

Contents:
Using GPUs for machine learning projects has emerged as one of the key latest trends in AI development. Their specialized design accelerates computations required for machine learning and artificial intelligence algorithms, helping developers and businesses unlock new capabilities.
NVIDIA, which holds around 90% of the GPU market share in 2024, recently stated that over 40,000 companies and 4 million developers are using its GPUs for machine learning and artificial intelligence.
In this article, we’ll share MobiDev’s experience working on AI-driven solutions since 2018. You’ll learn why GPUs are essential for AI projects, their key benefits, and practical use cases.
Why Use GPUs for Data Science and Machine Learning Projects
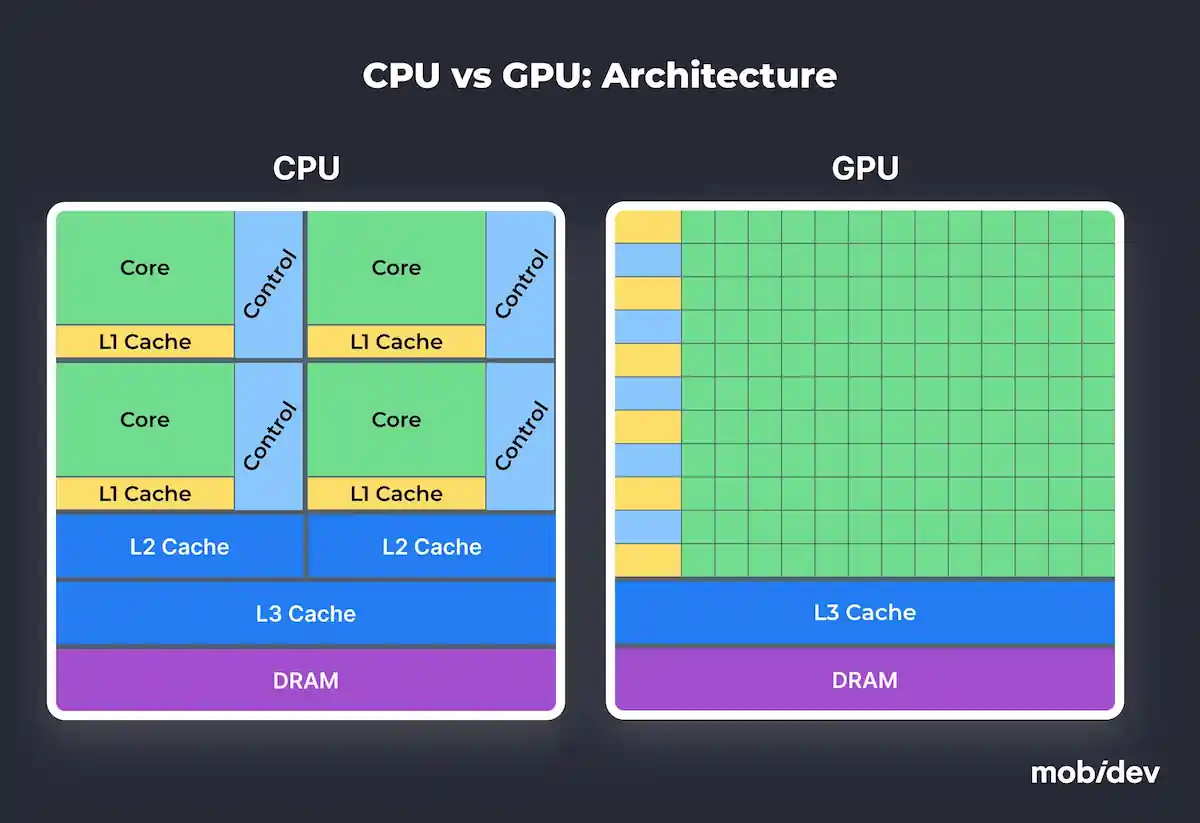
The first thing you’ll notice when comparing CPU vs GPU for machine learning is the difference in processing capabilities. CPUs are great for general-purpose processing. However, GPUs are specifically designed for parallel computations. This allows them to process vast amounts of data and run complex operations all at once. This is especially beneficial for deep learning tasks.
So, here’s why you should use GPU in deep learning:
- Efficient architecture. GPUs have thousands of smaller cores that can perform multiple operations at the same time. For example, in our experience, training deep neural networks on GPUs can be over 10 times faster than on CPUs with equivalent costs.
