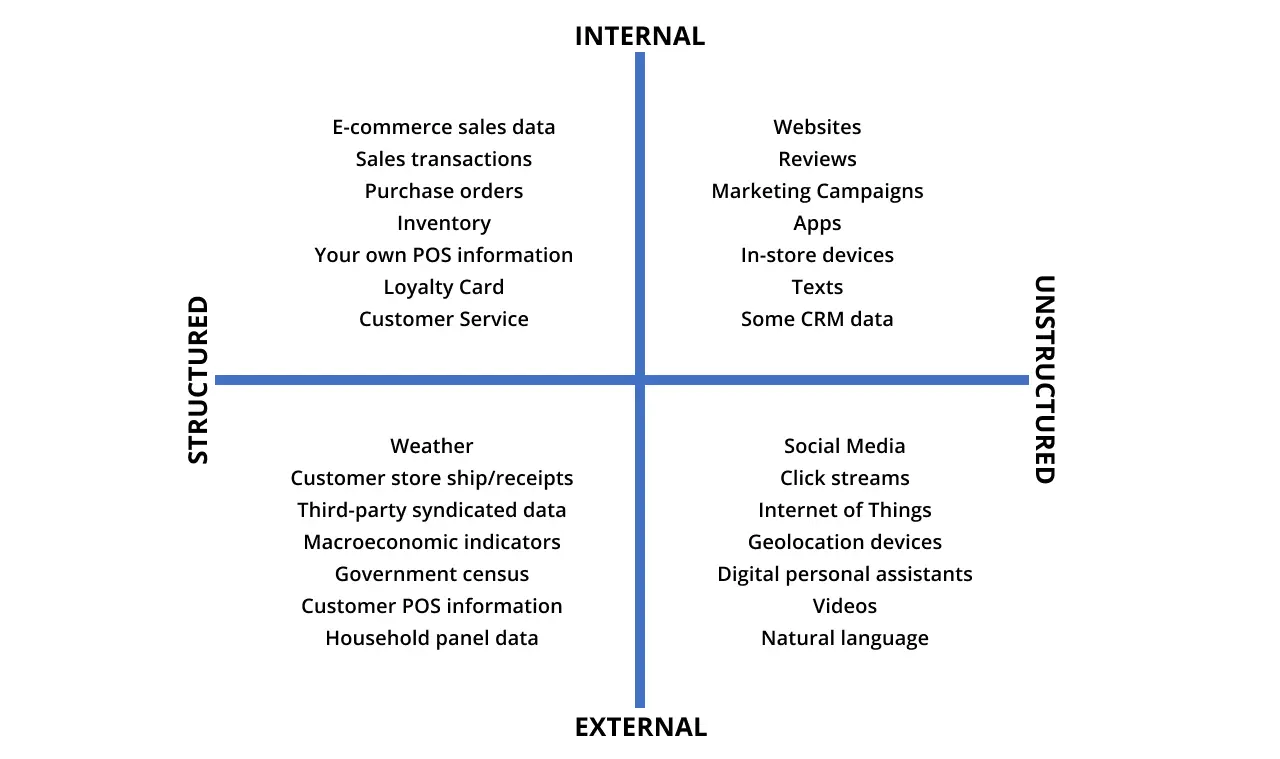
When building an ML forecasting model, the data is evaluated according to the following parameters:
- Consistency
- Accuracy
- Validity
- Relevance
- Accessibility
- Completeness
- Detalization
In reality, the data collected by businesses often isn’t ideal. It usually needs to be cleaned, analyzed for gaps and anomalies, checked for relevance, and restored. That’s why data science consultants should be involved at this stage.