- Specialized for machine learning. Originally designed for gaming, GPUs today are represented by models focused on machine learning projects as well. GPUs efficiently manage matrix multiplications, which form the backbone of DNN training and inference. The overall computational load is balanced by offloading it from the CPU to the GPU.
- Reduced computational load. The utilization of GPUs enables the CPU to handle additional tasks, enhancing its efficiency.
Check out the table below to see a detailed comparison of CPU and GPU capabilities.
| # | Factor | CPU | GPU |
|---|---|---|---|
| 1 | Processing power | Limited cores, sequential tasks | Thousands of cores, parallel tasks |
| 2 | Training speed | Slow | High |
| 3 | Cost-efficiency | Lower upfront cost | Higher efficiency per dollar |
| 4 | Memory bandwidth | ~50GB/s | Up to 1555 GB/s |
Machine Learning Pipeline With GPU
A typical machine learning pipeline with GPU consists of the following steps:
- Data preprocessing: managed by CPUs, which prepare and organize the data
- Model training & inference: offloaded to GPUs, where intensive computations occur
- Post-processing: returned to CPUs for final adjustments or analytics
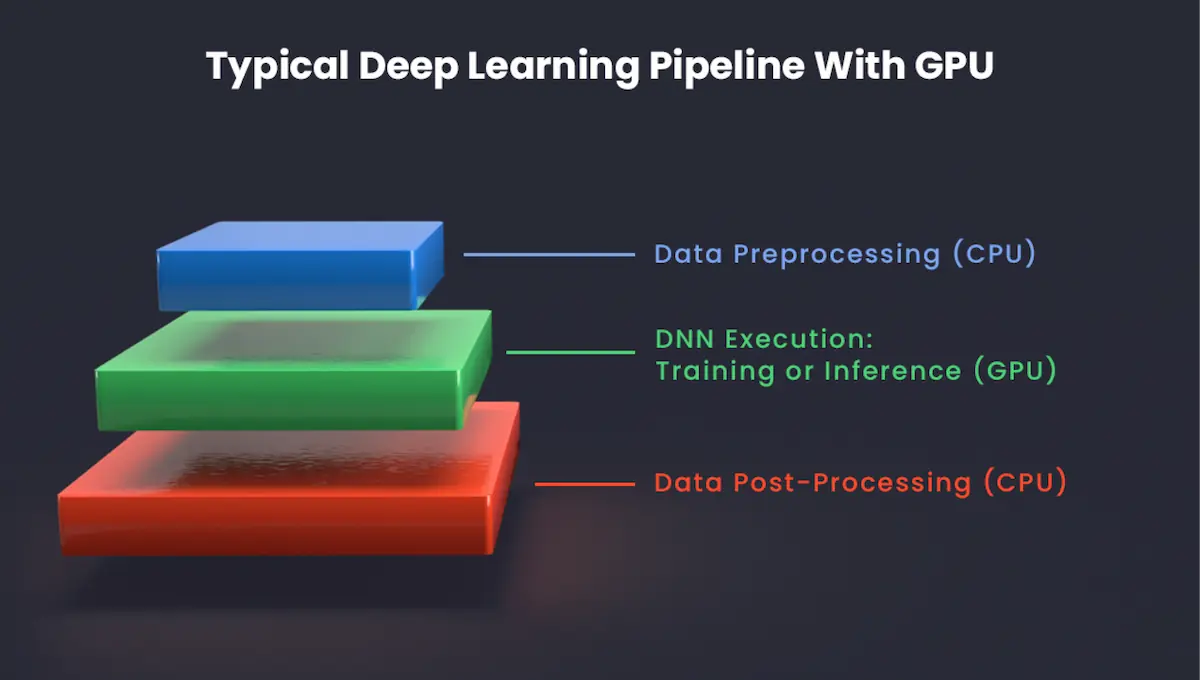
However, you may encounter a bottleneck when transferring data between CPU RAM and GPU DRAM. To mitigate this issue in the pipeline architecture, you can apply the following approaches:
- Batch data: aggregate multiple samples before transfer to reduce transaction frequency
- Filter data: minimize the sample size by removing unnecessary elements before they are sent to the GPU
As a result, we get a working data pipeline that easily works with large-scale datasets and complex models. GPU and machine learning are two inseparable elements in modern data science project architecture. Let’s take a closer look at the benefits in the next section.
5 Key Benefits of Using GPU for AI App Development
The following advantages of using a graphic processing unit for AI app development are listed below based on technical data and our team’s experience.
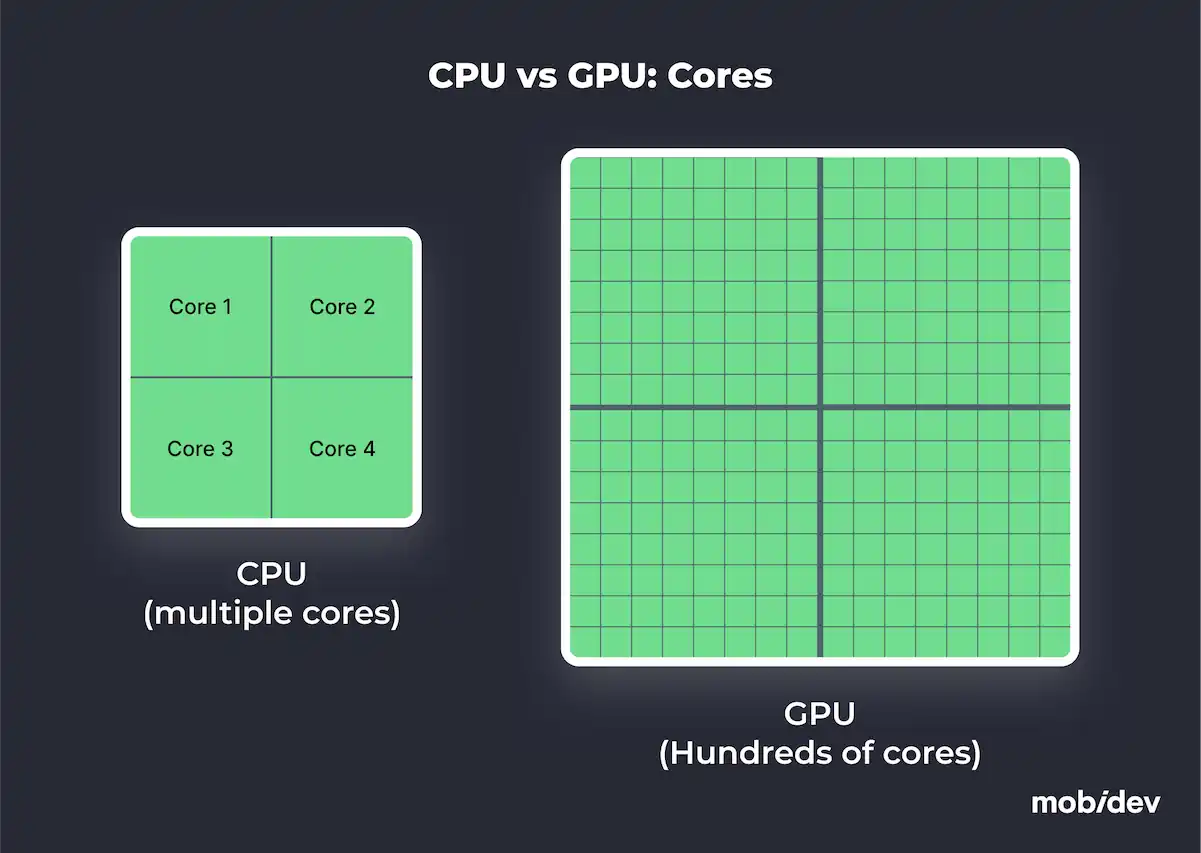
1. Parallel Processing
Parallel processing is the main advantage of a GPU in machine learning. GPUs use thousands of smaller, specialized cores to perform simultaneous calculations. This is the perfect architecture for tasks like training deep neural networks, where multiple operations must be executed in parallel.
For clarification, let’s put this in a simple example. Imagine the GPU has to handle vast datasets during NLP or image recognition. All the data is processed in parallel, reducing computation time as multiple data streams are managed at once. That’s why GPUs are indispensable for scaling AI workloads.
OpenAI used over 10,000 Nvidia GPUs to train ChatGPT, its lead product. Why didn’t they use CPUs? It would take more time, money, and resources. While they still need many more GPUs, such an amount is only the case for global large-scale projects. Projects with simple models focused on a specific task can use a single GPU to train their AI. In contrast, training complex models like LLM from scratch requires thousands of GPUs.