Data understanding is the next task once preparation and structuring are completed. It’s not modeling yet but an excellent way to understand data by visualization. Below you can see how we visualized the data understanding process:
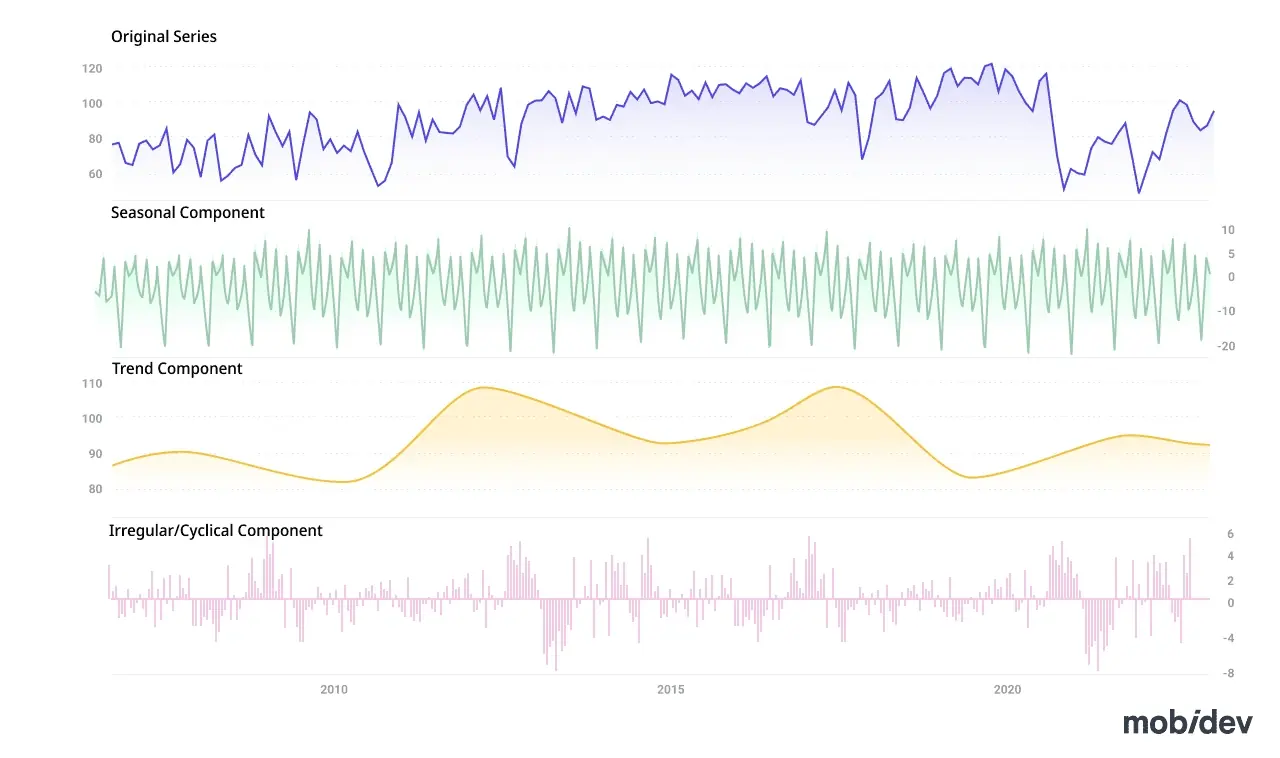
This visualization demonstrates data decomposition, extracting trends, and seasonal or other factors from input data. It’s divided into several graphs:
- The 1st graph is an original timeline (time series visualization)
- The 2nd, 3rd, and 4th graphs separately represent seasonality, trends, and noise for further analysis and forecasting.
STEP 4. MACHINE LEARNING FORECASTING MODEL DEVELOPMENT
There are no “one-size-fits-all” demand forecasting algorithms. The choice of machine learning models depends on several factors, such as business goal, data type, data amount and quality, forecasting period, etc.
However, there are multiple approaches to that, and they are often combined under the hood of a single AI demand forecasting system. The following approaches are used for demand forecasting and have proven to be the most efficient:
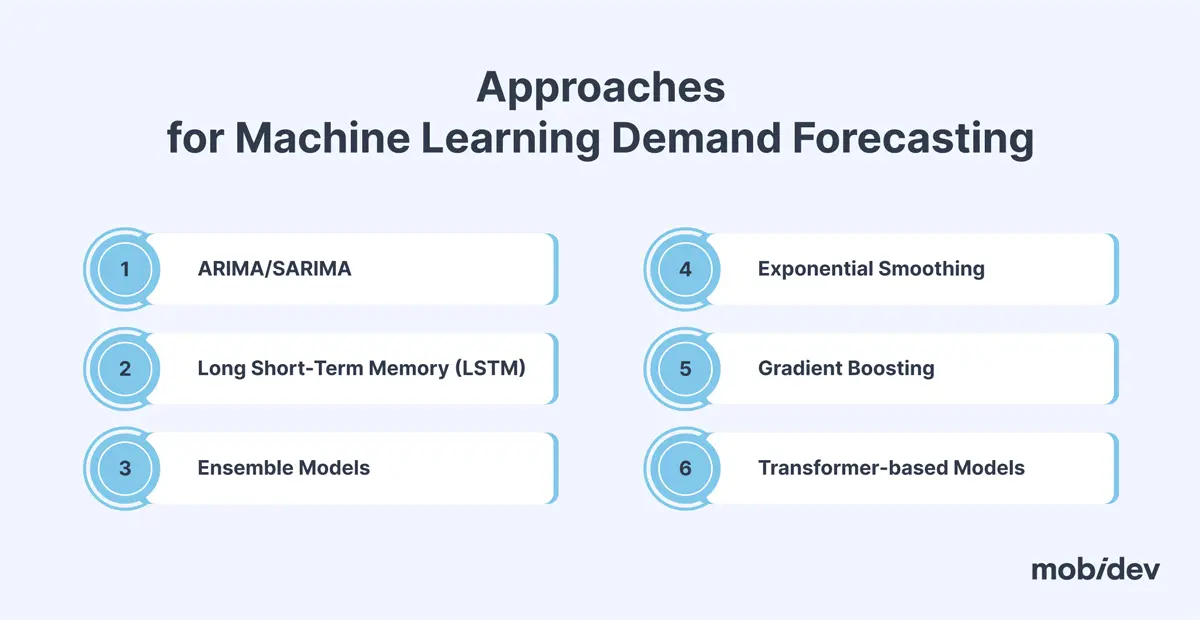
- ARIMA/SARIMA
- Exponential Smoothing
- Regression models
- Gradient Boosting
- Long Short-Term Memory (LSTM)
- Ensemble Models
- Transformer-based Models
The topic of using ML models in analytical systems is much wider and covers not only retail cases. So if you want a much deeper insight into various models and approaches, read our dedicated article.

STEP 5. DEPLOYMENT INTO PRODUCTION
Once we have the data, we can start the training, validation, and improvement procedures. This process is done iteratively until the model achieves the maximum desired results.
A demand forecasting ML model can be used in its raw form, presenting its predictions in some sort of table, or sending emails with analytics for a certain period. However, more commonly, we would also develop a front-end part of the application which is basically a dashboard that presents insights and visualizations through a single interface. It allows the user to query different reports, share them with the stakeholders, customize visualization types, etc. After testing and approval, the product is deployed into the production environment.
One thing to mention is that to keep the demand forecasting capabilities up to date, the model will require constant updates with new data. These can be your daily transactions or inventory turnover. For this purpose, we recommend setting up an automated pipeline that regularly aggregates recent data and updates the prediction model accordingly. It will help to keep the reliability of the developed AI demand forecasting model on a regular basis.
How long does it take to develop an AI demand forecasting module?
Most projects follow a three-phase arc Pilot/Proof of Concept > MVP > Production rollout. Please refer to the table below for a detailed breakdown.
| # | Project Phase | Typical Duration | Tasks | Core Roles |
|---|---|---|---|---|
| 1 | Pilot / Proof-of-Concept | 4-6 w | Feed POS data, train a baseline model, validate outcomes | Data Scientist, Analyst |
| 2 | MVP Development | 8-12 w | Expand to the full SKU set, add external signals (promos, weather), deploy behind a dashboard or API | + ML Engineer |
| 3 | Production Roll-out | 12-20 (Complex, multi-country catalogs or legacy data silos push timelines toward the upper end) | Set up the CI/CD pipeline (MLOps), automated retraining, and integrate with ERP or planning tools | + MLOps / DevOps |
How much does it cost to build an AI-driven demand forecasting system?