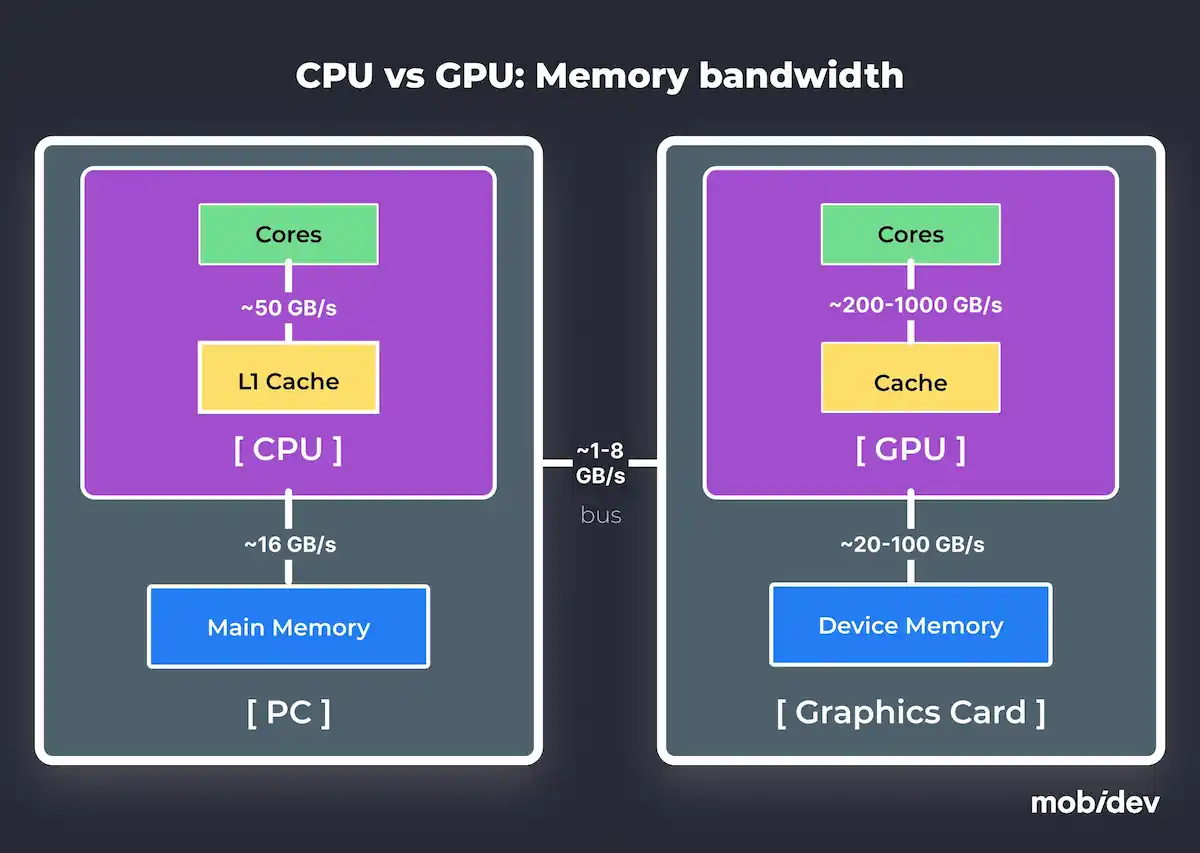
2. High Bandwidth Memory
GPUs are equipped with high-bandwidth memory, enabling rapid data transfer and processing of large datasets. Compared to CPUs, which typically max out at ~50GB/s, GPUs can achieve bandwidths of up to 1555 GB/s.
This feature is crucial for applications involving high-resolution image processing or complex simulations. High memory bandwidth allows GPUs to feed data to their cores without significant delays, ensuring smooth execution of machine learning models, especially those requiring substantial data throughput.
3. Specialized Cores
Modern GPUs feature specialized cores like Tensor Cores (found in NVIDIA GPUs) designed explicitly for deep learning tasks. These cores enhance the matrix multiplication that is foundational to neural network training.
Tensor cores achieve faster and more precise calculations by enhancing these processes. For CTOs managing AI projects, this specialization translates into shorter training times and improved model performance. Multiple research studies prove their efficiency.