Below you can find an approximate price breakdown for all 3 stages of the AI demand forecasting system development. Actual pricing depends on data complexity, accuracy targets, and user interface implementation.
| # | Project Phase | Scope & Deliverables | Cost Range (USD) |
|---|---|---|---|
| 1 | Pilot / Proof-of-Concept | Slice of POS data, baseline ML model, KPI validation | $16k – $24k |
| 2 | MVP Development | Full-SKU coverage, external signals (promos & weather), cloud infrastructure, MLOps scripts, dashboard/API | $40k – $65k |
| 3 | Production Roll-out | Multi-region scaling, automated retraining, 24 / 7 monitoring, change-management workshops | $90k – $190k |
Handling Anomalies, Outliers & Black-Swan Events in AI Demand Forecasting
As ML demand forecasting models process historical data, they can’t know if the demand has radically changed. For example, if last year, we had one demand indicator for a certain type of consumer product, it can change next year due to economic turbulence, or supplier countries being cut off from exports.
In that case, there might be several ways to get an accurate forecast. Here are the five most common ways:
- Collect data about new market behavior. Once the situation becomes more or less stable, develop an AI demand forecasting model from scratch.
- Apply a feature engineering approach. By processing external data, news, a current market state, price index, exchange rates, and other economic factors, machine learning models are capable of making more up-to-date forecasts.
- Upload the most recent data and provide it with the highest weights during model prediction. The period of a loadable dataset might vary from one to two months, depending on the products’ category. In this way, we can detect shifts in demand patterns and enhance forecast accuracy in a timely manner.
- Apply the transfer learning approach. If there is any gathered historical data, we can use it to predict demand in the context of the current crisis.
- Apply the information cascade modeling approach. We can forecast how people will make buying decisions according to the behavior patterns of most people.
During AI demand forecasting system development, data science engineers analyze historical data for forecasting. This forecasting cannot predict the disruption caused by a global pandemic, a war, or a cataclysm, for example. Such an event requires the future retraining of machine learning models.
But keep in mind that after the demand situation normalizes after the black-swan event, you need to reset your model back, otherwise the model can remember the event’s pattern and falsely predict it for the next short-time period (e.g. next year).
Now let’s take a look at our client’s success stories to learn how AI demand forecasting system implementation looks in practice.
Addressing Anomalies and Unpredictable Situations in AI Demand Forecasting
As the demand forecasting model processes historical data, it can’t know if the demand has radically changed. For example, if last year, we had one demand indicator for a certain type of consumer product, it can change next year due to economic turbulence, or supplier countries being cut off from exports.
In that case, there might be several ways to get an accurate forecast. Here are the five most common ways:
- Collect data about new market behavior. Once the situation becomes more or less stable, develop an AI demand forecasting model from scratch.
- Apply a feature engineering approach. By processing external data, news, a current market state, price index, exchange rates, and other economic factors, machine learning models are capable of making more up-to-date forecasts.
- Upload the most recent data and provide it with the highest weights during model prediction. The period of a loadable dataset might vary from one to two months, depending on the products’ category. In this way, we can detect shifts in demand patterns and enhance forecast accuracy in a timely manner.
- Apply the transfer learning approach. If there is any gathered historical data, we can use it to predict demand in the context of the current crisis.
- Apply the information cascade modeling approach. We can forecast how people will make buying decisions according to the behavior patterns of most people.
During AI app development, artificial intelligence engineers analyze historical data for forecasting. This forecasting cannot predict the disruption caused by a global pandemic, a war, or a cataclysm, for example. Such an event requires the future recalibration of the machine learning models.
But keep in mind that after the demand situation normalizes after the pandemic/war/ etc – you need to adjust your model back, since in other cases – the model can remember the pandemic’s pattern and predict it for the next short-time period (e.g. next year).
Now let’s take a look at our client’s success stories to learn how demand forecasting projects look in practice.
Success Story #1: Implementing Data Science Demand Forecasting in a Retail POS System
About the client:
Comcash is a US-based ERP and POS system provider for the retail industry. Back in 2013, the company’s CEO, Richard Stack, engaged MobiDev to rebuild the old product into a robust cloud-based system operating both online and offline 24/7, regardless of internet connection. Since then, the MobiDev team has been working with Comcash on the constant technical development of the solution, delivering advanced features to help the client achieve new goals in the market.
Business goal:
After turning the system into a cloud-based solution, we suggested Comcash implement the demand and sales forecasting modules to extend the POS functionality and gain additional competitive advantage.
How we delivered:
We implemented an adaptive selective model for demand forecasting that predicts demand for the coming weeks based on user retail sales data. The main challenge was to ensure a high level of adaptability of the model to allow users to obtain a forecast for specific products at any given time.
To do this, we used a combination of DS/ML libraries and methodologies, such as Pandas and ABC-XYZ analysis.
Moreover, a statistical report was generated to classify products based on popularity and profitability to help retailers identify the most profitable and least profitable products. This created the basis for advanced sales analytics and planning targeted discount strategies.
Outcomes and achievements:
The increasing popularity of Comcash led to its acquisition by POS Nation in October 2022. Today, Comcash boasts a presence in over 3,000 locations and seamlessly integrates with a wide range of custom hardware.
[Together with MobiDev], we’re able to work on a 24-hour development cycle, and we release software repeatedly faster than any of our competitors — and there is no overtime. We could never create what we have with MobiDev in my office in California. The tech market is just too competitive these days. If you are interested in developing a world-class product and working with a great group of friendly co-workers every day, I wholeheartedly recommend MobiDev.

Read the Full Success Story:
DEVELOPING A LEADING CLOUD-BASED ERP AND POINT-OF-SALE SYSTEM FOR RETAILSuccess Story #2: Building AI Demand Forecasting Module for Venue Chain Management Ecosystem
About the client:
Since 2014, MobiDev has been working with SmartTab, a US-based company providing POS systems for nightclubs and bars. SmartTab’s CEO contacted MobiDev to take over product development and improvement after his collaboration with another software vendor resulted in a pilot version of the app that fell short of expectations.
Over a decade of joint work, has led to the SmartTab system expanding with new enhancements, including AI demand forecasting features.
Project goal:
After building the basic functionality of the POS system, the client was looking to enhance their product with an advanced dashboard allowing venue owners to analyze performance and make plans based on machine learning demand forecasting.
How we delivered:
To achieve the SmartTab project goals, we used a time series approach with a combination of Gradient Boosting and KNN models. The major components to analyze include trends, seasonality, irregularity, and cyclicity. With that, we can predict how much revenue will be earned within the next upcoming year, along with the daily granularity for each venue and total venue chain.
Users can view details on the product range of their venue in a few formats. This includes the pie chart, a 3×3 matrix, and trend-up/trend-down graphs to check the product’s popularity in a dynamic setting. This toolkit helps venue owners and managers make updates to the product range more effectively.
Outcomes and achievements:
Since the beginning of our cooperation in 2014, SmartTab has transformed from a bold startup to an industry leader that serves 1000+ venues and chains. We continue working with the client on product enhancements, including improvements in demand forecasting models.
Leverage AI Demand Forecasting for Your Business With MobiDev
Once you decide to implement demand forecasting, pay attention to the proficiency of a hired team. Demand forecasting projects fall into the category of machine learning and data science, which require in-depth domain expertise for processing data and choosing the right approach to reach your specific business objectives.
MobiDev has been in software development since 2009, including extensive work in the retail software development services. Our portfolio covers not only core functionalities like POS or ERP solutions, but also AI-driven products of different scales and complexity, customization options, and integrations. By combining consulting and engineering expertise, we align each product’s technology choices with specific business objectives.
Contact us to discuss your demand forecasting goals or take a look at the downloadable use case below that shows how machine learning improved demand forecasting for our clients.
A SMARTER WAY TO PLAN
Learn how businesses can cut stockouts by 65% and boost customer retention by 25%
DOWNLOAD THE USE CASE