4. Large-Scale Integration
Large-scale integration allows GPUs to handle massive computational tasks. This capability allows them to connect multiple units into clusters, enabling distributed training for complex models and datasets. For example, in the development of autonomous vehicles, GPUs process real-time data from sensors, cameras, and LIDAR systems across large networks to ensure rapid decision-making.
Another example includes Large Language Models (LLMs). Many modern LLMs are so large that they exceed the memory capacity of a single GPU. As a result, they need to be split across multiple GPUs to handle their computational requirements.
Another benefit is the enhanced scalability of the modern GPU’s architecture. As project demands grow, additional GPUs can be seamlessly integrated without significant modifications to existing infrastructure. However, this would be an issue with CPUs.
5. Cost-Efficiency
Although GPUs may have a higher upfront cost compared to CPUs, their cost-efficiency becomes evident in large-scale AI applications. A single GPU can replace multiple CPUs for specific tasks, reducing overall hardware and operational budgets.
Moreover, their energy-efficient design minimizes long-term power consumption. If your company is looking forward to balancing performance and budget, then GPUs are the best choice for a high return on investment. This is especially true in AI-driven projects that demand high throughput and precision.
When You Shouldn’t Use GPUs for Machine Learning Projects
GPUs offer exceptional speed and performance, making them indispensable for many AI applications. However, there are scenarios where GPUs may not be the most cost-effective choice:
- Proof of Concept and Minimum Viable Product stages: during the early phases of development, using CPUs can help reduce costs while still enabling effective testing and iteration;
- Projects with relaxed response time requirements: in cases where real-time processing is not critical, CPUs can suffice for production, at least temporarily.
- Small models that don’t take up a lot of memory: such models can work even faster using CPU.
While GPUs are significantly faster than CPUs, their computational cost may exceed the speed benefits in certain contexts. If you’re working on a tight budget, we recommend starting with CPUs for development, testing, and staging. As models mature and demand for processing power increases, transitioning to GPUs becomes a logical next step to scale effectively. However, some models are too large to use CPU, and in this case, it’s required to opt for GPU from the very start.
7 Key Aspects to Consider When Choosing a GPU for Your Machine Learning Project
Before learning how to use GPUs for machine learning, it’s necessary to understand the key aspects to focus on when choosing a GPU. We gathered the main considerations our team uses when evaluating the required infrastructure for our clients’ projects.
1. Computing Power
Computing power, measured in TFLOPS (tera floating-point operations per second), is an important factor when selecting a GPU. Higher TFLOPS indicate greater computational capacity, allowing the GPU to handle more complex tasks efficiently.
For machine learning applications involving deep neural networks like image recognition and natural language processing, GPUs with high computing power significantly reduce training and inference times, providing a substantial performance boost over CPUs.
2. Memory Capacity
Memory capacity, or VRAM, determines the amount of data a GPU can process simultaneously. GPUs like the NVIDIA V100, with 32 GB of VRAM, are good for handling large models and datasets without bottlenecks. Sufficient memory capacity ensures that machine learning models can operate smoothly during both training and inference, particularly when dealing with high-resolution data & large batch sizes.
3. Memory Bandwidth
High memory bandwidth is essential for enabling rapid data transfer between GPU cores and memory. Unlike CPUs, GPUs are optimized for parallel data transfers, allowing them to process vast datasets efficiently. Bandwidths up to 750GB/s can handle complex workloads. These include high-resolution video analysis, real-time simulations, and others without any delays at all.
4. Tensor Cores
Tensor cores, available in modern GPUs like NVIDIA’s Tensor Core architecture, are specifically designed for deep learning operations. They enhance matrix multiplication and other linear algebra tasks fundamental to neural networks.
This is perfect for GPU-accelerated machine learning and inference, reducing latency and improving throughput. Tensor cores are a must-have for CTOs looking to optimize performance in AI-driven projects.
5. Shared Memory
GPUs with larger shared memory improve overall performance, especially in applications requiring high data locality. While GPUs with extensive shared memory may come at a higher cost, they offer a significant advantage in scenarios demanding rapid data access and processing.
6. Interconnection
Interconnection capabilities are required for clustering multiple GPUs to work seamlessly together. Distributed training, which involves splitting large models and datasets across several GPUs, benefits greatly from efficient interconnection. Some GPUs offer great scalability and compatibility, ensuring smooth integration into high-performance computing setups for machine learning.
7. Costs
Cost considerations are also important when choosing a GPU. While enterprise-grade GPUs provide greater performance, they often come at a premium. Balancing budget constraints with performance requirements is vital, especially for businesses scaling AI operations. Additionally, evaluating cloud-based versus on-premises solutions can help optimize costs based on workload demands and resource availability.
GPUs On-Premises vs Cloud GPUs
Choosing between on-premises and cloud GPUs involves several major considerations, especially for organizations scaling AI and ML operations. Each option offers distinct advantages and trade-offs, which should be weighed based on your project’s needs.
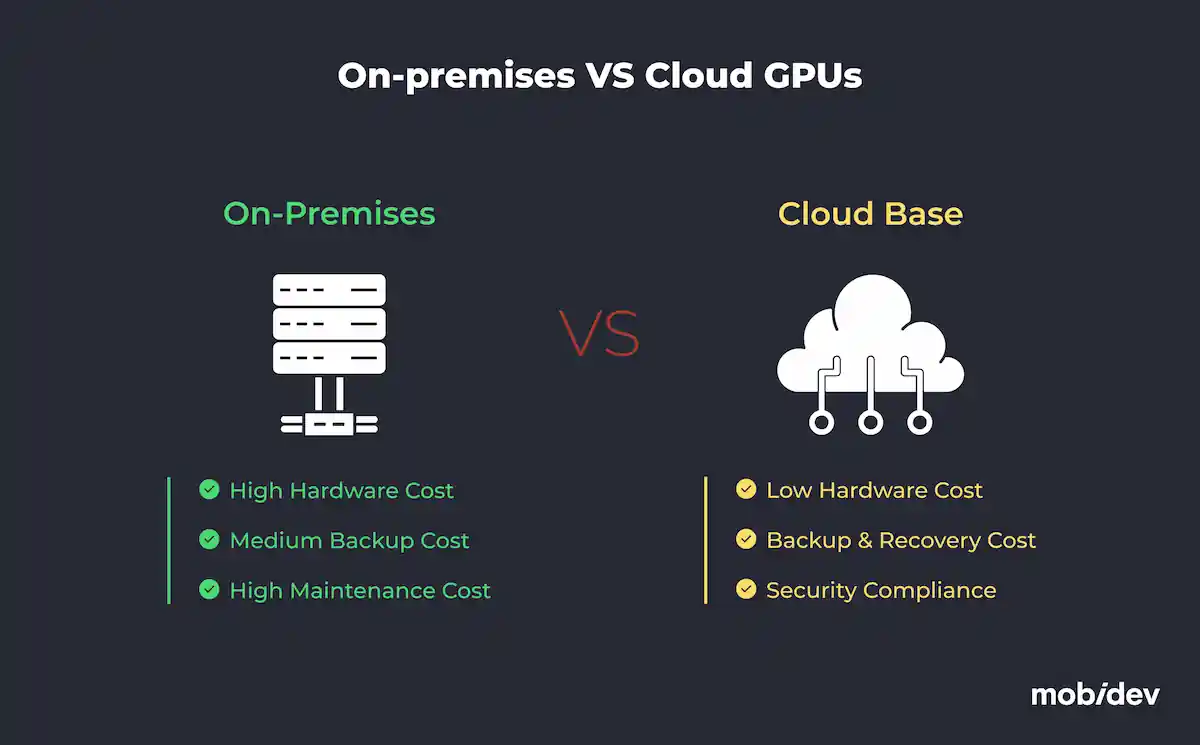
On-Premises GPUs
On-premises GPUs are suitable for projects that prioritize data security with predictable and long-term GPU usage. Industries with such requirements could include healthcare, finance, and any others that work with sensitive information and are subject to strict regulations.
The two options you’ll typically have are:
- NVIDIA: popular for its CUDA toolkit, supporting advanced deep learning frameworks like TensorFlow and PyTorch. NVIDIA’s Tesla GPUs are highly reliable but come at a premium cost.
- AMD: cost-effective alternatives with ROCm libraries, though they have less community and software support compared to NVIDIA.
Let’s see the general pros and cons of using on-premises GPUs in your project.
| # | Advantages | Disadvantages |
|---|---|---|
| 1 | Long-term cost savings with frequent GPU usage | High upfront costs for hardware acquisition and setup |
| 2 | Full control over infrastructure, ensuring sensitive data remains on-site | Maintenance requires skilled personnel |
| 3 | Customization options to tailor hardware configurations for specific tasks | Scaling resources is time-consuming and expensive |
Cloud GPUs
Cloud GPU services like AWS, Azure, and Google Cloud provide scalable pay-as-you-go solutions, making them the perfect match for businesses requiring flexibility. If you’re not subject to tight regulations and security isn’t your number one priority on the list, this is the most budget-friendly solution.
These are the biggest cloud GPU providers in the industry:
- AWS: offers scalable EC2 instances with options like P3 and G4, ideal for diverse ML workloads
- Azure: features NC, ND, and NV series optimized for heavy computation and virtual desktop infrastructure
- Google Cloud: supports GPU attachment for existing instances and offers Tensor Processing Units for cost-effective and high-performance AI tasks
Let’s look at the general pros and cons of using cloud-based GPUs in your project.
| # | Advantages | Disadvantages |
|---|---|---|
| 1 | Rapid scalability to meet changing project demands | Recurring costs can accumulate for long-term usage |
| 2 | No upfront hardware costs; pay-as-you-go pricing | Data transfer bottlenecks may occur with large datasets |
| 3 | Globally accessible infrastructure facilitates team collaboration | Dependency on service providers for uptime and availability |
Using GPU for AI training in MobiDev experience
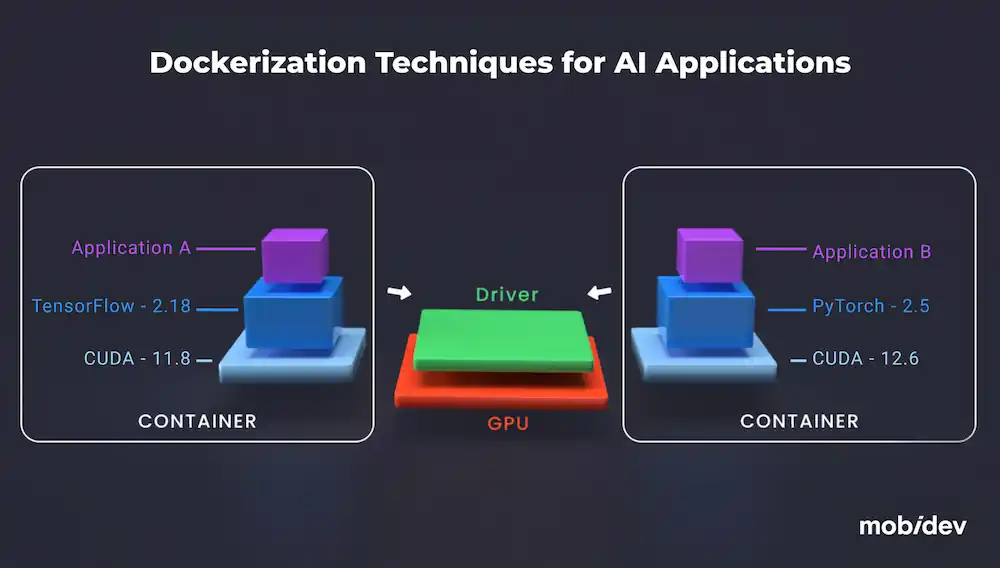
MobiDev’s engineers use powerful NVIDIA GPUs for AI training and research through our internal computation service. This service combines high-performance hardware with Dockerization techniques to manage AI frameworks and dependencies efficiently.
Considering possible compatibility issues, we used the following mitigation strategies:
- Using Docker & NVIDIA-docker to containerize AI applications with specific versions of TensorFlow, PyTorch, and CUDA
- Maintaining multiple versions of AI frameworks and CUDA drivers on shared hardware without conflicts
As a result, we can scale development, ensure compatibility, and accelerate deployment across projects. What’s in it for you? Your product will get everything it needs for success.
Build an Effective Architecture for Your AI Product with MobiDev
MobiDev’s engineers have been providing clients with high-quality software solutions since 2009 and supporting them with specialized AI solutions since 2018. We can help you integrate pre-trained models into your systems or create custom solutions tailored to your specific needs. You can also benefit from our:
- In-house AI labs involved in research and development of complex AI solutions
- AI consulting and engineering services designed to meet your specific needs
- Transparency and communication throughout the whole process
Our experience in building efficient architectures for AI products of different complexities allows us to solve any challenge. Get in touch with our team today to get a detailed estimate and launch your AI product. It’s time to bring your vision to life!


